Partager la publication "Anakeyn TF-IDF Keywords Suggest"
Anakeyn TF-IDF Keywords Suggest est un outil de suggestion de mots clés pour le SEO et le Web Marketing.
Cet outil récupère les x premières pages Web répondant à une requête dans Google.
Ensuite, le système va récupérer le contenu des pages afin de trouver des mots clés populaires ou originaux en rapport avec le sujet recherché. Le système fonctionne avec un algorithme TF-IDF.
TF-IDF veut dire term frequency–inverse document frequency en anglais. C’est une mesure statistique qui permet de déterminer l’importance d’un mot ou d’une expression dans un document relativement à un corpus ou une collection de documents.
Dans notre cas un document est une page Web et le corpus est l’ensemble des pages Web récupérées.
Nous avions déjà abordé le concept de TF-IDF dans un article précédent sur le Machine Learning. La formule est la suivante :
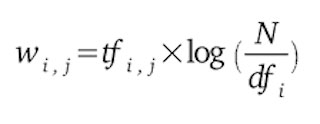
Où :
| : nombre d’occurrences de i dans j. | |
| : nombre de documents contenant i | |
| N | : nombre total de documents |
Comme ici nous avons besoin d’indicateurs « généraux » pour les expressions trouvées, nous calculons la moyenne des TF-IDF pour chaque expression pour trouver les plus populaires, et la moyenne des TF-IDF non nulles pour chaque expression pour déterminer les plus originales.
L’ensemble des codes sources et des données de cette version compatible Windows sont disponibles sur notre GitHub à l’adresse https://github.com/Anakeyn/TFIDFKeywordsSuggest
Technologie utilisée
L’application est développée en Python (pour nous Python Anaconda 3.7) au format Web.
Pour le format Web nous utilisons Flask :
Flask est un cadre de travail (framework) Web pour Python. Ainsi, il fournit des fonctionnalités permettant de construire des applications Web, ce qui inclut la gestion des requêtes HTTP et des canevas de présentation ou templates. Flask a été créé initialement par Armin Ronacher
Flask fonctionne notamment avec le moteur de templates Jinja créé par le même auteur et que nous utilisons dans ce projet.
Pour la gestion de la base de données nous utilisons SQLAlchemy. SQLAlchemy est un ORM (Object Relationnel Model, Modèle Relationnel Objet) qui permet de stocker les données des objets Python dans une représentation de type base de données sans se préoccuper des détails liés à la base.
SQLAlchemy est compatible avec PostgreSQL, MySQL, Oracle, Microsoft SQL Server… Pour l’instant nous l’utilisons avec SQLite qui est fournie par défaut avec Python.
Structure de l’application
l’application est structurée de la façon suivante :
KeywordsSuggest | database.db | favicon.ico | tfidfkeywordssuggest.py | license.txt | myconfig.py | requirements.txt | __init__.py | +---configdata | tldLang.xlsx | user_agents-taglang.txt | +---static | Anakeyn_Rectangle.jpg | tfidfkeywordssuggest.css | Oeil_Anakeyn.jpg | signin.css | starter-template.css | +---templates | index.html | tfidfkeywordssuggest.html | login.html | signup.html | +---uploads
Fichiers à la racine :
- database.db : base de données SQLite créée automatiquement lors de la première utilisation.
- favicon.ico : favicon anakeyn.
- tfidfkeywordssuggest.py : programme principal (celui à faire tourner).
- license.txt : texte de la licence GPL 3.
- myconfig.py : programme contenant les paramètres de configuration de départ et notamment le type et le nom de la base de données ainsi que les 2 utilisateurs par défaut : admin (mot de passe « adminpwd ») et guest (mot de passe « guestpwd »)
- requirements.txt : liste des bibliothèque Python à installer.
- __init__.py : marque ce dossier comme un package importable.
Répertoire configdata : il contient 2 fichiers de configuration :
- tldlang.xlsx : paramètres pour les domaines de premier niveau des différents sites Google (en anglais Top Level Domain exemple : .com, .fr, .co.uk …) et les langues de résultats souhaitées. Il y a 358 combinaisons de domaines de premier niveau / langues, ce qui permet de rechercher des mots clés dans de nombreuses langues et de nombreux pays.
- user_agents-taglang.txt : une liste d’agents utilisateurs ou user agents (par exemple un navigateur Web) valides. Ces agents sont utilisés de façon aléatoire afin d’éviter d’être reconnu par Google trop rapidement et d’être bloqué. Un tag « {{taglang}} » (au format Jinja) permet au programme de paramétrer la langue cible dans l’agent utilisateur.
Le répertoire static contient les images et les fichiers .css (feuilles de style en cascade en angais Cascading Style Sheets) de l’application Web.
le répertoire templates contient les pages html au format Jinja
le répertoires uploads sert à enregistrer les fichiers de mots clés trouvés. Un sous répertoire est créé pour chaque utilisateur.
Pour chaque interrogation, le système crée 7 fichiers de mots clés/expression « populaires » : 1 avec des tailles indéterminées entre 1 à 6 mots et 1 pour chaque taille en nombre de mots : 1, 2, 3, 4, 5 ou 6 mots. DE la même façon, il crée 7 fichiers pour les mots clés « originaux ». Si l’ensemble du corpus de documents est suffisamment grand, le système propose jusqu’à 10.000 mots clés par fichier !
Testez le programme sur votre ordinateur
- Téléchargez le fichier .zip de l’application sur notre GitHub : https://github.com/Anakeyn/TFIDFKeywordsSuggest/archive/master.zip et dézipper-le dans un répertoire de votre choix.
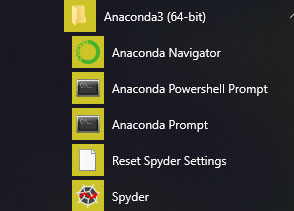
- Téléchargez et installez Python Anaconda https://www.anaconda.com/distribution/#download-section
- Anaconda installe plusieurs outils sur votre ordinateur :
- Ouvrez Anaconda Prompt et allez dans le répertoire ou vous avez préalablement installé l’application. Par exemple sous Windows : « >cd c:Users\myname\documents\…\… »
- Vérifiez que le fichier « requirements.txt » est bien dans votre répertoire : dir (Windows), ls (Linux). Ce fichier contient la liste des bibliothèques (ou dépendances) à installer au préalable pour faire fonctionner notre application.
- Pour les installer sous Linux tapez la commande suivante :
while read requirement; do conda install --yes $requirement || pip install $requirement; done < requirements.txt
- Pour les installer sous Windows tapez la commande suivante :
FOR /F "delims=~" %f in (requirements.txt) DO conda install --yes "%f" || pip install "%f"
Attention !!! la mise en place des dépendances peut durer un certain temps : soyez patient !! Cette opération n’est à faire qu’une seule fois.
- Ensuite lancez Spyder et ouvrez le fichier Python Principal tfidfkeywordssuggest.py
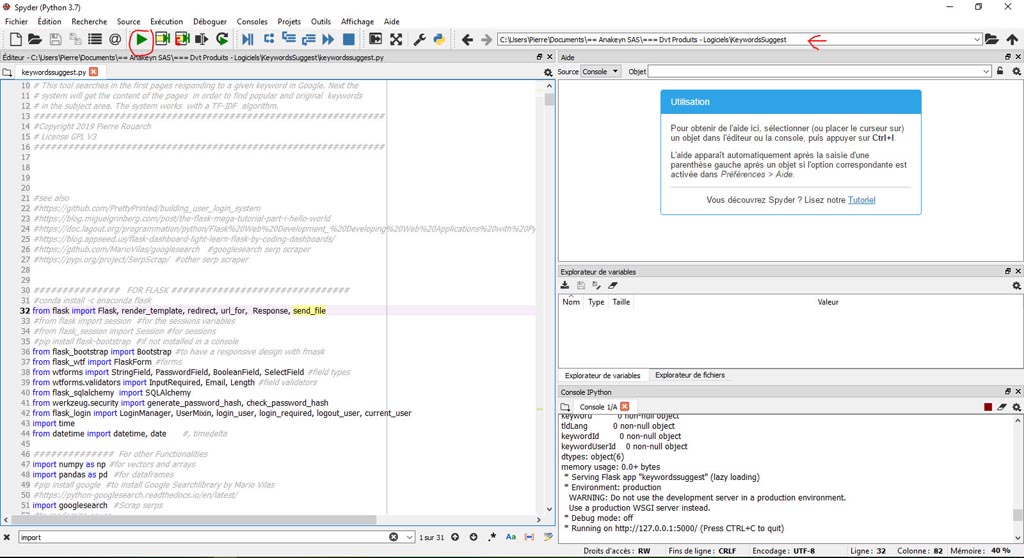
- Vérifiez que vous êtes dans le bon répertoire (celui de votre fichier python) et cliquez sur la flèche verte pour lancer le fichier Python
- Ensuite, ouvrez un navigateur et allez à l’adresse http://127.0.0.1:5000. Il s’agit de l’adresse par défaut de l’application sur votre ordinateur.
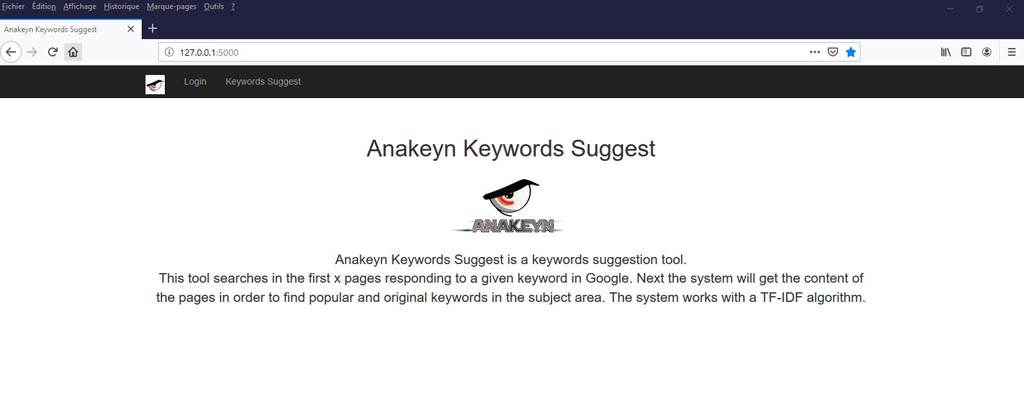
- Cliquez sur « TF-IDF Keywords Suggest » : le système est protégé par identifiant et mot de passe. Par défaut pour l’administrateur : admin, adminpwd et pour l’invité : guest, guestpwd.
- Ensuite choisissez un mot clé ou une expression et le couple pays/langue ciblé :
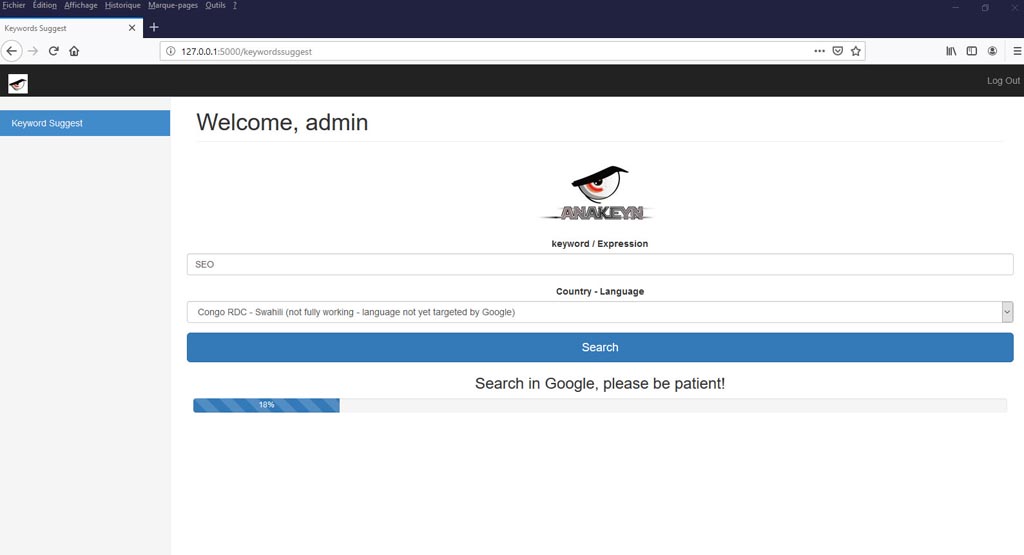
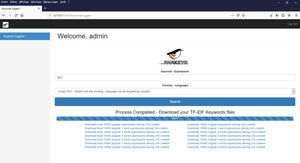
- Le système va rechercher dans Google les x (à déterminer dans le fichier de configuration) premières pages répondant au mot clé recherché, les sauvegarder, récupérer les contenus et calculer un TF-IDF pour chaque terme trouvé dans les pages. Ensuite il fournira 14 fichiers de résultats avec jusqu’à 10.000 expressions populaires ou originales.
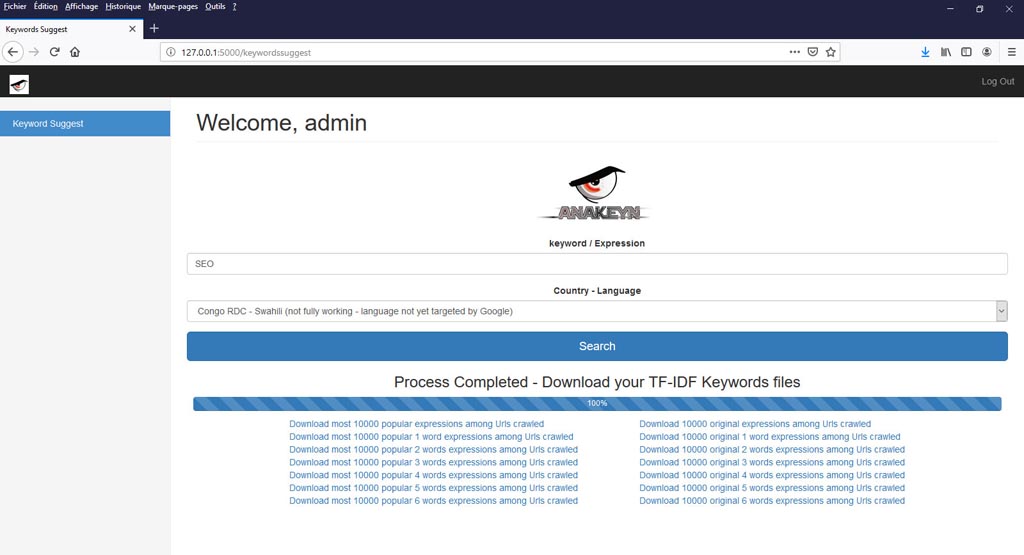
- Comme vous pouvez le voir, toutes les langues ne sont pas filtrées par Google. Voir la liste pour le paramètre « lr » sur cette page https://developers.google.com/custom-search/docs/xml_results_appendices#lrsp . Toutefois avec le filtre de pays et la langue indiquée dans le user agent on obtient souvent des résultats satisfaisants.
- Par exemple, ci dessous le début du fichier des résultats de la recherche pour « SEO », contenant les expressions originales de 2 mots clés et ciblés en Swahili pour la République Démocratique du Congo :
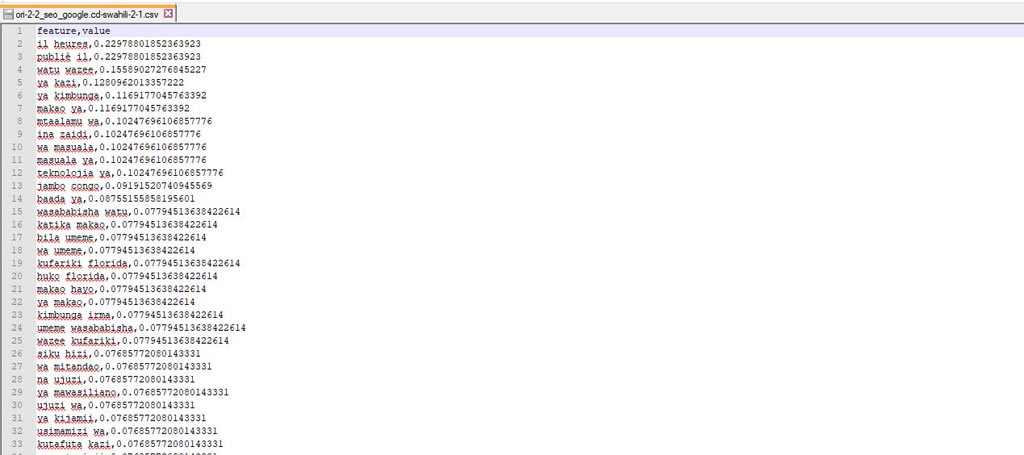
Code Source
nous présenterons ici les codes sources en Python myconfig.py et tfidfkeywordssuggest.py ainsi que la template tfidfkeywordssuggest.html.
Vous pouvez copier/coller les codes sources suivants un à un ou bien télécharger l’ensemble gratuitement depuis notre boutique, pour être sûr d’avoir la dernière version, à l’adresse : https://www.anakeyn.com/boutique/produit/script-python-tf-idf-keywords-suggest/
myconfig.py : paramètres généraux de l’application
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 16 15:41:05 2019
@author: Pierre
"""
import pandas as pd #for dataframes
#Define your database
myDatabaseURI = "sqlite:///database.db"
#define the default upload/dowload parent directory
UPLOAD_SUBDIRECTORY = "/uploads"
#define an admin and a guest
#change if needed.
myAdminLogin = "admin"
myAdminPwd = "adminpwd"
myAdminEmail = "admin@example.com"
myGuestLogin = "guest"
myGuestPwd = "guestpwd"
myGuestEmail = "guest@example.com"
#define Google TLD and languages and stopWords
#see https://developers.google.com/custom-search/docs/xml_results_appendices
#https://www.metamodpro.com/browser-language-codes
#Languages
dfTLDLanguages = pd.read_excel('configdata/tldLang.xlsx')
dfTLDLanguages.fillna('',inplace=True)
if len(dfTLDLanguages) == 0 :
#if 1==1 :
data = [['google.com', 'United States', 'com', 'en', 'lang_en', 'countryUS', 'en-us', 'english', 'United States', 'en - English'],
['google.co.uk', 'United Kingdom', 'co.uk', 'en', 'lang_en', 'countryUK', 'en-uk', 'english', 'United Kingdom', 'en - English'],
['google.de', 'Germany', 'de','de', 'lang_de', 'countryDE', 'de-de', 'german', 'Germany', 'de - German'],
['google.fr', 'France', 'fr', 'fr', 'lang_fr', 'countryFR', 'fr-fr', 'french', 'France', 'fr - French']]
dfTLDLanguages = pd.DataFrame(data, columns = ['tldLang', 'description', 'tld', 'hl', 'lr', 'cr', 'userAgentLanguage', 'stopWords', 'countryName', 'ISOLanguage' ])
myTLDLang = [tuple(r) for r in dfTLDLanguages[['tldLang', 'description']].values]
#print(myTLDLang)
dfTLDLanguages = dfTLDLanguages.drop_duplicates()
dfTLDLanguages.set_index('tldLang', inplace=True)
dfTLDLanguages.info()
#dfTLDLanguages['userAgentLanguage']
#USER AGENTS
with open('configdata/user_agents-taglang.txt') as f:
userAgentsList = f.read().splitlines()
#pauses to scrap Google
myLowPause=2
myHighPause=6
#define max pages to scrap on Google (30 is enough 100 max)
myMaxPagesToScrap=30
#define refresh delay (usually 30 days)
myRefreshDelay = 30
myMaxFeatures = 10000 #to calculate tf-idf
#Name of account type
myAccountTypeName=['Admin', 'Gold', 'Silver','Bronze', 'Guest',]
#max number of results to keep in TF-IDF depending on role
myMaxResults=[10000, 10000, 5000, 1000, 100]
#max searches by day depending on role
myMaxSearchesByDay=[10000, 10000, 1000, 100, 10]
#min ngram
myMinNGram=1 #Not a good idea to change this for the moment
#max ngram
myMaxNGram=6 ##Not a good idea to change this for the moment
#CSV separator
myCsvSep = ","
Paramètres importants :
- myDatabaseURI : vous pouvez modifier cette variable si vous souhaitez une base de données mySQL (mysql://scott:tiger@localhost/mydatabase) ou bien Postgres (postgresql://scott:tiger@localhost/mydatabase)
- myAdminLogin, myAdminPwd … si vous souhaitez modifier les identifiants/mots de passe des utilisateurs. (une gestion des utilisateurs est prévue dans le futur)
- myRefreshDelay : délai entre 2 lectures sur Google. Nous avons pris 30 jours car souvent les sources alternatives de positions comme par exemple Yooda Insight ou SEMrush sont mis à jour mensuellement. Rem: comme nous prévoyons d’utiliser leurs APIs dans le futur on aura ainsi un délai cohérent entre les différentes sources. Cela permet aussi d’être plus rapide et d’éviter de la consultation Google pour rien.
- myCsvSep : par défaut nous avons mis une « , » comme séparateur pour les fichiers de résultats. Mais si vous avez une version française d’Excel vous pouvez choisir « ; » pour pouvoir ouvrir ces fichiers.
TFIDFkeywordssuggest.py : programme principal
Ici, nous allons diviser le code source en plusieurs morceaux pour le présenter.
Chargement des bibliothèques utiles
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 16 15:41:05 2019
@author: Pierre
"""
#############################################################
# Anakeyn Keywords Suggest version Alpha 0.0
# Anakeyn Keywords Suggest is a keywords suggestion tool.
# This tool searches in the first pages responding to a given keyword in Google. Next the
# system will get the content of the pages in order to find popular and original keywords
# in the subject area. The system works with a TF-IDF algorithm.
#############################################################
#Copyright 2019 Pierre Rouarch
# License GPL V3
#############################################################
#see also
#https://github.com/PrettyPrinted/building_user_login_system
#https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-i-hello-world
#https://github.com/MarioVilas/googlesearch #googlesearch serp scraper
############### FOR FLASK ###############################
#conda install -c anaconda flask
from flask import Flask, render_template, redirect, url_for, Response, send_file
#from flask import session #for the sessions variables
#from flask_session import Session #for sessions
#pip install flask-bootstrap #if not installed in a console
from flask_bootstrap import Bootstrap #to have a responsive design with fmask
from flask_wtf import FlaskForm #forms
from wtforms import StringField, PasswordField, BooleanField, SelectField #field types
from wtforms.validators import InputRequired, Email, Length #field validators
from flask_sqlalchemy import SQLAlchemy
from werkzeug.security import generate_password_hash, check_password_hash
from flask_login import LoginManager, UserMixin, login_user, login_required, logout_user, current_user
import time
from datetime import datetime, date #, timedelta
############## For other Functionalities
import numpy as np #for vectors and arrays
import pandas as pd #for dataframes
#pip install google #to install Google Searchlibrary by Mario Vilas
#https://python-googlesearch.readthedocs.io/en/latest/
import googlesearch #Scrap serps
#to randomize pause
import random
#
import nltk # for text mining
from nltk.corpus import stopwords
nltk.download('stopwords') #for stopwords
#print (stopwords.fileids())
#TF-IDF function
from sklearn.feature_extraction.text import TfidfVectorizer
import requests #to read urls contents
from bs4 import BeautifulSoup
from bs4.element import Comment
import re #for regex
import unicodedata #to decode accents
import os #for directories
import sys #for sys variables
J’en profite ici pour remercier Anthony Herbert et Miguel Grimberg pour leurs excellents tutoriels sur Flask, ainsi que Mario Vilas pour son scraper de pages Google, très facile à mettre en oeuvre.
Initialisation de Flask
##### Flask Environment
# Returns the directory the current script (or interpreter) is running in
def get_script_directory():
path = os.path.realpath(sys.argv[0])
if os.path.isdir(path):
return path
else:
return os.path.dirname(path)
myScriptDirectory = get_script_directory()
#############################################################
# In a myconfig.py file, think to define the database server name
#############################################################
import myconfig #my configuration : edit this if needed
#print(myconfig.myDatabaseURI )
myDirectory =myScriptDirectory+myconfig.UPLOAD_SUBDIRECTORY
if not os.path.exists(myDirectory ):
os.makedirs(myDirectory )
app = Flask(__name__) #flask application
app.config['SECRET_KEY'] = 'Thisissupposedtobesecret!' #what you want
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False #avoid a warning
app.config['SQLALCHEMY_DATABASE_URI'] =myconfig.myDatabaseURI #database choice
bootstrap = Bootstrap(app) #for bootstrap compatiblity
Création de la base de données, des tables et des répertoires nécessaires.
############# #########################
# Database and Tables
#######################################
db = SQLAlchemy(app) #the current database attached to the app.
#users
class User(UserMixin, db.Model):
__tablename__="user"
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(15), unique=True)
email = db.Column(db.String(50), unique=True)
password = db.Column(db.String(80))
role = db.Column(db.Integer)
def __init__(self, username, email, password, role):
self.username = username
self.email = email
self.password = password
self.role = role
#Global Queries / Expressions / Keywords searches
class Keyword(db.Model):
__tablename__="keyword"
id = db.Column(db.Integer, primary_key=True)
keyword = db.Column(db.String(200))
tldLang = db.Column(db.String(50)) #google tld + lang
data_date = db.Column(db.Date, nullable=False, default=datetime.date) #date of the last data update
search_date = db.Column(db.Date, nullable=False, default=datetime.date) #date of the last search asks
def __init__(self, keyword , tldLang, data_date, search_date):
self.keyword = keyword
self.tldLang = tldLang
self.data_date = data_date
self.search_date = search_date
#Queries / Expressions / Keywords searches by username
class KeywordUser(db.Model):
__tablename__="keyworduser"
id = db.Column(db.Integer, primary_key=True)
keywordId = db.Column(db.Integer) #id in the keyword Table
keyword = db.Column(db.String(200))
tldLang = db.Column(db.String(50)) #google tld + lang
username = db.Column(db.String(15)) #
data_date = db.Column(db.Date, nullable=False, default=datetime.date) #date of the last data update
search_date = db.Column(db.Date, nullable=False, default=datetime.date) #date of the last search asks
def __init__(self, keywordId, keyword , tldLang, username, data_date , search_date):
self.keywordId = keywordId
self.keyword = keyword
self.tldLang = tldLang
self.username = username
self.data_date = data_date
self.search_date = search_date
#Positions
class Position(db.Model):
__tablename__="position"
id = db.Column(db.Integer, primary_key=True)
keyword = db.Column(db.String(200))
tldLang = db.Column(db.String(50)) #google tld + lang
page = db.Column(db.String(300))
position = db.Column(db.Integer)
source= db.Column(db.String(20))
search_date = db.Column(db.Date, nullable=False, default=datetime.date)
def __init__(self, keyword , tldLang, page, position, source, search_date):
self.keyword = keyword
self.tldLang = tldLang
self.page = page
self.position = position
self.source = source
self.search_date = search_date
#Page content
class Page(db.Model):
__tablename__="page"
id = db.Column(db.Integer, primary_key=True)
page = db.Column(db.String(300))
statusCode= db.Column(db.Integer)
html= db.Column(db.Text)
encoding = db.Column(db.String(20))
elapsedTime = db.Column(db.Float) #could be interesting for future purpose.
body= db.Column(db.Text)
search_date = db.Column(db.Date, nullable=False, default=datetime.date)
def __init__(self, page , statusCode, html, encoding, elapsedTime, body, search_date):
self.page = page
self.statusCode = statusCode
self.html = html
self.encoding = encoding
self.elapsedTime = elapsedTime
self.body = body
self.search_date = search_date
##############
db.create_all() #create database and tables if not exist
db.session.commit() #execute previous instruction
#Create an admin if not exists
exists = db.session.query(
db.session.query(User).filter_by(username=myconfig.myAdminLogin).exists()
).scalar()
if not exists :
hashed_password = generate_password_hash(myconfig.myAdminPwd, method='sha256')
administrator = User(myconfig.myAdminLogin, myconfig.myAdminEmail, hashed_password, 0)
db.session.add(administrator)
db.session.commit() #execute
#####
#create upload/dowload directory for admin
myDirectory = myScriptDirectory+myconfig.UPLOAD_SUBDIRECTORY+"/"+myconfig.myAdminLogin
if not os.path.exists(myDirectory):
os.makedirs(myDirectory)
#Create a guest if not exists
exists = db.session.query(
db.session.query(User).filter_by(username=myconfig.myGuestLogin).exists()
).scalar()
if not exists :
hashed_password = generate_password_hash(myconfig.myGuestPwd, method='sha256')
guest = User(myconfig.myGuestLogin, myconfig.myGuestEmail, hashed_password, 4)
db.session.add(guest)
db.session.commit() #execute
#####
#create upload/dowload directory for guest
myDirectory = myScriptDirectory+myconfig.UPLOAD_SUBDIRECTORY+"/"+myconfig.myGuestLogin
if not os.path.exists(myDirectory):
os.makedirs(myDirectory)
#init login_manager
login_manager = LoginManager()
login_manager.init_app(app)
login_manager.login_view = 'login'
Autres initialisations et FONCTIONS UTILES
#######################################################
#Save session data in a global DataFrame depending on user_id
global dfSession
dfSession = pd.DataFrame(columns=['user_id', 'userName', 'role', 'keyword', 'tldLang', 'keywordId', 'keywordUserId'])
dfSession.set_index('user_id', inplace=True)
dfSession.info()
#for tfidf counts
def top_tfidf_feats(row, features, top_n=25):
''' Get top n tfidf values in row and return them with their corresponding feature names.'''
topn_ids = np.argsort(row)[::-1][:top_n]
top_feats = [(features[i], row[i]) for i in topn_ids]
df = pd.DataFrame(top_feats)
df.columns = ['feature', 'value']
return df
def top_mean_feats(Xtr, features, grp_ids=None, top_n=25):
''' Return the top n features that on average are most important amongst documents in rows
indentified by indices in grp_ids. '''
if grp_ids:
D = Xtr[grp_ids].toarray()
else:
D = Xtr.toarray()
#D[D < min_tfidf] = 0 #keep all values
tfidf_means = np.mean(D, axis=0)
return top_tfidf_feats(tfidf_means, features, top_n)
#Best for original Keywords
def top_nonzero_mean_feats(Xtr, features, grp_ids=None, top_n=25):
''' Return the top n features that on nonzero average are most important amongst documents in rows
indentified by indices in grp_ids. '''
if grp_ids:
D = Xtr[grp_ids].toarray()
else:
D = Xtr.toarray()
#D[D < min_tfidf] = 0
tfidf_nonzero_means = np.nanmean(np.where(D!=0,D,np.nan), axis=0) #change 0 in NaN
return top_tfidf_feats(tfidf_nonzero_means, features, top_n)
@login_manager.user_loader
def load_user(user_id):
return User.query.get(int(user_id))
#Forms
class LoginForm(FlaskForm):
username = StringField('username', validators=[InputRequired(), Length(min=4, max=15)])
password = PasswordField('password', validators=[InputRequired(), Length(min=8, max=80)])
remember = BooleanField('remember me')
#we don't use this for the moment
class RegisterForm(FlaskForm):
email = StringField('email', validators=[InputRequired(), Email(message='Invalid email'), Length(max=50)])
username = StringField('username', validators=[InputRequired(), Length(min=4, max=15)])
password = PasswordField('password', validators=[InputRequired(), Length(min=8, max=80)])
role = 4
#search keywords by keyword
class SearchForm(FlaskForm):
myTLDLang = myconfig.myTLDLang
keyword = StringField('keyword / Expression', validators=[InputRequired(), Length(max=200)])
tldLang = SelectField('Country - Language', choices=myTLDLang, validators=[InputRequired()])
############### other functions
#####Get strings from tags
def getStringfromTag(tag="h1", soup="") :
theTag = soup.find_all(tag)
myTag = ""
for x in theTag:
myTag= myTag + " " + x.text.strip()
return myTag.strip()
#remove comments and non visible tags
def tag_visible(element):
if element.parent.name in ['style', 'script', 'head', 'title', 'meta', '[document]']:
return False
if isinstance(element, Comment):
return False
return True
def strip_accents(text, encoding='utf-8'):
"""
Strip accents from input String.
:param text: The input string.
:type text: String.
:returns: The processed String.
:rtype: String.
"""
text = unicodedata.normalize('NFD', text)
text = text.encode('ascii', 'ignore')
text = text.decode(encoding)
return str(text)
# Get a random user agent.
def getRandomUserAgent(userAgentsList, userAgentLanguage):
theUserAgent = random.choice(userAgentsList)
if len(userAgentLanguage) > 0 :
theUserAgent = theUserAgent.replace("{{tagLang}}","; "+str(userAgentLanguage))
else :
theUserAgent = theUserAgent.replace("{{tagLang}}",""+str(userAgentLanguage))
return theUserAgent
#ngrams in list
def words_to_ngrams(words, n, sep=" "):
return [sep.join(words[i:i+n]) for i in range(len(words)-n+1)]
#one-gram tokenizer
tokenizer = nltk.RegexpTokenizer(r'\w+')
Routes de base
#################### WebSite ##################################
#Routes
@app.route('/')
def index():
return render_template('index.html')
@app.route('/login', methods=['GET', 'POST'])
def login():
form = LoginForm()
if form.validate_on_submit():
user = User.query.filter_by(username=form.username.data).first()
if user:
if check_password_hash(user.password, form.password.data):
login_user(user, remember=form.remember.data)
return redirect(url_for('keywordssuggest')) #go to the keywords Suggest page
return '<h1>Invalid password</h1>'
return '<h1>Invalid username</h1>'
#return '<h1>' + form.username.data + ' ' + form.password.data + '</h1>'
return render_template('login.html', form=form)
#Not used here.
@app.route('/signup', methods=['GET', 'POST'])
def signup():
form = RegisterForm()
if form.validate_on_submit():
hashed_password = generate_password_hash(form.password.data, method='sha256')
new_user = User(username=form.username.data, email=form.email.data, password=hashed_password)
db.session.add(new_user)
db.session.commit()
return '<h1>New user has been created!</h1>'
#return '<h1>' + form.username.data + ' ' + form.email.data + ' ' + form.password.data + '</h1>'
return render_template('signup.html', form=form)
#Not used here.
@app.route('/dashboard')
@login_required
def dashboard():
return render_template('dashboard.html', name=current_user.username)
@app.route('/logout')
@login_required
def logout():
logout_user()
return redirect(url_for('index'))
Ici la page d’inscription et la page de dashboard global ne sont pas utilisées pour l’instant.
Remarque : Flask utilise le concept de « route« . En développement Web, on appelle route une URL ou un ensemble d’URLs conduisant à l’exécution d’une fonction donnée.
Dans Flask, les routes sont déclarées via le décorateur app.route
Route TFIDFkeywordsuggest : saisie de l’expression et du pays/langue
#Route TFIDFkeywordssuggest
@app.route('/tfidfkeywordssuggest',methods=['GET', 'POST'])
@login_required
def tfidfkeywordssuggest():
print("tfidfkeywordssuggest")
#print("g.userId="+str(g.userId))
if current_user.is_authenticated: #always because @login_required
print("UserId= "+str(current_user.get_id()))
myUserId = current_user.get_id()
print("UserName = "+current_user.username)
dfSession.loc[ myUserId, 'userName'] = current_user.username #Save Username for userId
#make sure we have a good Role
if current_user.role is None or current_user.role > 4 or current_user.role <0 :
dfSession.loc[ myUserId,'role'] = 4 #4 is for guest
else :
dfSession.loc[ myUserId,'role'] = current_user.role
myRole = dfSession.loc[ myUserId,'role']
#count searches in a day
myLimitReached = False
mySearchesCount = db.session.query(KeywordUser).filter_by(username=current_user.username, search_date=date.today()).count()
print("mySearchesCount="+str(mySearchesCount))
print(" myconfig.myMaxSearchesByDay[myRole]="+str(myconfig.myMaxSearchesByDay[myRole]))
if (mySearchesCount >= myconfig.myMaxSearchesByDay[myRole]):
myLimitReached=True
#raz value
dfSession.loc[myUserId,'keyword'] = ""
dfSession.loc[myUserId,'tldLang'] =""
form = SearchForm()
if form.validate_on_submit():
dfSession.loc[myUserId,'keyword'] = form.keyword.data #save in session variable
dfSession.loc[myUserId,'tldLang'] = form.tldLang.data #save in session variable
dfSession.head()
return render_template('tfidfkeywordssuggest.html', name=current_user.username, form=form,
keyword = form.keyword.data , tldLang = form.tldLang.data,
role =myRole, MaxResults=myconfig.myMaxResults[myRole], limitReached=myLimitReached)
Cette route gère le formulaire de saisie, elle vérifie aussi si vous avez les droits pour faire une recherche.
Route PROGRESS
La route « progress » effectue les recherches à proprement parlé. Elle dialogue aussi avec le client (la page keywordssuggest.html) en envoyant des informations à celui-ci via la fonction generate qui est appelée en boucle.
Cette partie étant relativement longue nous la traiterons en plusieurs étapes.
Initialisation et récupération des données de session
@app.route('/progress')
def progress():
print("progress")
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
dfScrap = pd.DataFrame(columns=['keyword', 'tldLang', 'page', 'position', 'source', 'search_date'])
def generate(dfScrap, myUserId ):
myUserName=dfSession.loc[ myUserId,'userName']
myRole = dfSession.loc[ myUserId,'role']
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
print("myUserId : "+myUserId)
print("myUserName : "+myUserName)
print("myRole : "+str(myRole))
print("myKeyword : "+myKeyword)
print("myTLDLang : "+myTLDLang)
print("myKeywordId : "+str(myKeywordId))
mySearchesCount = db.session.query(KeywordUser).filter_by(username=myUserName, search_date=date.today()).count()
print("mySearchesCount="+str(mySearchesCount))
print(" myconfig.myMaxSearchesByDay[myRole]="+str(myconfig.myMaxSearchesByDay[myRole]))
if (mySearchesCount >= myconfig.myMaxSearchesByDay[myRole] ):
myKeyword=""
myTLDLang=""
myShow=-1 #Error
yield "data:" + str(myShow) + "\n\n" #to show error
Vérification s’il n’y a pas une recherche précédente identique effectuée depuis les 30 derniers jours.
##############################
#run
###############################
if ( len(myKeyword) > 0 and len(myTLDLang) >0) :
myDate=date.today()
print('myDate='+str(myDate))
goSearch=False #do we made a new search in Google ?
#did anybody already made this search during the last x days ????
firstKWC = db.session.query(Keyword).filter_by(keyword=myKeyword, tldLang=myTLDLang).first()
#lastSearchDate = Keyword.query.filter(keyword==myKeyword, tldLang==myTLDLang ).first().format('search_date')
if firstKWC is None:
goSearch=True
else:
myKeywordId=firstKWC.id
dfSession.loc[ myUserId,'keywordId']=myKeywordId #Save in the dfSession
print("last Search Date="+ str(firstKWC.search_date))
Delta = myDate - firstKWC.search_date
print(" Delta in days="+str(Delta.days))
if Delta.days > myconfig.myRefreshDelay : #30 by defaukt
goSearch=True
Scrap dans Google et sauvegarde dans la table des positions de la base de données
###############################################
# Search in Google and scrap Urls
###############################################
if ( len(myKeyword) > 0 and len(myTLDLang) >0 and goSearch) :
#get default language for tld
myTLD = myconfig.dfTLDLanguages.loc[myTLDLang, 'tld']
#myTLD=myTLD.strip()
print("myTLD="+myTLD+"!")
myHl = str(myconfig.dfTLDLanguages.loc[myTLDLang, 'hl'])
#myHl=myHl.strip()
print("myHl="+myHl+"!")
myLanguageResults = str(myconfig.dfTLDLanguages.loc[myTLDLang, 'lr'])
#myLanguageResults=myLanguageResults.strip()
print("myLanguageResults="+myLanguageResults+"!")
myCountryResults = str(myconfig.dfTLDLanguages.loc[myTLDLang, 'cr'])
#myCountryResults=myCountryResults.strip()
print("myCountryResults="+myCountryResults+"!")
myUserAgentLanguage = str(myconfig.dfTLDLanguages.loc[myTLDLang, 'userAgentLanguage'])
#myCountryResults=myCountryResults.strip()
print("myUserAgentLanguage="+myUserAgentLanguage+"!")
###############################
# Google Scrap
###############################
myNum=10
myStart=0
myStop=10 #get by ten
myMaxStart=myconfig.myMaxPagesToScrap #only 3 for test 10 in production
#myTbs= "qdr:m" #rsearch only last month not used
#tbs=myTbs,
#pause may be long to avoir blocking from Google
myLowPause=myconfig.myLowPause
myHighPause=myconfig.myHighPause
nbTrials = 0
#this may be long
while myStart < myMaxStart:
myShow= int(round(((myStart*50)/myMaxStart)+1)) #for the progress bar
yield "data:" + str(myShow) + "\n\n"
print("PASSAGE NUMBER :"+str(myStart))
print("Query:"+myKeyword)
#change user-agent and pause to avoid blocking by Google
myPause = random.randint(myLowPause,myHighPause) #long pause
print("Pause:"+str(myPause))
#change user_agent and provide local language in the User Agent
myUserAgent = getRandomUserAgent(myconfig.userAgentsList, myUserAgentLanguage)
#myUserAgent = googlesearch.get_random_user_agent()
print("UserAgent:"+str(myUserAgent))
df = pd.DataFrame(columns=['query', 'page', 'position', 'source']) #working dataframe
myPause=myPause*(nbTrials+1) #up the pause if trial get nothing
print("Pause:"+str(myPause))
try :
urls = googlesearch.search(query=myKeyword, tld=myTLD, lang=myHl, safe='off',
num=myNum, start=myStart, stop=myStop, domains=None, pause=myPause,
country=myCountryResults, extra_params={'lr': myLanguageResults}, tpe='', user_agent=myUserAgent)
df = pd.DataFrame(columns=['keyword', 'tldLang', 'page', 'position', 'source', 'search_date'])
for url in urls :
print("URL:"+url)
df.loc[df.shape[0],'page'] = url
df['keyword'] = myKeyword #fill with current keyword
df['tldLang'] = myTLDLang #fill with current country / tld lang
df['position'] = df.index.values + 1 + myStart #position = index +1 + myStart
df['source'] = "Scrap" #fill with source origin here scraping Google
#other potentials options : Semrush, Yooda Insight...
df['search_date'] = myDate
dfScrap = pd.concat([dfScrap, df], ignore_index=True) #concat scraps
# time.sleep(myPause) #add another pause
if (df.shape[0] > 0):
nbTrials = 0
myStart += 10
else :
nbTrials +=1
if (nbTrials > 3) :
nbTrials = 0
myStart += 10
#myStop += 10
except :
exc_type, exc_value, exc_traceback = sys.exc_info()
print("GOOGLE ERROR")
print(exc_type.__name__)
print(exc_value)
print(exc_traceback)
time.sleep(600) #add a big pause if you get an error.
#/while myStart < myMaxStart:
#dfScrap.info()
dfScrapUnique=dfScrap.drop_duplicates() #remove duplicates
#dfScrapUnique.info()
#Save in csv an json if needed
#dfScrapUnique.to_csv("dfScrapUnique.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
#dfScrapUnique.to_json("dfScrapUnique.json")
#Bulk save in position table
#save dataframe in table Position
dfScrapUnique.to_sql('position', con=db.engine, if_exists='append', index=False)
myShow=50
yield "data:" + str(myShow) + "\n\n" #to show 50 %
#/end search in Google
Récupération du contenu des pages Web et sauvegarde dans la table des pages.
###############################
# Go to get data from urls
###############################
#read urls to crawl in Position table
dfUrls = pd.read_sql_query(db.session.query(Position).filter_by(keyword= myKeyword, tldLang= myTLDLang).statement, con=db.engine)
dfUrls.info()
###### filter extensions
extensionsToCheck = ('.7z','.aac','.au','.avi','.bmp','.bzip','.css','.doc',
'.docx','.flv','.gif','.gz','.gzip','.ico','.jpg','.jpeg',
'.js','.mov','.mp3','.mp4','.mpeg','.mpg','.odb','.odf',
'.odg','.odp','.ods','.odt','.pdf','.png','.ppt','.pptx',
'.psd','.rar','.swf','.tar','.tgz','.txt','.wav','.wmv',
'.xls','.xlsx','.xml','.z','.zip')
indexGoodFile= dfUrls ['page'].apply(lambda x : not x.endswith(extensionsToCheck) )
dfUrls2=dfUrls.iloc[indexGoodFile.values]
dfUrls2.reset_index(inplace=True, drop=True)
dfUrls2.info()
#######################################################
# Scrap Urls only one time
########################################################
myPagesToScrap = dfUrls2['page'].unique()
dfPagesToScrap= pd.DataFrame(myPagesToScrap, columns=["page"])
#dfPagesToScrap.size #9
#add new variables
dfPagesToScrap['statusCode'] = np.nan
dfPagesToScrap['html'] = '' #
dfPagesToScrap['encoding'] = '' #
dfPagesToScrap['elapsedTime'] = np.nan
myShow=60
yield "data:" + str(myShow) + "\n\n" #to show 60%
stepShow = 10/len(dfPagesToScrap)
print("stepShow scrap urls="+str(stepShow ))
for i in range(0,len(dfPagesToScrap)) :
url = dfPagesToScrap.loc[i, 'page']
print("Page i = "+url+" "+str(i))
startTime = time.time()
try:
#html = urllib.request.urlopen(url).read()$
r = requests.get(url,timeout=(5, 14)) #request
dfPagesToScrap.loc[i,'statusCode'] = r.status_code
print('Status_code '+str(dfPagesToScrap.loc[i,'statusCode']))
if r.status_code == 200. : #can't decode utf-7
print("Encoding="+str(r.encoding))
dfPagesToScrap.loc[i,'encoding'] = r.encoding
if r.encoding == 'UTF-7' : #don't get utf-7 content pb with dbd
dfPagesToScrap.loc[i, 'html'] =""
print("UTF-7 ok page ")
else :
dfPagesToScrap.loc[i, 'html'] = r.text
#au format texte r.text - pas bytes : r.content
print("ok page ")
#print(dfPagesToScrap.loc[i, 'html'] )
except:
print("Error page requests ")
endTime= time.time()
dfPagesToScrap.loc[i, 'elapsedTime'] = endTime - startTime
print('pas scrap URL='+str(round((stepShow*i))))
myShow=60+round((stepShow*i))
yield "data:" + str(myShow) + "\n\n" #to show 60%
#/
dfPagesToScrap.info()
#merge dfUrls2, dfPagesToScrap -> dfUrls3
dfUrls3 = pd.merge(dfUrls2, dfPagesToScrap, on='page', how='left')
#keep only status code = 200
dfUrls3 = dfUrls3.loc[dfUrls3['statusCode'] == 200]
#dfUrls3 = dfUrls3.loc[dfUrls3['encoding'] != 'UTF-7'] #can't save utf-7 content in db ????
dfUrls3 = dfUrls3.loc[dfUrls3['html'] != ""] #don't get empty html
dfUrls3.reset_index(inplace=True, drop=True)
dfUrls3.info() #
dfUrls3 = dfUrls3.dropna() #remove rows with at least one na
dfUrls3.reset_index(inplace=True, drop=True)
dfUrls3.info() #
myShow=70
yield "data:" + str(myShow) + "\n\n" #to show 70%
#Get Body contents from html
dfUrls3['body'] = "" #Empty String
stepShow = 10/len(dfUrls3)
for i in range(0,len(dfUrls3)) :
print("Page keyword tldLang i = "+ dfUrls3.loc[i, 'page']+" "+ dfUrls3.loc[i, 'keyword']+" "+ dfUrls3.loc[i, 'tldLang']+" "+str(i))
encoding = dfUrls3.loc[i, 'encoding'] #get previously
print("get body content encoding"+encoding)
try:
soup = BeautifulSoup( dfUrls3.loc[i, 'html'], 'html.parser')
except :
soup=""
if len(soup) != 0 :
#TBody Content
texts = soup.findAll(text=True)
visible_texts = filter(tag_visible, texts)
myBody = " ".join(t.strip() for t in visible_texts)
myBody=myBody.strip()
#myBody = strip_accents(myBody, encoding).lower() #think to do a global clean instead
myBody=" ".join(myBody.split(" ")) #remove multiple spaces
#print(myBody)
dfUrls3.loc[i, 'body'] = myBody
print('pas body content='+str(round((stepShow*i))))
myShow=70+round((stepShow*i))
yield "data:" + str(myShow) + "\n\n" #to show 70% ++
################################
#save pages in database table page
dfPages= dfUrls3[['page', 'statusCode', 'html', 'encoding', 'elapsedTime', 'body', 'search_date']]
dfPagesUnique = dfPages.drop_duplicates(subset='page') #remove duplicate's pages
dfPagesUnique = dfPagesUnique.dropna() #remove na
dfPagesUnique.reset_index(inplace=True, drop=True) #reset index
#dfPagesUnique.to_sql('page', con=db.engine, if_exists='append', index=False) #duplicate risks !!
#save to see what we get
#dfPagesUnique.to_csv("dfPagesUnique.csv", sep=myconfig.myCsvSep , encoding='utf-8', index=False)
#dfPagesUnique.to_json("dfPagesUnique.json")
myShow=80
yield "data:" + str(myShow) + "\n\n" #to show 90%
#insert or update in Page table
print("len df="+str( len(dfPagesUnique)))
stepShow = 10/len(dfPagesUnique)
for i in range(0, len(dfPagesUnique)) :
print("i="+str(i))
print("page = "+dfPagesUnique.loc[i, 'page'])
dbPage = db.session.query(Page).filter_by(page=dfPagesUnique.loc[i, 'page']).first()
if dbPage is None :
print("nothing insert index = "+str(i))
newPage = Page(page=dfPagesUnique.loc[i, 'page'],
statusCode=dfPagesUnique.loc[i, 'statusCode'],
html=dfPagesUnique.loc[i, 'html'],
encoding=dfPagesUnique.loc[i, 'encoding'],
elapsedTime=dfPagesUnique.loc[i, 'elapsedTime'],
body=dfPagesUnique.loc[i, 'body'],
search_date=dfPagesUnique.loc[i, 'search_date'])
db.session.add(newPage)
db.session.commit()
else :
print("exists update id = "+str(dbPage.id))
#update values
dbPage.page=dfPagesUnique.loc[i, 'page']
dbPage.statusCode=dfPagesUnique.loc[i, 'statusCode']
dbPage.html=dfPagesUnique.loc[i, 'html']
dbPage.encoding=dfPagesUnique.loc[i, 'encoding']
dbPage.elapsedTime=dfPagesUnique.loc[i, 'elapsedTime']
dbPage.body=dfPagesUnique.loc[i, 'body'],
dbPage.search_date=dfPagesUnique.loc[i, 'search_date']
db.session.commit()
myShow=80+round((stepShow*i))
yield "data:" + str(myShow) + "\n\n" #to show 80% ++
###End Google search and scrap content page
myShow=90
yield "data:" + str(myShow) + "\n\n" #to show 90%
Sauvegarde dans la table des mots clés et la table des mots clés par utilisateur
###################################
#update keyword and keyworduser
###################################
#need to get firtsKWC in keyword table before
firstKWC = db.session.query(Keyword).filter_by(keyword=myKeyword, tldLang=myTLDLang).first()
#Do we just process a new Google Scrap and Page Scrap ?
if goSearch :
myDataDate = myDate #Today
else :
if firstKWC is None :
myDataDate = myDate #Today
else :
myDataDate = firstKWC.data_date #old data date
#do somebody already process a research before ?
if firstKWC is None :
#insert
newKeyword = Keyword(keyword= myKeyword, tldLang=myTLDLang , data_date=myDataDate, search_date=myDate)
db.session.add(newKeyword)
db.session.commit()
db.session.refresh(newKeyword)
db.session.commit()
myKeywordId = newKeyword.id #
else :
myKeywordId = firstKWC.id
#update
firstKWC.data_date=myDataDate
firstKWC.search_date=myDate
db.session.commit()
myShow=91
yield "data:" + str(myShow) + "\n\n" #to show 91%
#for KeywordUSer
#Did this user already process this search ?
print(" myKeywordId="+str(myKeywordId))
dfSession.loc[ myUserId,'keywordId']=myKeywordId
dbKeywordUser = db.session.query(KeywordUser).filter_by(keyword= myKeyword, tldLang=myTLDLang, username=myUserName).first()
if dbKeywordUser is None :
print("insert index new Keyword for = "+ myUserName)
newKeywordUser = KeywordUser(keywordId= myKeywordId, keyword= myKeyword,
tldLang=myTLDLang , username= myUserName, data_date=myDataDate, search_date=myDate)
db.session.add(newKeywordUser)
db.session.commit()
myKeywordUserId=newKeywordUser.id
else :
myKeywordUserId=dbKeywordUser.id #for the name
print("exists update only myDataDate" )
#update values for the current user
dbKeywordUser.data_date=myDataDate
dbKeywordUser.search_date=myDate
db.session.commit()
Création des fichiers de mots clés calculés par TF-IDF (et fin de /progress)
######################################################
####################### tf-idf files generation
dfSession.loc[ myUserId,'keywordUserId']=myKeywordUserId
#Make sure download directory exists
myDirectory = myScriptDirectory+myconfig.UPLOAD_SUBDIRECTORY+"/"+myUserName
if not os.path.exists(myDirectory):
os.makedirs(myDirectory)
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myShow=92
yield "data:" + str(myShow) + "\n\n" #to show 92%
#Read in position table to get the pages list in dataframe
dfPagesUnique = pd.read_sql_query(db.session.query(Position, Page).filter_by(keyword= myKeyword, tldLang= myTLDLang).filter(Position.page==Page.page).statement, con=db.engine)
dfPagesUnique.info()
#Remove apostrophes and quotes
print("Remove apostrophes and quotes")
stopQBody = dfPagesUnique['body'].apply(lambda x: x.replace("\"", " "))
stopAQBody =stopQBody.apply(lambda x: x.replace("'", " "))
#Remove english stopwords
print("Remove English stopwords")
stopEnglish = stopwords.words('english')
stopEnglishBody = stopAQBody.apply(lambda x: ' '.join([word for word in x.split() if word not in ( stopEnglish)]))
#Get the good local stopwords
stopLocalLanguage = myconfig.dfTLDLanguages.loc[myTLDLang, 'stopWords']
if (stopLocalLanguage in stopwords.fileids()) :
print(" stopLocalLanguage="+ stopLocalLanguage)
stopLocal = stopwords.words(stopLocalLanguage)
print("Remove local Stop Words")
stopLocalBody = stopEnglishBody.apply(lambda x: ' '.join([word for word in x.split() if word not in (stopLocal)]))
else :
stopLocalBody = stopEnglishBody
print("Remove Special Characters")
stopSCBody = stopLocalBody.apply(lambda x: re.sub(r"[-()\"#/@;:<>{}`+=~|.!?,]", " ", x))
print("Remove Numbers")
#remove numbers
stopNumbersBody = stopSCBody.apply(lambda x: ''.join(i for i in x if not i.isdigit()))
print("Remove Multiple Spaces")
stopSpacesBody = stopNumbersBody.apply(lambda x: re.sub(" +", " ", x))
#print("Encode in UTF-8")
#stopEncodeBody = stopSpacesBody.apply(lambda x: x.encode('utf-8', 'ignore'))
stopEncodeBody= stopSpacesBody #already in utf-8
#create "clean" Corpus
corpus = stopEncodeBody.tolist()
print('corpus Size='+str(len(corpus)))
myMaxFeatures = myconfig.myMaxFeatures
myMaxResults = myconfig.myMaxResults
print("Popular Expressions")
print("Mean for min to max words")
tf_idf_vectMinMax = TfidfVectorizer(ngram_range=(myconfig.myMinNGram,myconfig.myMaxNGram), max_features=myMaxFeatures) # , norm=None
XtrMinMax = tf_idf_vectMinMax.fit_transform(corpus)
featuresMinMax = tf_idf_vectMinMax.get_feature_names()
myTopNMinMax=min(len(featuresMinMax), myMaxResults[myRole])
dfTopMinMax = top_mean_feats(Xtr=XtrMinMax, features=featuresMinMax, grp_ids=None, top_n= myTopNMinMax)
dfTopMinMax.to_csv(myDirectory+"/pop-"+myKeywordFileNameString+"-min-max.csv", sep=myconfig.myCsvSep , encoding='utf-8', index=False)
myShow=93
yield "data:" + str(myShow) + "\n\n" #to show 93%
print("for 1 word")
#Keywords suggestion
# for 1 word
tf_idf_vect1 = TfidfVectorizer(ngram_range=(1,1), max_features=myMaxFeatures) # , norm=None
Xtr1 = tf_idf_vect1.fit_transform(corpus)
features1 = tf_idf_vect1.get_feature_names()
myTopN1=min(len(features1), myMaxResults[myRole])
dfTop1 = top_mean_feats(Xtr=Xtr1, features=features1, grp_ids=None, top_n=myTopN1)
dfTop1.to_csv(myDirectory+"/pop-"+myKeywordFileNameString+"-1.csv", sep=myconfig.myCsvSep , encoding='utf-8', index=False)
#for 2
print("for 2 words")
tf_idf_vect2 = TfidfVectorizer(ngram_range=(2,2), max_features=myMaxFeatures) # , norm=None
Xtr2 = tf_idf_vect2.fit_transform(corpus)
features2 = tf_idf_vect2.get_feature_names()
myTopN2=min(len(features2), myMaxResults[myRole])
dfTop2 = top_mean_feats(Xtr=Xtr2, features=features2, grp_ids=None, top_n=myTopN2)
dfTop2.to_csv(myDirectory+"/pop-"+myKeywordFileNameString+"-2.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
#for 3
print("for 3 words")
tf_idf_vect3 = TfidfVectorizer(ngram_range=(3,3), max_features=myMaxFeatures) # , norm=None
Xtr3 = tf_idf_vect3.fit_transform(corpus)
features3 = tf_idf_vect3.get_feature_names()
myTopN3=min(len(features3), myMaxResults[myRole])
dfTop3 = top_mean_feats(Xtr=Xtr3, features=features3, grp_ids=None, top_n=myTopN3)
dfTop3.to_csv(myDirectory+"/pop-"+myKeywordFileNameString+"-3.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
myShow=94
yield "data:" + str(myShow) + "\n\n" #to show 94%
#for 4
print("for 4 words")
tf_idf_vect4 = TfidfVectorizer(ngram_range=(4,4), max_features=myMaxFeatures) # , norm=None
Xtr4 = tf_idf_vect4.fit_transform(corpus)
features4 = tf_idf_vect4.get_feature_names()
myTopN4=min(len(features4), myMaxResults[myRole])
dfTop4 = top_mean_feats(Xtr=Xtr4, features=features4, grp_ids=None, top_n=myTopN4)
dfTop4.to_csv(myDirectory+"/pop-"+myKeywordFileNameString+"-4.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
#for 5
print("for 5 words")
tf_idf_vect5 = TfidfVectorizer(ngram_range=(5,5), max_features=myMaxFeatures) # , norm=None
Xtr5 = tf_idf_vect5.fit_transform(corpus)
features5 = tf_idf_vect5.get_feature_names()
myTopN5=min(len(features5), myMaxResults[myRole])
dfTop5 = top_mean_feats(Xtr=Xtr5, features=features5, grp_ids=None, top_n=myTopN5)
dfTop5.to_csv(myDirectory+"/pop-"+myKeywordFileNameString+"-5.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
#for 6
print("for 6 words")
tf_idf_vect6 = TfidfVectorizer(ngram_range=(6,6), max_features=myMaxFeatures) # , norm=None
Xtr6 = tf_idf_vect6.fit_transform(corpus)
features6 = tf_idf_vect6.get_feature_names()
myTopN6=min(len(features6), myMaxResults[myRole])
dfTop6 = top_mean_feats(Xtr=Xtr6, features=features6, grp_ids=None, top_n=myTopN6)
dfTop6.to_csv(myDirectory+"/pop-"+myKeywordFileNameString+"-6.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
myShow=95
yield "data:" + str(myShow) + "\n\n" #to show 95%
print("Original Expressions")
print("NZ Mean for min to max words")
dfTopNZMinMax = top_nonzero_mean_feats(Xtr=XtrMinMax, features=featuresMinMax, grp_ids=None, top_n=myTopNMinMax)
dfTopNZMinMax.to_csv(myDirectory+"/ori-"+myKeywordFileNameString+"-min-max.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
myShow=96
yield "data:" + str(myShow) + "\n\n" #to show 96%
#for 1
print("NZ for 1 word")
dfTopNZ1 = top_nonzero_mean_feats(Xtr=Xtr1, features=features1, grp_ids=None, top_n=myTopN1)
dfTopNZ1.to_csv(myDirectory+"/ori-"+myKeywordFileNameString+"-1.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
#for 2
print("NZ for 2 words")
dfTopNZ2 = top_nonzero_mean_feats(Xtr=Xtr2, features=features2, grp_ids=None, top_n=myTopN2)
dfTopNZ2.to_csv(myDirectory+"/ori-"+myKeywordFileNameString+"-2.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
myShow=97
yield "data:" + str(myShow) + "\n\n" #to show 97%
#for 3
print("NZ for 3 words")
dfTopNZ3 = top_nonzero_mean_feats(Xtr=Xtr3, features=features3, grp_ids=None, top_n=myTopN3)
dfTopNZ3.to_csv(myDirectory+"/ori-"+myKeywordFileNameString+"-3.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
# for 4
print("NZ for 4 words")
dfTopNZ4 = top_nonzero_mean_feats(Xtr=Xtr4, features=features4, grp_ids=None, top_n=myTopN4)
dfTopNZ4.to_csv(myDirectory+"/ori-"+myKeywordFileNameString+"-4.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
#for 5
print("NZ for 5 words")
dfTopNZ5 = top_nonzero_mean_feats(Xtr=Xtr5, features=features5, grp_ids=None, top_n=myTopN5)
dfTopNZ5.to_csv(myDirectory+"/ori-"+myKeywordFileNameString+"-5.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
myShow=99
yield "data:" + str(myShow) + "\n\n" #to show 99%
#for 6
print("NZ for 6 words")
dfTopNZ6 = top_nonzero_mean_feats(Xtr=Xtr6, features=features6, grp_ids=None, top_n=myTopN6)
dfTopNZ6.to_csv(myDirectory+"/ori-"+myKeywordFileNameString+"-6.csv", sep=myconfig.myCsvSep, encoding='utf-8', index=False)
#Finish
myShow=100
yield "data:" + str(myShow) + "\n\n" #to show 100% and close
#/run
#loop generate
return Response(generate(dfScrap, myUserId), mimetype='text/event-stream')
Routes pour télécharger les fichiers
#Download keywords File filename
@app.route('/downloadKWF/<path:filename>', methods=['GET', 'POST'] ) # this is a job for GET, not POST
def downloadKWF(filename):
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myUserName=dfSession.loc[ myUserId,'userName']
print("myUserId="+str(myUserId))
myScriptDirectory = get_script_directory()
myDirectory = myScriptDirectory+myconfig.UPLOAD_SUBDIRECTORY+"/"+myUserName
myFileName=filename
print("myFileName="+myFileName)
return send_file(myDirectory+"/"+myFileName,
mimetype='text/csv',
attachment_filename=myFileName,
as_attachment=True)
#Download Popular Keywords All Keywords
@app.route('/popAllCSV')
def popAllCSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="pop-"+myKeywordFileNameString+"-min-max.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download Popular Keywords 1 gram Keywords
@app.route('/pop1CSV')
def pop1CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="pop-"+myKeywordFileNameString+"-1.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download Popular Keywords 2 gram Keywords
@app.route('/pop2CSV')
def pop2CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="pop-"+myKeywordFileNameString+"-2.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download Popular Keywords 3 gram Keywords
@app.route('/pop3CSV')
def pop3CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="pop-"+myKeywordFileNameString+"-3.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download Popular Keywords 4 gram Keywords
@app.route('/pop4CSV')
def pop4CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="pop-"+myKeywordFileNameString+"-4.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download Popular Keywords 5 gram Keywords
@app.route('/pop5CSV')
def pop5CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="pop-"+myKeywordFileNameString+"-5.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download Popular Keywords 5 gram Keywords
@app.route('/pop6CSV')
def pop6CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="pop-"+myKeywordFileNameString+"-6.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
########################################################
# Original Keywords
########################################################
#Download Original Keywords All Keywords
@app.route('/oriAllCSV')
def oriAllCSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="ori-"+myKeywordFileNameString+"-min-max.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download original Keywords 1 gram Keywords
@app.route('/ori1CSV')
def ori1CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="ori-"+myKeywordFileNameString+"-1.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download original Keywords 2 gram Keywords
@app.route('/ori2CSV')
def ori2CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="ori-"+myKeywordFileNameString+"-2.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download original Keywords 3 gram Keywords
@app.route('/ori3CSV')
def ori3CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="ori-"+myKeywordFileNameString+"-3.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download original Keywords 4 gram Keywords
@app.route('/ori4CSV')
def ori4CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="ori-"+myKeywordFileNameString+"-4.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download original Keywords 5 gram Keywords
@app.route('/ori5CSV')
def ori5CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="ori-"+myKeywordFileNameString+"-5.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
#Download original Keywords 5 gram Keywords
@app.route('/ori6CSV')
def ori6CSV():
#get Session Variables
if current_user.is_authenticated:
myUserId = current_user.get_id()
print("myUserId="+str(myUserId))
myKeyword = dfSession.loc[ myUserId,'keyword']
myTLDLang = dfSession.loc[myUserId,'tldLang']
myKeywordId = dfSession.loc[ myUserId,'keywordId']
myKeywordUserId = dfSession.loc[ myUserId,'keywordUserId']
print("myUserId="+str(myUserId))
myKeywordFileNameString=strip_accents(myKeyword).lower()
myKeywordFileNameString = "-".join(myKeywordFileNameString.split(" "))
myKeywordFileNameString = myKeywordFileNameString+"_"+myTLDLang
myKeywordFileNameString = str(myKeywordId)+"-"+str(myKeywordUserId)+"_"+myKeywordFileNameString
print("myKeywordFileNameString = "+myKeywordFileNameString)
myFileName="ori-"+myKeywordFileNameString+"-6.csv"
return redirect(url_for('downloadKWF', filename=myFileName))
Lancement de l’application TF-IDF Keywords Suggest
if __name__ == '__main__':
app.run()
# app.run(debug=True, use_reloader=True)
Page template tfidfkeywordsuggest.html
Cette template comporte notamment le javascript qui permet de récupérer les événements du serveur et d’afficher la barre de progression.
{% extends "bootstrap/base.html" %}
{% import "bootstrap/wtf.html" as wtf %}
{% block title %}
TF-IDF Keywords Suggest
{% endblock %}
{% block content %}
<nav class="navbar navbar-inverse navbar-fixed-top">
<div class="container-fluid">
<div class="navbar-header">
<button type="button" class="navbar-toggle collapsed" data-toggle="collapse" data-target="#navbar" aria-expanded="false" aria-controls="navbar">
<span class="sr-only">Toggle navigation</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a class="navbar-brand" href="{{url_for('index')}}"><img src="{{url_for('static', filename='Oeil_Anakeyn.jpg')}}", align="left", width=30 /></a>
</div>
<div id="navbar" class="navbar-collapse collapse">
<ul class="nav navbar-nav navbar-right">
<!--
<li><a href="#">Settings</a></li>
<li><a href="#">Profile</a></li>
-->
<li><a href="{{ url_for('logout') }}">Log Out</a></li>
</ul>
</div>
</div>
</nav>
<!-- Left Menu -->
<div class="container-fluid">
<div class="row">
<div class="col-sm-3 col-md-2 sidebar">
<ul class="nav nav-sidebar">
<li class="active"><a href="#">TF-IDF Keyword Suggest <span class="sr-only">(current)</span></a></li>
<!--
<li><a href="#">Archives</a></li>
-->
</ul>
<ul class="nav nav-sidebar">
</ul>
<!--
<ul class="nav nav-sidebar">
{% if role == 0 %}
<li><a href="">Parameters</a></li>
{% endif %}
</ul>
-->
</div>
<div class="col-sm-9 col-sm-offset-3 col-md-10 col-md-offset-2 main">
<h1 class="page-header">Welcome, {{ name }} </h1>
<div class="row placeholders">
<img src="{{url_for('static', filename='Anakeyn_Rectangle.jpg')}}" />
{% if limitReached == 1 %}
<h3 class="limit-Reached">Limit Reached!</h3>
{% endif %}
{% if limitReached == 0 %}
<form class="form-signin" method="POST" enctype=multipart/form-data action="{{ url_for('tfidfkeywordssuggest') }}">
{{ form.hidden_tag() }}
{{ wtf.form_field(form.keyword) }} {{ wtf.form_field(form.tldLang) }} <button class="btn btn-lg btn-primary btn-block" type="submit">Search</button>
</form>
{% endif %}
<h3 class="progress-title"> </h3>
<div class="progress" style="height: 22px; margin: 10px;">
<div class="progress-bar progress-bar-striped progress-bar-animated" role="progressbar" aria-valuenow="0"
aria-valuemin="0" aria-valuemax="100" style="width: 0%">
<span class="progress-bar-label">0%</span>
</div>
</div>
<div id="myResults" style="visibility:hidden;" align="center">
<table cellpadding="10" cellspacing="10">
<tr><td><a href="/popAllCSV">Download most {{ MaxResults }} popular expressions among Urls crawled</a></td><td width="10%"> </td><td><a href="/oriAllCSV">Download {{ MaxResults }} original expressions among Urls crawled</a></td></tr>
<tr><td><a href="/pop1CSV">Download most {{ MaxResults }} popular 1 word expressions among Urls crawled </a></td><td width="10%"> </td><td><a href="/ori1CSV">Download {{ MaxResults }} original 1 word expressions among Urls crawled</a></td></tr>
<tr><td><a href="/pop2CSV">Download most {{ MaxResults }} popular 2 words expressions among Urls crawled </a></td><td width="10%"> </td><td><a href="/ori2CSV">Download {{ MaxResults }} original 2 words expressions among Urls crawled</a></td></tr>
<tr><td><a href="/pop3CSV">Download most {{ MaxResults }} popular 3 words expressions among Urls crawled</a></td><td width="10%"> </td><td><a href="/ori3CSV">Download {{ MaxResults }} original 3 words expressions among Urls crawled</a></td></tr>
<tr><td><a href="/pop4CSV">Download most {{ MaxResults }} popular 4 words expressions among Urls crawled</a></td><td width="10%"> </td><td><a href="/ori4CSV">Download {{ MaxResults }} original 4 words expressions among Urls crawled</a></td></tr>
<tr><td><a href="/pop5CSV">Download most {{ MaxResults }} popular 5 words expressions among Urls crawled</a></td><td width="10%"> </td><td><a href="/ori5CSV">Download {{ MaxResults }} original 5 words expressions among Urls crawled</a></td></tr>
<tr><td><a href="/pop6CSV">Download most {{ MaxResults }} popular 6 words expressions among Urls crawled </a></td><td width="10%"> </td><td><a href="/ori6CSV">Download {{ MaxResults }} original 6 words expressions among Urls crawled</a></td></tr>
</table>
</div>
</div>
</div>
</div>
</div>
{% endblock %}
{% block styles %}
{{super()}}
<link rel="stylesheet" href="{{url_for('.static', filename='keywordssuggest.css')}}">
<script>
var source = new EventSource("/progress");
source.onmessage = function(event) {
$('.progress-bar').css('width', event.data+'%').attr('aria-valuenow', event.data);
$('.progress-bar-label').text(event.data+'%');
if(event.data ==-1 ){
$('.progress-title').text('You reached your day search limit - Please come back tomorrow!');
source.close()
}
if(event.data >0 && event.data < 50 ){
$('.progress-title').text('Search in Google, please be patient!');
}
if(event.data >=50 && event.data < 60 ){
$('.progress-title').text('Select Urls to crawl, please be patient!');
}
if(event.data >=60 && event.data < 70 ){
$('.progress-title').text('Crawl Urls, please be patient!');
}
if(event.data >=70 && event.data < 80 ){
$('.progress-title').text('Get content from Urls, please be patient!');
}
if(event.data >=80 && event.data < 90 ){
$('.progress-title').text('Save content from Urls, please be patient!');
}
if(event.data >=90 && event.data < 100 ){
$('.progress-title').text('Create TF-IDF Keywords Files, please be patient!');
}
if(event.data >= 100){
$('.progress-title').text('Process Completed - Download your TF-IDF Keywords files');
document.getElementById("myResults").style.visibility = "visible";
source.close()
}
}
</script>
{% endblock %}
Merci pour votre attention.
Suggestions et questions en commentaires bienvenues sur l’outil Anakeyn TF-IDF Keywords Suggest.
A Bientôt,
Pierre