Partager la publication "Détection du trafic Web significatif avec R et AnomalyDetection"
Dans cet article nous allons voir comment détecter les jours ou l’on a un trafic significativement plus important que les autres jours sur son site Web avec R et la bibliothèque AnomalyDetection de Twitter.
De quoi aurons nous besoin ?
Logiciel R
Comme précédemment, afin de pouvoir tester le code source de cette démonstration nous vous invitons à télécharger Le Logiciel R sur ce site https://cran.r-project.org/, ainsi que l’environnement de développement RStudio ici : https://www.rstudio.com/products/rstudio/download/.
Bibliothèque AnomalyDetection de Twitter
Afin de pouvoir détecter des événements significatifs, nous allons utiliser le package R « AnomalyDetection » développé par Twitter et disponible sur Github https://github.com/twitter/AnomalyDetection
Ce package est basé sur un algorithme « Seasonal Hybrid
Extreme Studentized Deviate » qui permet de détecter des résultats
particuliers ou valeurs aberrantes dans des séries temporelles ou des vecteurs.
Dans notre cas, on considèrera qu’une « valeur aberrante » par rapport au trafic « normal » du site correspond à un événement particulier ayant permis de générer un trafic supplémentaire important.
Jeu de données
Afin d’illustrer notre propos, nous partirons du jeu de données de l’association Networking Morbihan que nous avons déjà utilisé précédemment.
Ce jeu de données a été récupéré via l’API Google Analytics puis ensuite nettoyé du spam comme nous l’avons expliqué dans cet article précédent.
L’avantage de ce jeu de données est que nous avons un historique de 7 ans 1/2.
Vous pouvez télécharger ce jeu de données sur notre boutique à partir du fichier d’archive à l’adresse : https://www.anakeyn.com/boutique/produit/script-r-trafic-significatif/. Dézippez-le et sauvegardez-le dans le même répertoire que votre code R.
Code Source
Vous pouvez copier/coller les bouts de code dans les zones de code ou sinon tout télécharger gratuitement depuis notre boutique : https://www.anakeyn.com/boutique/produit/script-r-trafic-significatif/
Récupération des données :
Les données sont récupérées à partir du fichier dfPageViews.csv et mises en forme pour avoir un enregistrement par jour.
##########################################################################
# Auteur : Pierre Rouarch 2019
# Détection du traffic significatif sur un site Web avec R.
# Ce programme est un exemple pour détecter les jours de traffic important
# et significatif dans des données Google Analytics. Nous utilisons pour
# cela le package R développé par Twitter "AnomalyDetection"
# https://github.com/twitter/AnomalyDetection
# Pour illustrer notre propos nous utiliserons le jeu de données de
# l'association Networking-Morbihan
.
##########################################################################
#Packages et bibliothèques utiles (décommenter au besoin)
##########################################################################
#install.packages("lubridate") #si vous ne l'avez pas
#install.packages("tseries")
#install.packages("devtools")
#devtools::install_github("twitter/AnomalyDetection") #pour anomalyDetection de Twitter
#install.packages("XML")
#install.packages("stringi")
#install.packages("BSDA")
#install.packages("BBmisc")
#install.packages("stringi")
#install.packages("FactoMineR")
#install.packages("factoextra")
#install.packages("rcorr")
#install.packages("lubridate") #si vous ne l'avez pas
library (lubridate) #pour yday
#library(tseries) #pour ts
library(AnomalyDetection) #pour anomalydetectionVec
#library(XML) # pour xmlParse
#library(stringi) #pour stri_replace_all_fixed(x, " ", "")
#library(BSDA) #pour SIGN.test
#library(BBmisc) #pour which.first
#install.packages("stringi")
library(stringi) #pour stri_detect
#library(ggfortify) #pour ploter autoplot type ggplot
#install.packages("tidyverse") #si vous ne l'avez pas #pour gggplot2, dplyr, tidyr, readr, purr, tibble, stringr, forcats
#install.packages("forecast") #pour ma
#Chargement des bibliothèques utiles
library(tidyverse) #pour gggplot2, dplyr, tidyr, readr, purr, tibble, stringr, forcats
library(forecast) #pour arima, ma, tsclean
##########################################################################
# Récupération du Jeu de données nettoyé
##########################################################################
dfPageViews <- read.csv("dfPageViews.csv", header=TRUE, sep=";")
#str(dfPageViews) #verif
dfPageViews$date <- as.Date(dfPageViews$date,format="%Y-%m-%d")
#str(dfPageViews) #verif
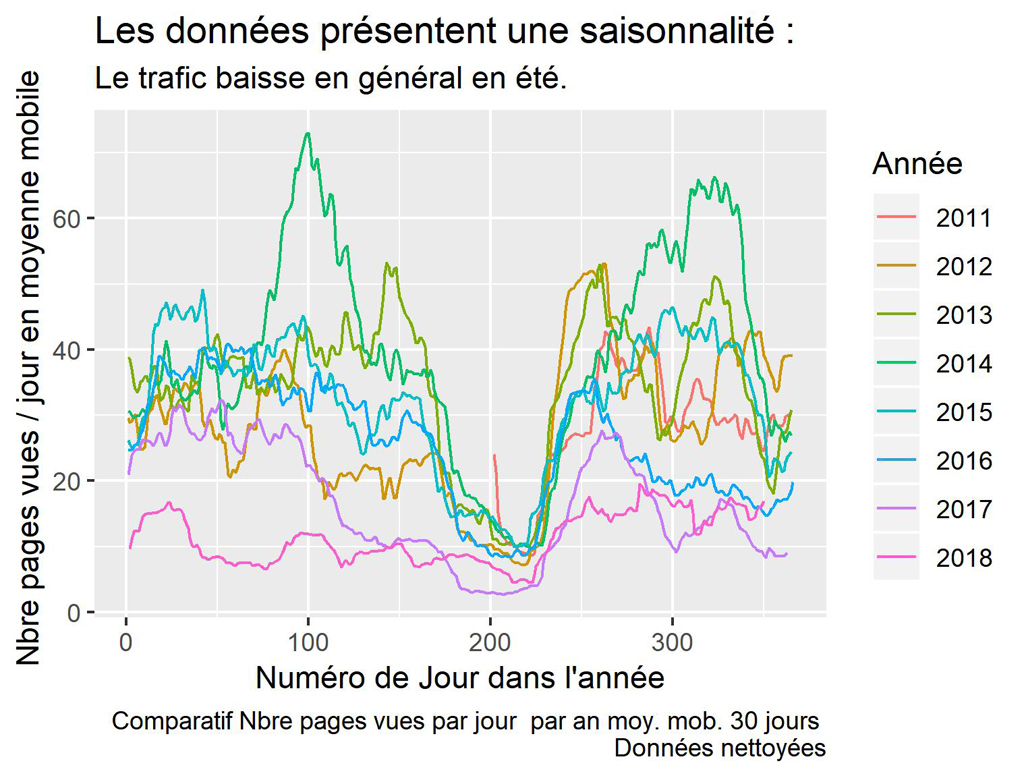
#visualisation comparatif des années
dfDatePV <- as.data.frame(dfPageViews$date)
colnames(dfDatePV)[1] <- "date"
daily_data <- dfDatePV %>% #daily_data à partir de dfDatePV
group_by(date) %>% #groupement par date
mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date
as.data.frame() %>% #sur d'avoir une data.frame
unique() %>% #ligne unique par jour.
mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours)
mutate(year = format(date,"%Y")) %>% #creation de la variable year
mutate(dayOfYear = yday(date)) #creation de la variable dayOfYear
#comparatifs 2011 - 2018
ggplot() +
geom_line(data = daily_data, aes(x = dayOfYear, y = cnt_ma30, col=year)) +
xlab("Numéro de Jour dans l'année") +
ylab("Nbre pages vues / jour en moyenne mobile ") +
labs(title = "Les données présentent une saisonnalité : ",
subtitle = "Le trafic baisse en général en été.",
caption = "Comparatif Nbre pages vues par jour par an moy. mob. 30 jours \n Données nettoyées",
color = "Année")
#sauvegarde du dernier ggplot.
ggsave(filename = "PV-Comparatif-mm30.jpeg", dpi="print")
#Sauvegarde de daily_data
#str(daily_data) #verif
write.csv2(daily_data, file = "DailyDataClean.csv", row.names=FALSE) #sauvegarde en csv avec ;
Graphique du TRAFIC PAR ANNEES
Détection des anomalies.
Ici nous utilisons la version AnomalyDetectionVec qui permet de détecter des anomalies dans une séries d’observations.
Vous devez renseigner l’algorithme avec différents paramètres notamment :
- max_anoms : le nombre max d’anomalies en % du total d’observations.
- direction : détermine si l’algorithme tient compte des valeurs passées, futures ou dans les deux sens. nous avons choisi dans les 2 sens ‘both’.
- alpha : niveau de significativité, nous avons pris un classique 5%.
- period : le nombre d’observations dans une période ; pour nous 30 car nous supposons que nous faisons des actions marketing tous les 30 jours. Toutefois ce paramètre n’a pas beaucoup d’effet sur nos données.
##########################################################################
# Détections des événements significatifs - Anomaly Detection
##########################################################################
#help(AnomalyDetectionVec) #pour voir la doc
#recherche des anomalies sur la variable Pageviews
res <- AnomalyDetectionVec(daily_data[,2], max_anoms=0.05,
direction='both', alpha=0.05, plot=FALSE, period=30)
nrow(res$anoms) #98
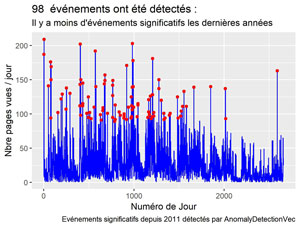
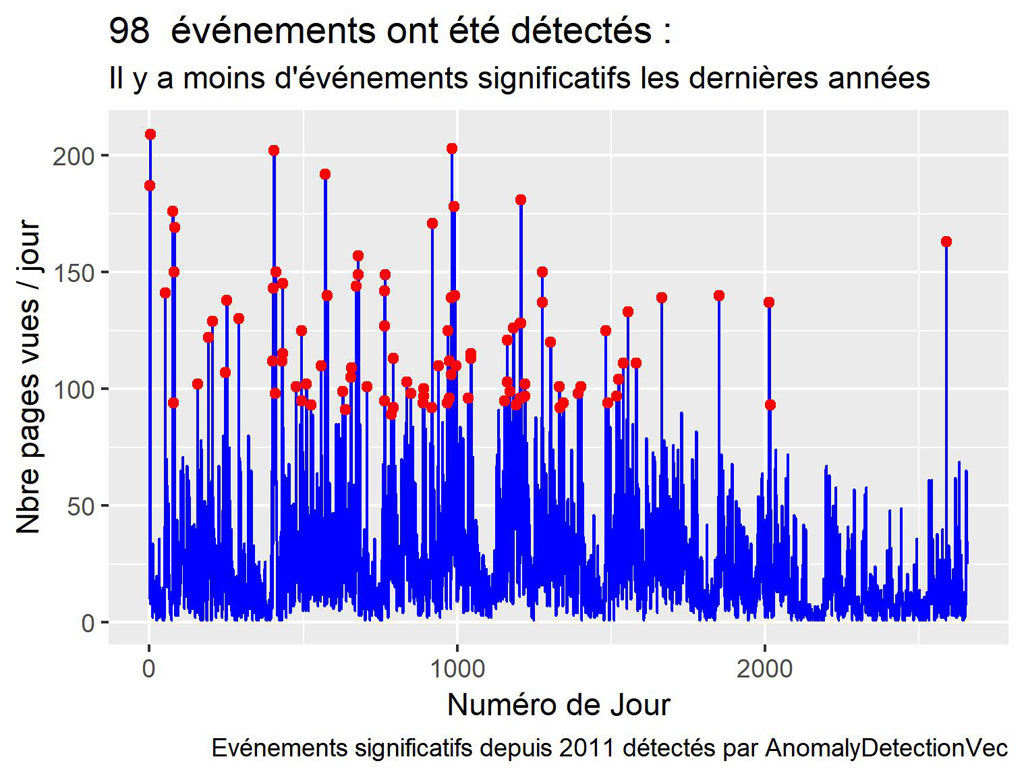
Voilà c’est super simple, le système a détecté 98 « anomalies ». A vous de faire varier les paramètres selon vos besoins et vos données.
Affichage des anomalies sur la courbe des pages vues.
Voyons l’effet sur la courbe des pages vues sur toute la période.
#Affichage des anomalies sur la courbe des pages vues.
daily_data$index <- as.integer(as.character(rownames(daily_data))) #pour etre raccord avec res$anoms.
ggplot() +
geom_line(data=daily_data, aes(index, Pageviews), color='blue') +
geom_point(data=res$anoms , aes(index, anoms), color='red') +
xlab("Numéro de Jour") +
ylab("Nbre pages vues / jour") +
labs(title = paste(nrow(res$anoms)," événements ont été détectés : "),
subtitle = "Il y a moins d'événements significatifs les dernières années",
caption = "Evénements significatifs depuis 2011 détectés par AnomalyDetectionVec")
ggsave(filename = "Anoms-Pageviews-s2011.jpeg", dpi="print") #sauvegarde du dernier ggplot.
Affichage des anomalies en moyenne mobile sur 30 jours.
#Affichage sur la courbe des moyennes mobiles sur 30 jours
#il faut que l'on récupère cnt_ma30 de daily_data pour afficher les anomalies sur la courbe
myAnoms <- left_join(res$anoms, daily_data, by="index")
ggplot() +
geom_line(data=daily_data, aes(index, cnt_ma30), color='blue') +
geom_point(data=myAnoms, aes(index, cnt_ma30), color='red') +
xlab("Numéro de Jour") +
ylab("Nbre pages vues en moyenne mobile / jour") +
labs(title = paste(nrow(res$anoms)," événements ont été détectés : "),
subtitle = "Il y a moins d'événements significatifs les dernières années",
caption = "Evénements significatifs depuis 2011 détectés par AnomalyDetectionVec \n moyenne mobile 30 jours")
ggsave(filename = "Anoms-Pageviews-s2011-mm30.jpeg", dpi="print") #sauvegarde du dernier ggplot.
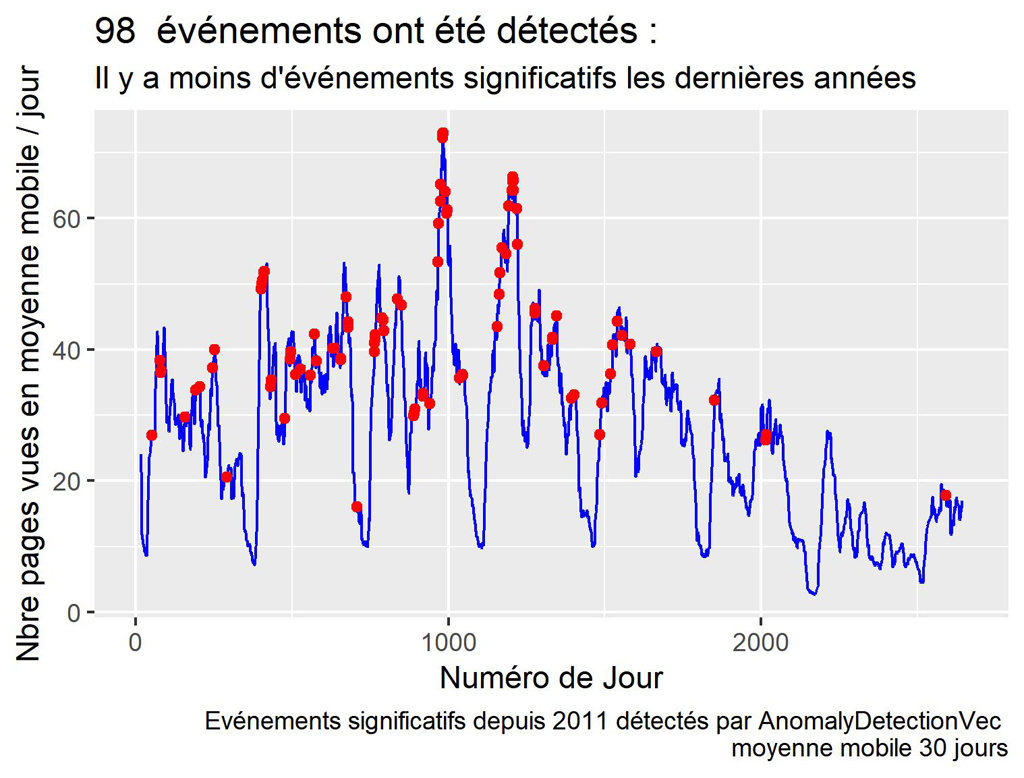
Comme le calcul est basé sur toute la période et sur plusieurs années et comme le trafic a baissé, on voit moins d’événements significatifs en 2017 et 2018.
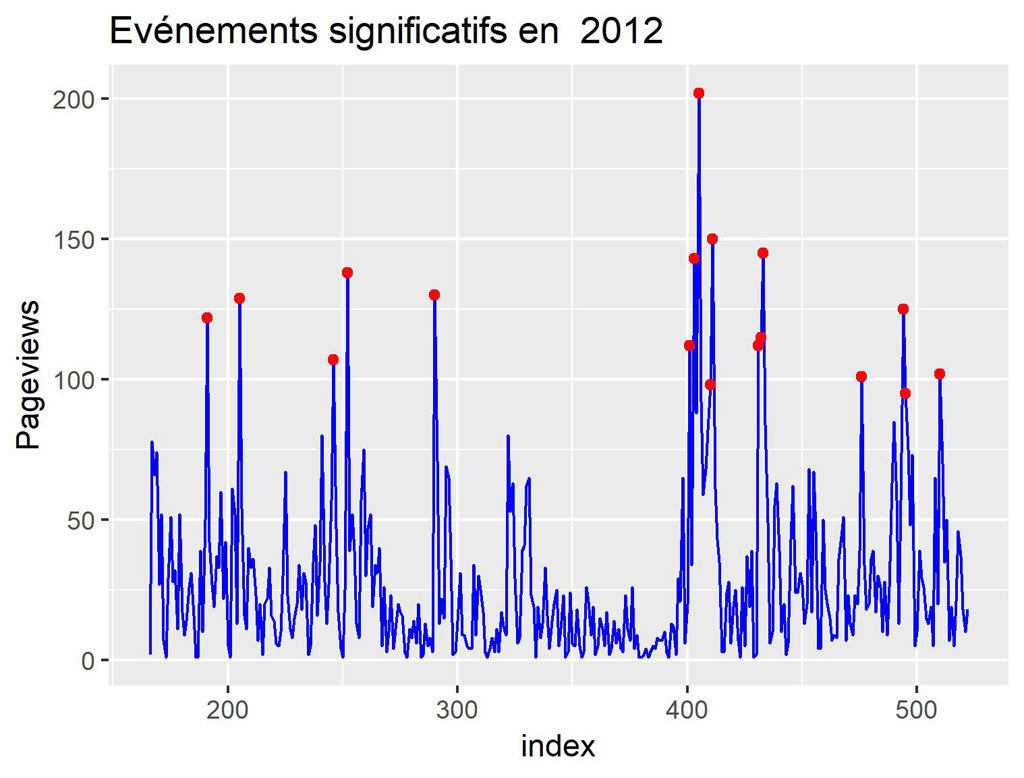
Affichage pour les années 2012 et 2013
Par curiosité et pour y voir plus clair affichons les graphiques pour 2012 et 2013 par exemple.
#Affichage pour 2012
myYear = "2012"
ggplot() +
geom_line(data=daily_data[which(daily_data$year == myYear), ] , aes(index, Pageviews), color='blue') +
geom_point(data=myAnoms[which(myAnoms$year == myYear), ] , aes(index, anoms), color='red') +
ggtitle(label = paste("Evénements significatifs en ", myYear))
ggsave(filename = stri_replace_all_fixed(paste("Anoms-Pageviews-",myYear,".jpeg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot.
#Affichage pour 2013
myYear = "2013"
ggplot() +
geom_line(data=daily_data[which(daily_data$year == myYear), ] , aes(index, Pageviews), color='blue') +
geom_point(data=myAnoms[which(myAnoms$year == myYear), ] , aes(index, anoms), color='red') +
ggtitle(label = paste("Evénements significatifs en ", myYear))
ggsave(filename = stri_replace_all_fixed(paste("Anoms-Pageviews-",myYear,".jpeg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot.
Pour 2012
POUR 2013
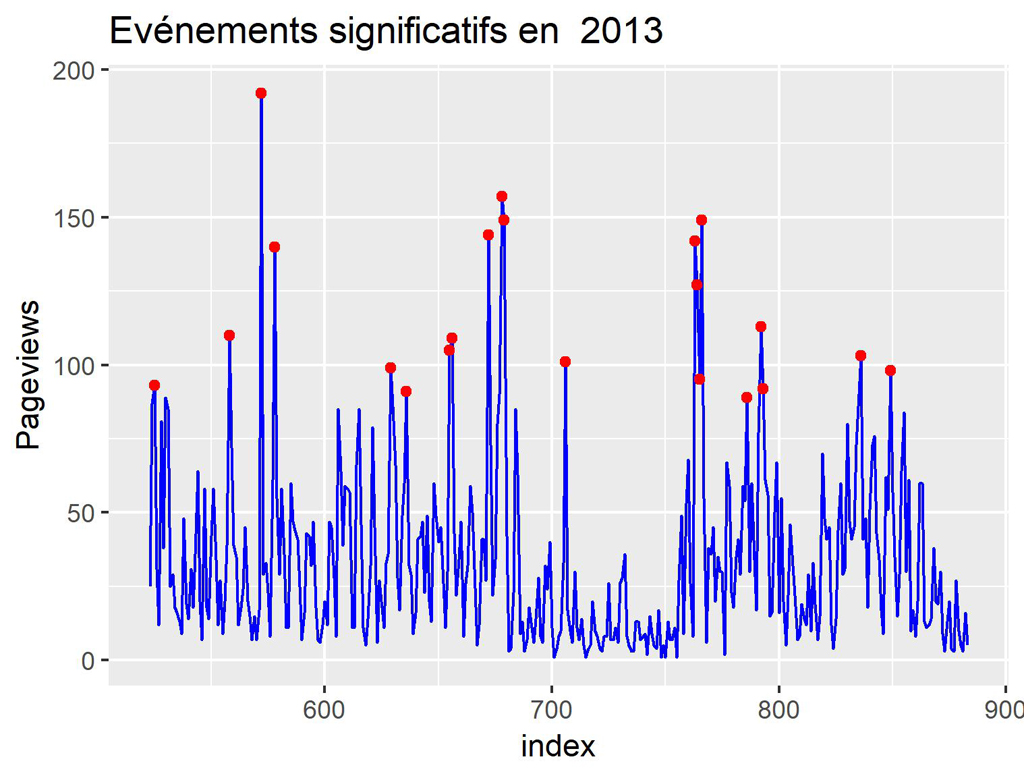
A ce stade, on pourrait penser que les événements significatifs (que l’on peut regrouper parfois lorsqu’ils sont proches) correspondent plus ou moins à une régularité mensuelle.
Ceci pourrait correspondre aux actions marketing mensuelles que nous avons réalisées pour ce site. Toutefois, nous vérifierons cela dans un prochain article.
Et vous ? Qu’obtenez vous avec vos données ?
A Bientôt,
Pierre