Partager la publication "Récupérer les liens contextuels de son site Web avec R"
Dans cet article nous verrons comment récupérer les liens contextuels, c’est à dire les liens présents dans la zone éditoriale (ou de contenu) sur les pages de son site.
Pour être plus explicite, sur l’image suivante :
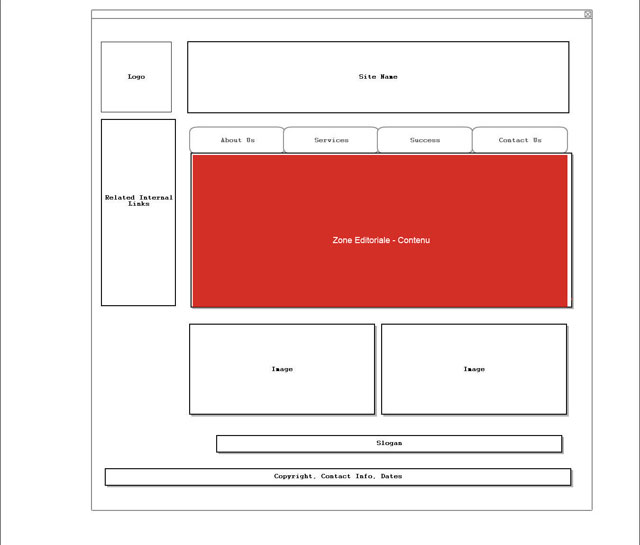
Il s’agit de la zone en rouge qui contient un contenu spécifique à la page. Les autres zones : entête, menus, barres latérales, pied de page … étant le plus souvent répétées sur toutes les pages.
On considère que cette zone, spécifique à la page, contient l’information la plus importante. De la même façon, et comme on le suppose depuis de nombreuses années, les liens de cette zone seraient considérés comme plus importants, du point de vue SEO, que les liens des autres zones de la page, appelés liens « structurels ».
Pour vous faire une idée, voici ce que dit Olivier Andrieu (spécialiste SEO bien connu) à propos des liens contextuels et structurels dans un article datant déjà de 2007.
Par ailleurs, en vous focalisant sur les liens contextuels, il vous sera plus facilement possible de tester si le maillage interne de votre site répond aux critères de la structure en « silos » ou en « cocons sémantiques ». La notion de cocon sémantique a été développée par Laurent Bourrelly (autre spécialiste SEO bien connu).
Afin de récupérer ces liens contextuels, nous allons modifier le crawler « NetworkRcrawler » que nous avions présenté précédemment dans notre article « Créer un graphe de site Web avec R ».
Par ailleurs, dans cette exemple nous testerons notre site https://www.anakeyn.com – au hasard 🙂 .
Logiciel R
Comme dans nos autres articles traitant de R, nous vous invitons à télécharger Le Logiciel R sur ce site https://cran.r-project.org/, ainsi que l’environnement de développement RStudio ici : https://www.rstudio.com/products/rstudio/download/.
Logiciel Gephi
Ici, nous avons décidé d’utiliser Gephi pour la partie « Graphe » de l’article. Gephi est gratuit et open source et vous pouvez le télécharger sur Gephi.org. Gephi est compatible avec Windows, Mac OS X et Linux.
Code Source
Vous pouvez copier/coller les morceaux de code source dans un script R pour les tester.
Vous pouvez aussi récupérer gratuitement le code source en entier dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-r-recuperation-liens-contextuels/
Parties non modifiés
La partie chargement de l’environnement ne change pas :
#'
#'
#'
#Packages à installer une fois.
#install.packages("Rcrawler")
#install.packages("igraph")
#install.packages("foreach")
#install.packages("doParallel")
#install.packages("data.table")
#install.packages("gdata")
#install.packages("xml2")
#install.packages("httr")
#Bibliothèques à charger.
library(Rcrawler) #Notamment pour Linkparamsfilter...
library(doParallel) #Notamment pour parallel::makeCluster
library(data.table) #Notamment pour %like% %in% ...
library(igraph) #Notamment graph.data.frame() ...
library(xml2) #Notamment pour read_html
library(httr) #pour GET, content ...
#
Ainsi que les fonctions NetworkRobotParser
#' NetworkRobotParser modifie RobotParser qui générait une erreur d'encoding on rajoute MyEncod.
#' RobotParser fetch and parse robots.txt
#'
#' This function fetch and parse robots.txt file of the website which is specified in the first argument and return the list of correspending rules .
#' @param website character, url of the website which rules have to be extracted .
#' @param useragent character, the useragent of the crawler
#' @return
#' return a list of three elements, the first is a character vector of Disallowed directories, the third is a Boolean value which is TRUE if the user agent of the crawler is blocked.
#' @import httr
#' @export
#'
#' @examples
#'
#' RobotParser("http://www.glofile.com","AgentX")
#' #Return robot.txt rules and check whether AgentX is blocked or not.
#'
#'
NetworkRobotParser <- function(website, useragent, Encod="UTF-8") {
URLrobot<-paste(website,"/robots.txt", sep = "")
bots<-GET(URLrobot, user_agent("Mozilla/5.0 (Windows NT 6.3; WOW64; rv:42.0) Gecko/20100101 Firefox/42.0"),timeout(5))
#PR Ajout de Encod
MyEncod <- trimws(gsub("charset=", "", unlist(strsplit(bots$headers$'content-type', ";"))[2]))
if (is.null(MyEncod) || is.na(MyEncod) ) MyEncod <- Encod
bots<-as.character(content(bots, as="text", encoding = MyEncod)) #pour éviter erreur d encoding
write(bots, file = "robots.txt")
bots <- readLines("robots.txt") # dans le repertoire du site
if (missing(useragent)) useragent<-"NetworkRcrawler"
useragent <- c(useragent, "*")
ua_positions <- which(grepl( "[Uu]ser-[Aa]gent:[ ].+", bots))
Disallow_dir<-vector()
allow_dir<-vector()
for (i in 1:length(useragent)){
if (useragent[i] == "*") useragent[i]<-"\\*"
Gua_pos <- which(grepl(paste("[Uu]ser-[Aa]gent:[ ]{0,}", useragent[i], "$", sep=""),bots))
if (length(Gua_pos)!=0 ){
Gua_rules_start <- Gua_pos+1
Gua_rules_end <- ua_positions[which(ua_positions==Gua_pos)+1]-1
if(is.na(Gua_rules_end)) Gua_rules_end<- length(bots)
Gua_rules <- bots[Gua_rules_start:Gua_rules_end]
Disallow_rules<-Gua_rules[grep("[Dd]isallow",Gua_rules)]
Disallow_dir<-c(Disallow_dir,gsub(".*\\:.","",Disallow_rules))
allow_rules<-Gua_rules[grep("^[Aa]llow",Gua_rules)]
allow_dir<-c(allow_dir,gsub(".*\\:.","",allow_rules))
}
}
if ("/" %in% Disallow_dir){
Blocked=TRUE
print ("This bot is blocked from the site")} else{ Blocked=FALSE }
Rules<-list(Allow=allow_dir,Disallow=Disallow_dir,Blocked=Blocked )
return (Rules)
}
ET Networking Normalisation :
#'
#'
#' NetworkLinkNormalization :modification de LinkNormalization :
#' on ne renvoie pas des liens uniques mais multiples : le dédoublonnement des liens doit se faire lors de
#' l'étude du réseau avec igraph.
#' correction aussi pour les liens avec # et mailto:, callto: et tel: qui étaient renvoyés.
#'
#' A function that take a URL _charachter_ as input, and transforms it into a canonical form.
#' @param links character, the URL to Normalize.
#' @param current character, The URL of the current page source of the link.
#' @return
#' return the simhash as a nmeric value
#' @author salim khalilc corrigé par Pierre Rouarch
#' @details
#' This funcion call an external java class
#' @export
#'
#' @examples
#'
#' # Normalize a set of links
#'
#' links<-c("http://www.twitter.com/share?url=http://glofile.com/page.html",
#' "/finance/banks/page-2017.html",
#' "./section/subscription.php",
#' "//section/",
#' "www.glofile.com/home/",
#' "glofile.com/sport/foot/page.html",
#' "sub.glofile.com/index.php",
#' "http://glofile.com/page.html#1"
#' )
#'
#' links<-LinkNormalization(links,"http://glofile.com" )
#'
#'
NetworkLinkNormalization<-function(links, current){
protocole<-strsplit(current, "/")[[c(1,1)]]
base <- strsplit(gsub("http://|https://", "", current), "/")[[c(1, 1)]]
base2 <- strsplit(gsub("http://|https://|www\\.", "", current), "/")[[c(1, 1)]]
rlinks<-c();
#base <- paste(base, "/", sep="")
for(t in 1:length(links)){
if (!is.null(links[t]) && length(links[t]) == 1){ #s'il y a qq chose
if (!is.na(links[t])){ #pas NA
if(substr(links[t],1,2)!="//"){ #si ne commence pas par //
if(sum(gregexpr("http", links[t], fixed=TRUE)[[1]] > 0)<2) { #Si un seul http
# remove spaces
if(grepl("^\\s|\\s+$",links[t])) {
links[t]<-gsub("^\\s|\\s+$", "", links[t] , perl=TRUE)
}
#if starts with # remplace par url courante
if (substr(links[t],1,1)=="#"){
links[t]<- current } #on est sut la même page (PR)
#if starts with / add base
if (substr(links[t],1,1)=="/"){
links[t]<-paste0(protocole,"//",base,links[t]) }
#if starts with ./ add base
if (substr(links[t],1,2)=="./") {
# la url current se termine par /
if(substring(current, nchar(current)) == "/"){
links[t]<-paste0(current,gsub("\\./", "",links[t]))
# si non
} else {
links[t]<-paste0(current,gsub("\\./", "/",links[t]))
}
}
if(substr(current,1,10)=="http://www" || substr(current,1,11)=="https://www") { #si on a un protocole + www sur la page courante.
if(substr(links[t],1,10)!="http://www" && substr(links[t],1,11)!="https://www" && substr(links[t],1,8)!="https://" && substr(links[t],1,7)!="http://" ){
if (substr(links[t],1,3)=="www") {
links[t]<-paste0(protocole,"//",links[t])
} else {
#tests liens particulier sans protocole http://
if(substr(links[t],1,7)!="mailto:" && substr(links[t],1,7)!="callto:" && substr(links[t],1,4)!="tel:") {
links[t]<-paste0(protocole,"//www.",links[t])
}
}
}
}else { #à priori pas de http sans www dans current
if(substr(links[t],1,7)!="http://" && substr(links[t],1,8)!="https://" ){
#test liens cas particuliers sans protocole http://
if(substr(links[t],1,7)!="mailto:" && substr(links[t],1,7)!="callto:" && substr(links[t],1,4)!="tel:") {
links[t]<-paste0(protocole,"//",links[t])
}
}
}
if(grepl("#",links[t])){links[t]<-gsub("\\#(.*)","",links[t])} #on vire ce qu'il y a derrière le #
rlinks <- c(rlinks,links[t]) #ajout du lien au paquet de liens
}
}
}
}
}
#rlinks<-unique(rlinks) #NON : garder tous les liens, pas d'unicité.
return (rlinks)
}
Récupération des liens contextuels avec NetworkRcrawler
Dans cette partie, il s’agit d’indiquer au crawler d’aller récupérer les liens contextuels dans des zones spécifiques des pages.
Heureusement pour nous, les différentes zones des pages de sites Web sont repérables par des balises dans le code HTML des pages (enfin en général…).
Pour revenir au schéma précédent d’une page, la zone qui nous intéresse peut être indiquée par une balise spécifique.

Sur l’image la balise qui indique la zone où trouver les liens contextuels et qui nous intéresse démarre à la balise « <div id= »main »> ».
Bon, dans la réalité, c’est un petit peu plus complexe et il se peut que les zones que vous recherchez n’aient pas toutes les mêmes balises selon les pages. Pour les rechercher il faut afficher le code source de votre page dans un navigateur (en général en tapant « Ctrl+U »).
Voici par exemple le code source HTML de la page d’accueil d’Anakeyn :
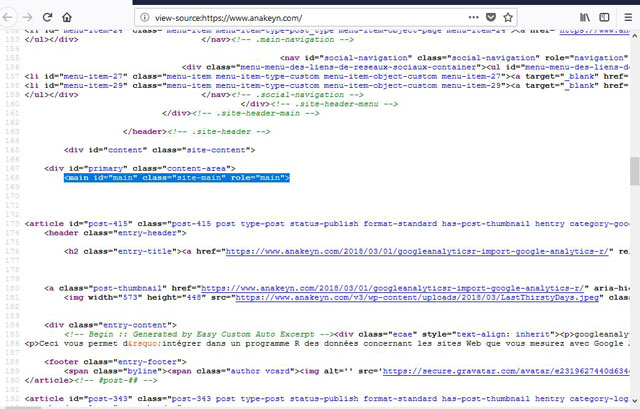
J’ai surligné en bleu la balise que j’ai repérée et qui m’intéresse : « <main id= »main » class= »site-main » role= »main »> »
Vous devrez vérifier sur les différents types de pages : Accueil, catégories, articles, listes, achats… quels sont les balises qui vous intéressent pour récupérer les liens contextuels.
Dans le cas d’Anakeyn nous en avons identifiées 4. Ce n’est finalement pas beaucoup car le site est divisé en 3 sites : l’actuel et 2 sites anciens et qui ont chacun un thème différent de WordPress.
Au final les balises sélectionnées sont les suivantes :
- « <main id= »main » class= »site-main » role= »main »> »
- « <div class= »entry-content article »> »
- « <div id= »ot-main-container »> »
- « <div class= »clearfix container »> »
Revenons au code source de NetworkRcrawler, pour identifier les zones à rechercher nous avons ajouté une variable XPathLinksAreaNodes contenant les balises à rechercher au format
xPath
#'
#' NetworkRcrawler (modification de Rcrawler par Pierre Rouarch pour limiter le nombre de page crawlées et éviter
#' une attente trop longue) :
#' NetworkRcrawler a pour objectif de créer un réseau de pages de site exploitable par iGraph
#'
#' Version 1.01
#' Ajout du paramètre XPathLinksAreaNodes : (vecteur de chaines de caractères au format xpath ) pour indiquer les zones pour rechercher des liens.
#' # attention on ne parse qu'une seule zone, le repérage se fait dans l'ordre déterminé par le vecteur.
#' Exemple : c( "main" , "//div[@class=\"main-container\"]" , #"//main[@class=\"main\"]")
#'
#' a vous d'identifier les zones "principales" que vous souhaitez cibler pour éviter les
#' liens de menus et de bas de page par exemple
#' Attention si la zone ciblée est vide sur une page les liens sont récupérés
#' sur toute la page (pour éviter un arrêt du crawl)
#' Version 1.0
#'
#' #' Modification vs Rcrawler :
#' Ajout du paramètre MaxPagesParsed pour limiter les pages "parsées" et y passer la nuit
#' Ajout du Paramètres IndexErrPages pour récupérér des pages avec status autre que 200
#' On utilise GET() plutôt que LinkExtractor car LinkExtractor ne nous renvoyait pas les infos voulues
#' notamment les redirections.
#' Récupération du contenu de la page dans pkg.env$GraphNodes plutôt que passer par des fichiers externes
#' La valeur de pkg.env$GraphEdges$Weight est à 1 et non pas à la valeur du level de la page comme précédemment.
#'
#'
#' Simplification vs Rcrawler :
#' Suppression de l'enregistrement des fichiers *.html pour gagner en performance
#' Nous avons aussi supprimer les paramètres d'extraction qui ne nous semblent pas pertinents à ce
#' stade : Comme le contenu est passé à travers de NetwNodes$Content les extractions de contenus
#' peuvent(doivent?) se faire en dehors de la construction du Réseau de pages à proprement parlé.
#'
#' Paramètres conservés vs Rcrawler
#' @param Website character, the root URL of the website to crawl and scrape.
#' @param no_cores integer, specify the number of clusters (logical cpu) for parallel crawling, by default it's the numbers of available cores.
#' @param no_conn integer, it's the number of concurrent connections per one core, by default it takes the same value of no_cores.
#' @param MaxDepth integer, repsents the max deph level for the crawler, this is not the file depth in a directory structure, but 1+ number of links between this document and root document, default to 10.
#' @param RequestsDelay integer, The time interval between each round of parallel http requests, in seconds used to avoid overload the website server. default to 0.
#' @param Obeyrobots boolean, if TRUE, the crawler will parse the website\'s robots.txt file and obey its rules allowed and disallowed directories.
#' @param Useragent character, the User-Agent HTTP header that is supplied with any HTTP requests made by this function.it is important to simulate different browser's user-agent to continue crawling without getting banned.
#' @param Encod character, set the website caharacter encoding, by default the crawler will automatically detect the website defined character encoding.
#' @param Timeout integer, the maximum request time, the number of seconds to wait for a response until giving up, in order to prevent wasting time waiting for responses from slow servers or huge pages, default to 5 sec.
#' @param URLlenlimit integer, the maximum URL length limit to crawl, to avoid spider traps; default to 255.
#' @param urlExtfilter character's vector, by default the crawler avoid irrelevant files for data scraping such us xml,js,css,pdf,zip ...etc, it's not recommanded to change the default value until you can provide all the list of filetypes to be escaped.
#' @param ignoreUrlParams character's vector, the list of Url paremeter to be ignored during crawling .
#' @param NetwExtLinks boolean, If TRUE external hyperlinks (outlinks) also will be counted on Network edges and nodes.
#' Paramètre ajouté
#' @param MaxPagesParsed integer, Maximum de pages à Parser (Ajout PR)
#' @param XPathLinksAreaNodes character, xpath, si l'on veut cibler la zone de la page ou récupérér les liens (Ajout PR)
#' Attention si la zone n'est pas trouvé tous les liens de la page sont récupérés.
#'
#'
#' @return
#'
#' The crawling and scraping process may take a long time to finish, therefore, to avoid data loss
#' in the case that a function crashes or stopped in the middle of action, some important data are
#' exported at every iteration to R global environment:
#'
#' - NetwNodes : Dataframe with alls hyperlinks and parameters of pages founded.
#' - NetwEdges : data.frame representing edges of the network, with these column : From, To, Weight (1) and Type (1 for internal hyperlinks 2 for external hyperlinks).
#'
#' @details
#'
#' To start NetworkRcrawler (or Rcrawler) task you need the provide the root URL of the website you want to scrape, it can
#' be a domain, a subdomain or a website section (eg. http://www.domain.com, http://sub.domain.com or
#' http://www.domain.com/section/). The crawler then will go through all its internal links.
#' The process of a crawling is performed by several concurrent processes or nodes in parallel,
#' So, It is recommended to use R 64-bit version.
#'
#' For more tutorials about RCrawler check https://github.com/salimk/Rcrawler/
#'
#' For scraping complexe character content such as arabic execute Sys.setlocale("LC_CTYPE","Arabic_Saudi Arabia.1256") then set the encoding of the web page in Rcrawler function.
#'
#' If you want to learn more about web scraper/crawler architecture, functional properties and implementation using R language, Follow this link and download the published paper for free .
#'
#' Link: http://www.sciencedirect.com/science/article/pii/S2352711017300110
#'
#' Dont forget to cite Rcrawler paper:
#' Khalil, S., & Fakir, M. (2017). RCrawler: An R package for parallel web crawling and scraping. SoftwareX, 6, 98-106.
#'
#' @examples
#'
#' \dontrun{
#' NetworkRcrawler(Website ="http://www.example.com/", no_cores = 4, no_conn = 4)
#' #Crawl, index, and store web pages using 4 cores and 4 parallel requests
#' NetworkRcrawler(Website = "http://www.example.com/", no_cores=8, no_conn=8, Obeyrobots = TRUE,
#' Useragent="Mozilla 3.11")
#' # Crawl and index the website using 8 cores and 8 parallel requests with respect to
#' # robot.txt rules.
#'
#' NetworkRcrawler(Website = "http://www.example.com/" , no_cores = 4, no_conn = 4, MaxPagesParsed=50)
#' # Crawl the website using 4 cores and 4 parallel requests until the number of parsed pages reach 50
#'
#' # Using Igraph for exmaple you can plot the network by the following commands
#' library(igraph)
#' network<-graph.data.frame(NetwEdges, directed=T)
#' plot(network)
#'}
#'
#'
#' @author salim khalil modifié simplifié par Pierre Rouarch
#' @import foreach doParallel parallel data.table selectr
#' @export
#' @importFrom utils write.table
#' @importFrom utils flush.console
#'
NetworkRcrawler <- function(Website, no_cores, no_conn, MaxDepth = 10, RequestsDelay=0, Obeyrobots=FALSE,
Useragent, Encod, Timeout=5, URLlenlimit=255, urlExtfilter,
ignoreUrlParams = "", ManyPerPattern=FALSE, NetwExtLinks=FALSE,
MaxPagesParsed=500, XPathLinksAreaNodes = "" ) {
if (missing(no_cores)) no_cores<-parallel::detectCores()-1
if (missing(no_conn)) no_conn<-no_cores
if(missing(Useragent)) {Useragent="Mozilla/5.0 (Windows NT 6.3; WOW64; rv:42.0) Gecko/20100101 Firefox/42.0"}
# Récupération encoding de la page d accueil du site
if(missing(Encod)) {
Encod<- Getencoding(Website)
if (length(Encod)!=0){
if(Encod=="NULL") Encod="UTF-8" ;
} #/ if (length(Encod)!=0)
} #/ if(missing(Encod))
#Filtrer les documents/fichiers non souhaités
if(missing(urlExtfilter)) {
urlExtfilter<-c("flv","mov","swf","txt","xml","js","css","zip","gz","rar","7z","tgz","tar","z","gzip","bzip","tar","mp3","mp4","aac","wav","au","wmv","avi","mpg","mpeg","pdf","doc","docx","xls","xlsx","ppt","pptx","jpg","jpeg","png","gif","psd","ico","bmp","odt","ods","odp","odb","odg","odf")
} #/if(missing(urlExtfilter))
#Récupération du nom de domaine seul
domain<-strsplit(gsub("http://|https://|www\\.", "", Website), "/")[[c(1, 1)]]
#Lecture de Robot.txt
if (Obeyrobots) {
rules<-NetworkRobotParser(Website,Useragent, Encod = Encod)
urlbotfiler<-rules[[2]]
urlbotfiler<-gsub("^\\/", paste("http://www.",domain,"/", sep = ""), urlbotfiler , perl=TRUE)
urlbotfiler<-gsub("\\*", ".*", urlbotfiler , perl=TRUE)
} else {urlbotfiler=" "}
pkg.env <- new.env() #créé un nouvel environnement pour données locales
#Création des variables pour la data.frame des noeuds/pages pkg.env$GraphNodes
Id<-vector() #Id de page
MyUrl<-vector() #Url de la page crawlé
MyStatusPage<-vector() #Status de la page dans la boucle : discovered, crawled, parsed.
Level <- numeric() #Niveau de la page dans le site/réseau
NbIntLinks <-numeric() #Nbre de liens internes sur la page si parsée
NbExtLinks <-numeric() #Nbre de liens Externes sur la page si parsée
HttpStat<-vector() #Statut http : 200, 404
IntermediateHttpStat<-vector() #Statut http "intermédiaire" pour récupérer les redirections (301, 302)
ContentType<-vector() #Type de contenu ie : text/html ...
Encoding<-vector() #Encoding ie : UTF-8
PageType<-vector() #Type de page 1 interne, 2 externe sert aussi dans pkg.env$GraphEgdes
AreaZoneParsed <- vector() #Zone parsée
HTMLContent <- vector() #Ajouté par PR -> Contenu html de la page
#PR ajout pkg.env$GraphNodes (contient les pages parsées, crawlées et non crawlées, internes et externes)
pkg.env$GraphNodes<-data.frame(Id, MyUrl, MyStatusPage, Level, NbIntLinks, NbExtLinks, HttpStat, IntermediateHttpStat, ContentType, Encoding, PageType, AreaZoneParsed, HTMLContent)
names(pkg.env$GraphNodes) <- c("Id","Url","MyStatusPage","Level","NbIntLinks", "NbExtLinks", "HttpStat", "IntermediateHttpStat", "ContentType","Encoding", "PageType", "AreaZoneParsed", "HTMLContent")
#Création des variables pour la data.frame des liens pkg.env$GraphEdges
FromNode<-vector() #Id de la page de départ
ToNode<-vector() #Id de la page d'arrivée
Weight<-vector() #Poids du lien ici on prendra = 1
AreaZoneParsed <- vector() #Zone parsée
pkg.env$GraphEgdes<-data.frame(FromNode,ToNode,Weight,PageType, AreaZoneParsed) #Data.frame des noeuds. le poids du liens est le niveau de page d'arrivée, le Type interne externe.
names(pkg.env$GraphEgdes) <- c("From","To","Weight","PageType", "AreaZoneParsed") #Noms des variables de la data.frame.
#Autres variables intermédiaires utiles.
allpaquet<-list() #Contient les paquets de pages crawlées parsées.
Links<-vector() #Liste des liens sur la page
#initialisation des noeuds/pages.
pkg.env$GraphNodes[1,"Id"] <- 1 #initialisation Id 1ere page
pkg.env$GraphNodes[1,"Url"] <- Website #initialisation Url fournie par nous.
pkg.env$GraphNodes[1, "MyStatusPage"] <- "discovered"
pkg.env$GraphNodes[1,"Level"] <- 0 #initialisation (niveau de première page à 0)
pkg.env$GraphNodes[1,"PageType"] <- 1 #Page Interne.
pkg.env$GraphNodes[1,"Encoding"] <- Encod #Récupéré par GetEncoding ou forcé à UTF-8
pkg.env$GraphNodes[1, "AreaZoneParsed"] <- "Accueil"
#On force IndexErrPages pour récupérer les errreurs http
IndexErrPages<-c(200, 300, 301, 302, 404, 403, 500, 501, 502, 503, NULL, NA, "")
lev<-0 #Niveau du site à 0 (première page)
LevelOut <- 0 #Niveau des pages du site atteint en retour de Get - mis à 0 pour pouvoir démarrer
t<-1 #index de début de paquet de pages à parser (pour GET)
i<-0 #index de pages parsées pour GET
TotalPagesParsed <- 1 #Nombre total de pages parsées.
#cluster initialisation pour pouvoir travailler sur plusieurs clusters en même temps .
cl <- makeCluster(no_cores, outfile="") #création des clusters nombre no_cores fourni par nos soins.
registerDoParallel(cl)
clusterEvalQ(cl, library(httr)) #Pour la fonction GET
############################################################################################
# Utilisation de GET() plutot que LinkExtractor :
############################################################################################
#Tant qu'il reste des pages à crawler :
while (t<=nrow(pkg.env$GraphNodes)) {
# Calcul du nombre de pages à crawler !
rest<-nrow(pkg.env$GraphNodes)-t #Rest = nombre de pages restantes à crawler = nombre de pages - pointeur actuel de début de paquet
#Si le nombre de connections simultanées est inférieur au nombre de pages restantes à crawler.
if (no_conn<=rest){
l<-t+no_conn-1 #la limite du prochain paquet de pages à crawler = pointeur actuel + nombre de connections - 1
} else {
l<-t+rest #Sinon la limite = pointeur + reste
}
#Délai
if (RequestsDelay!=0) {
Sys.sleep(RequestsDelay)
}
#Extraction d'un paquet de pages de t pointeur actuel à l limite
allGetResponse <- foreach(i=t:l, .verbose=FALSE, .inorder=FALSE, .errorhandling='pass') %dopar%
{
TheUrl <- pkg.env$GraphNodes[i,"Url"] #url de la page à crawler.
GET(url = TheUrl, timeout = Timeout )
} #/ foreach
#On regarde ce que l'on a récupéré de GET
for (s in 1:length(allGetResponse)) {
TheUrl <- pkg.env$GraphNodes[t+s-1,"Url"] #t+s-1 pointeur courant dans GrapNodes
if (!is.null(allGetResponse[[s]])) { #Est-ce que l'on a une réponse pour cette page ?
if (!is.null(allGetResponse[[s]]$status_code)) { #Est-ce que l'on a un status pour cette page ?
#Recupération des données de la page crawlée et/ou parsée.
#Si on n'avait pas déjà HttpStat
if (is.null(pkg.env$GraphNodes[t+s-1, "HttpStat"]) || is.na(pkg.env$GraphNodes[t+s-1, "HttpStat"])) {
if (!is.null(allGetResponse[[s]]$status_code) )
pkg.env$GraphNodes[t+s-1, "HttpStat"] <- allGetResponse[[s]]$status_code
} #/if (is.null(pkg.env$GraphNodes[t+s-1, "HttpStat"]) || is.na(pkg.env$GraphNodes[t+s-1, "HttpStat"]))
#pour les status de redirections.
if (!is.null(allGetResponse[[s]]$all_headers[[1]]$status)) pkg.env$GraphNodes[t+s-1, "IntermediateHttpStat"] <- allGetResponse[[s]]$all_headers[[1]]$status
# Si on n'avait pas déjà ContentType
if (is.null(pkg.env$GraphNodes[t+s-1, "ContentType"]) || is.na(pkg.env$GraphNodes[t+s-1, "ContentType"]))
{ pkg.env$GraphNodes[t+s-1, "ContentType"] <- trimws(unlist(strsplit(allGetResponse[[s]]$headers$'content-type', ";"))[1]) }
# Si on n'avait pas déjà Encoding
if (is.null(pkg.env$GraphNodes[t+s-1, "Encoding"]) || is.na(pkg.env$GraphNodes[t+s-1, "Encoding"]))
{ pkg.env$GraphNodes[t+s-1, "Encoding"] <- trimws(gsub("charset=", "", unlist(strsplit(allGetResponse[[s]]$headers$'content-type', ";"))[2])) }
#On récupère tout le contenu HTML
MyEncod <- pkg.env$GraphNodes[t+s-1, "Encoding"] #Verifie que l'on a un encoding auparavent
if (is.null(MyEncod) || is.na(MyEncod) ) MyEncod <- Encod
pkg.env$GraphNodes[t+s-1, "HTMLContent"] <- content(allGetResponse[[s]], "text", encoding=MyEncod) #Récupere contenu HTML
#Marque la page comme "crawlée"
pkg.env$GraphNodes[t+s-1, "MyStatusPage"] <- "crawled"
#Niveau de cette page dans le réseau.
LevelOut <- pkg.env$GraphNodes[t+s-1, "Level"] #Level de la page crawlée
#Parsing !!! Ici rechercher les liens si c'est autorisé et page interne.
if (MaxDepth>=LevelOut && TotalPagesParsed <= MaxPagesParsed && pkg.env$GraphNodes[t+s-1, "PageType"]==1) { #Récupérer des liens
pkg.env$GraphNodes[t+s-1, "MyStatusPage"] <- "parsed"
TotalPagesParsed <- TotalPagesParsed + 1 #Total des pages parsées (pour la prochaine itération)
AreaZoneParsed <- "" #Zone parsé non définie
x <- read_html(x = content(allGetResponse[[s]], "text")) #objet html
if (length(XPathLinksAreaNodes) != 0) {
for (i in 1:length(XPathLinksAreaNodes)) {
LinksArea <- xml2::xml_find_all(x, XPathLinksAreaNodes[i])
if (length(LinksArea) != 0)
{
cat("XPathLinksAreaNodes founded",XPathLinksAreaNodes[i],"\n")
x <- LinksArea
AreaZoneParsed <- XPathLinksAreaNodes[i] #Zone parsé repérée
break
} #if length(linksArea)
} #/for
}
links<-xml2::xml_find_all(x, "//a/@href") #trouver les liens
links<-as.vector(paste(links)) #Vectorisation des liens
links<-gsub(" href=\"(.*)\"", "\\1", links) #on vire href
#Va récupérer les liens normalisés.
links<-NetworkLinkNormalization(links,TheUrl) #revient avec les protocoles http/https sauf liens mailto etc.
#on ne conserve que les liens avec http
links<-links[links %like% "http" ]
# Ignore Url parameters
links<-sapply(links , function(x) Linkparamsfilter(x, ignoreUrlParams), USE.NAMES = FALSE)
# Link robots.txt filter
if (!missing(urlbotfiler)) links<-links[!links %like% paste(urlbotfiler,collapse="|") ]
#Récupération des liens internes et des liens externes
IntLinks <- vector() #Vecteur des liens internes
ExtLinks <- vector() #Vecteur des liens externes.
if(length(links)!=0) {
for(iLinks in 1:length(links)){
if (!is.na(links[iLinks])){
#limit length URL to 255
if( nchar(links[iLinks])<=URLlenlimit) {
ext<-tools::file_ext(sub("\\?.+", "", basename(links[iLinks])))
#Filtre eliminer les liens externes , le lien source lui meme, les lien avec diese ,
#les types de fichier filtrer, les lien tres longs , les liens de type share
#if(grepl(domain,links[iLinks]) && !(links[iLinks] %in% IntLinks) && !(ext %in% urlExtfilter)){
#Finalement on garde les liens déjà dans dans la liste
#(c'est à iGraph de voir si on souhaite simplifier le graphe)
if(grepl(domain,links[iLinks]) && !(ext %in% urlExtfilter)){ #on n'enlève que les liens hors domaine et à filtrer.
#C'est un lien interne
IntLinks<-c(IntLinks,links[iLinks])
} #/if(!(ext %in% urlExtfilter))
if(NetwExtLinks){ #/si je veux les liens externes en plus (les doublons seront gérés par iGraph)
#if ( !grepl(domain,links[iLinks]) && !(links[iLinks] %in% ExtLinks) && !(ext %in% urlExtfilter)){
if ( !grepl(domain,links[iLinks]) && !(ext %in% urlExtfilter)){
ExtLinks<-c(ExtLinks,links[iLinks])
} #/if ( !grepl(domain,links[iLinks]) && !(links[iLinks] %in% ExtLinks) && !(ext %in% urlExtfilter))
} #if(ExternalLInks)
} # / if( nchar(links[iLinks])<=URLlenlimit)
} #/if (!is.na(links[iLinks]))
} #/for(iLinks in 1:length(links))
} #/if(length(links)!=0)
#Sauvegarde du nombre de liens internes sur la page parsée
pkg.env$GraphNodes[t+s-1, "NbIntLinks"] <- length(IntLinks)
#Sauvegarde du nombnre de liens externes sur la page parsée
pkg.env$GraphNodes[t+s-1, "NbExtLinks"] <- length(ExtLinks)
#Sauvegarde des liens internes dans GraphNodes et GraphEdges :
for(NodeElm in IntLinks) { #Sauvegarde des nouveaux noeuds dans GraphNodes et des liens dans GraphEdges
#Ajout dans le graphe des Nodes des nouvelles pages internes découvertes
if (! (NodeElm %in% pkg.env$GraphNodes[, "Url"] )) {
NewIndexNodes <- nrow(pkg.env$GraphNodes) + 1
pkg.env$GraphNodes[NewIndexNodes, "Id"] <- NewIndexNodes
pkg.env$GraphNodes[NewIndexNodes, "Url"] <- NodeElm #Récupération de l'URL.
pkg.env$GraphNodes[NewIndexNodes, "MyStatusPage"] <- "discovered" #Nouvelle page interne découverte.
pkg.env$GraphNodes[NewIndexNodes, "Level"] <- LevelOut+1 #Niveau de la page parsée + 1
pkg.env$GraphNodes[NewIndexNodes, "PageType"] <- 1 #Page Interne
pkg.env$GraphNodes[NewIndexNodes, "AreaZoneParsed"] <- AreaZoneParsed #code de zone parsée
} #/ if (! (NodeElm %in% pkg.env$GraphNodes[, "Url"] ))
#Sauvegarde des liens.
#position de la page de départ
posNodeFrom<-t+s-1
#position de la page d arrivée
posNodeTo <- chmatch(NodeElm, pkg.env$GraphNodes[,"Url"])
#Insertion dans la data.frame des liens #type de lien 1 interne - Weight <- 1 (avant: LevelOut +1)
pkg.env$GraphEgdes[nrow(pkg.env$GraphEgdes) + 1,]<-c(posNodeFrom,posNodeTo,1,1, AreaZoneParsed)
} #/for(NodeElm in IntLinks)
#Insertion des liens externes dans GraphNodes et GraphEdges.
for(NodeElm in ExtLinks){
#Ajout dans le graphe des Nodes des nouvelles pages externes repérées
if (! (NodeElm %in% pkg.env$GraphNodes[, "Url"] )) { #Si n'existe pas insérer
NewIndexNodes <- nrow(pkg.env$GraphNodes) + 1
pkg.env$GraphNodes[NewIndexNodes, "Id"] <- NewIndexNodes
pkg.env$GraphNodes[NewIndexNodes, "Url"] <- NodeElm
pkg.env$GraphNodes[NewIndexNodes, "MyStatusPage"] <- "discovered" #Nouvelle page externe découverte.
pkg.env$GraphNodes[NewIndexNodes, "Level"] <- LevelOut+1 #Niveau de la page parsée + 1
pkg.env$GraphNodes[NewIndexNodes, "PageType"] <- "2" #Page Externe
pkg.env$GraphNodes[NewIndexNodes, "AreaZoneParsed"] <- AreaZoneParsed #code de zone parsée
} #/if (! (NodeElm %in% pkg.env$GraphNodes[, "Url"] ))
#Sauvegarde des liens.
#position de la page de départ
posNodeFrom<-t+s-1
#position de la page d arrivée
posNodeTo <- chmatch(NodeElm, pkg.env$GraphNodes[,"Url"]) #
#Insertion dans la data.frame des liens #type de lien 2 externe, Weight <- 1
pkg.env$GraphEgdes[nrow(pkg.env$GraphEgdes) + 1,]<-c(posNodeFrom,posNodeTo,1,2, AreaZoneParsed)
} #/for(NodeElm in ExtLinks)
} #/if (MaxDepth>=LevelOut && TotalPagesParsed <= MaxPagesParsed && pkg.env$GraphNodes[t+s-1, "PageType"]==1)
} #/if (is.null(allGetResponse[[s]]$status_code))
} #/if (!is.null(allGetResponse[[s]]))
} #/for (s in 1:length(allGetResponse))
cat("Crawl with GET :",format(round((t/nrow(pkg.env$GraphNodes)*100), 2),nsmall = 2),"% : ",t,"to",l,"crawled from ",nrow(pkg.env$GraphNodes)," Parsed:", TotalPagesParsed-1, "\n")
t<-l+1 #Paquet suivant
#Sauvegarde des données vers l'environnement global.
assign("NetwEdges", pkg.env$GraphEgdes, envir = as.environment(1) ) #Renvoie les données Edges vers env global
assign("NetwNodes", pkg.env$GraphNodes, envir = as.environment(1) ) #Idem Nodes
} #/while (t<=nrow(pkg.env$graphNodes)
#Arret des clusters.
stopCluster(cl)
stopImplicitCluster()
rm(cl)
cat("+ Network nodes plus parameters are stored in a variable named : NetwNodes \n")
cat("+ Network edges are stored in a variable named : NetwEdges \n")
} #/NetworkRcrawler
########################################################################################
Lancement du crawl sur Anakeyn.com
On indique tout d’abord la collection de balises que l’on souhaite tester dans une variable. Ici les balises on été traduites au format xPath :
#'
#
myXPath <- c("//main[@id=\"main\"][@class=\"site-main\"][@role=\"main\"]", "//div[@class=\"entry-content article\"]",
"//div[@id=\"ot-main-container\"]", "//div[@id=\"main\"][@class=\"clearfix container\"]")
Nota bene : le programme teste les balises dans l’ordre. Dès qu’il trouve la balise sur une page il récupère les liens sur cette page dans cette balise et passe à la page suivante sans tester les balises suivantes. On peut ainsi imaginer que l’on indique des balises du plus précis au moins précis si l’on veut récupérer des liens.
Attention toutefois, pour éviter que le crawler ne s’arrête trop tôt, si celui-ci ne trouve pas les balises recherchées, il renvoit tous les liens de la page. Comme le fichier de noeuds et le fichier de liens récupérés comportent une variable indiquant la balise sur laquelle le lien a été trouvé, à charge pour vous de conserver tel ou tel type de noeud ou lien qui vous intéresse.
Indication du site et lancement du Crawler
#
#
myWebsite = "https://www.anakeyn.com"
NetworkRcrawler (Website = myWebsite , no_cores = 8, no_conn = 8,
MaxDepth = 10,
XPathLinksAreaNodes = myXPath, #pour crawler en priorité les zones de contenus contextuels.
Obeyrobots = FALSE,
Useragent = "Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv:11.0) like Gecko",
NetwExtLinks = FALSE,
MaxPagesParsed = 5000)
Ici je souhaitais récupérer tous les liens donc j’ai mis MaxPagesParsed = 5000 pour être sûr. Mais attention cela peut être un peu long.
Nettoyage des pages et des liens.
Nous allons garder uniquement que les pages et des liens qui ont été trouvées dans les balises sélectionnées.
#' # #On ne garde que les noeuds des zones ciblées. NetwNodes1 <- NetwNodes[!(NetwNodes$AreaZoneParsed==""), ] str(NetwNodes1) #pour voir #on ne garde dans le fichier de noeuds que les noeuds qui sont aussi dans les liens NetwNodes2 <- NetwNodes1[(NetwNodes1$Id %in% NetwEdges$From) & (NetwNodes1$Id %in% NetwEdges$To),] str(NetwNodes2) #pour voir #on ne garde que les liens des zones ciblées. NetwEdges1 <- NetwEdges[!(NetwEdges$AreaZoneParsed==""), ] str(NetwEdges1) #pour voir #on ne garde que les liens dont les zones From et To sont dans les noeuds. NetwEdges2 <- NetwEdges1[(NetwEdges1$From %in% NetwNodes2$Id ) & (NetwEdges1$To %in% NetwNodes2$Id ),] str(NetwEdges2) #pour voir
Mise au format de Gephi
Afin de pouvoir récupérer les données dans Gephi je transforme les données avant de les sauvegarder au format .csv.
J’enlève aussi le code source des pages pour alléger les fichiers.
#' # nohtmlNetwNodes <- NetwNodes2[,1:12] #on enlève les codes sources des noeuds pour économiser de la place. names(NetwEdges2)[1] <- "Source" #Changement du nom de colonne From en Source names(NetwEdges2)[2] <- "Target" #Changement du nom de colonne To en Target write.csv(NetwEdges2, file = "NetwEdgesAZP.csv", row.names=FALSE) write.csv(nohtmlNetwNodes, file = "nohtmlNetwNodes.csv", row.names=FALSE)
Graphe dans Gephi
Pour l’utilisation de Gephi je vous renvoie à un article précédent : Créer un graphe de site Web avec Gephi
Ici nous allons récupérer le fichier de noeuds « nohtmlNetwNodes.csv » et le fichier de liens « NetwEdgesAZP.csv ».
Dans le graphe suivant, les couleurs indiquent les zones sur lesquels ont été récupérés les liens et la taille des noeuds est fonction du PageRank interne calculé.
L’algorithme de spatialisation choisi est « Force Atlas 2 ».
le site est divisée en 3 zones : en bleu la version actuelle du site, en magenta la version 1, en vert et rouge la version 2.

Comme vous pouvez le constater, même s’il existe plus ou moins 3 zones, le site est encore un peu « foutraque ». Nous sommes encore loin d’une organisation en « cocon sémantique ». Il reste plein de liens entre les différentes zones et chacune des zones ressemble à une « patate ».
Merci pour votre attention,
Si vous avez des remarques et des suggestions n’hésitez pas à les faire en commentaires.
A bientôt,
Pierre