Partager la publication "Classification de pages Web via Deep Learning – Réseau de Neurones à propagation avant"
Précédemment, nous avions vu, dans une série d’articles l’utilisation d’algorithmes de Machine Learning pour la classification de pages Web.
Il s’agissait, dans notre cas, de déterminer la position d’une page dans Google sur un mot clé en fonction de caractéristiques liées à la page ou au site.
Dans cette nouvelle série d’articles, nous allons nous intéresser maintenant aux méthodes de Deep Learning ou apprentissage profond pour résoudre notre problème.
Présentation du Deep Learning et des réseaux de neurones :
Deep Learning vs Machine Learning
Le Deep Learning ou apprentissage profond fait partie des outils de Machine Learning ou apprentissage machine.
Dans cette famille, on retrouve les fameux réseaux de neurones que nous utiliserons ici.
Le terme « profond » vient du fait que l’on peut empiler des couches de réseaux de neurones. On parle ainsi de couches cachées ce qui rend ces modèles mystérieux pour le profane.
Il existe différents type de réseaux de neurones. Dans cet article nous utiliserons un réseau de neurones à propagation avant ou FeedForward.
Ce type de réseaux indique que l’information va toujours vers l’avant. C’est à dire d’une couche du réseau vers une autre. On parle aussi de réseaux Perceptron multicouches.
Voici un schéma simplifié de réseau de neurones FeedForward avec 1 couche cachée :

Pourquoi un Réseau de Neurones ?
L’idée derrière ce concept était de pouvoir imiter le fonctionnement des neurones naturels et du cerveau humain (?).
Dans un circuit neuronal naturel, les neurones s’échangent des informations au travers de connexions synaptiques (chimiques ou électriques) activées ou non.
Dans les années 1950 les chercheurs ont créé ce que l’on appelle un « neurone formel » c’est à dire une représentation mathématique d’un neurone :
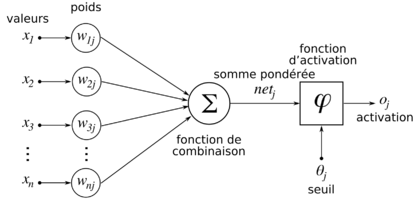
Le principe est le suivant :
- Le neurone reçoit des informations (X) avec des importances pondérées (W), appelées aussi « poids synaptiques ».
- Il fait un calcul sur ces informations et ces poids, par exemple une somme pondérée : c’est la fonction de combinaison.
- Ensuite le neurone passe l’information à une fonction d’activation qui va se déclencher en fonction d’un seuil et qui va transmettre l’information au reste du réseau ou non.
Dans les réseaux FeedForward, ou Perceptron multicouches, la fonction de combinaison est une fonction linéaire. La fonction d’activation introduit de la non-linéarité dans le système.
Fonctions d’activation
Il existe de nombreuses formes de fonctions d’activation comme vous pouvez le voir dans Wikipédia. Dans cet article nous n’utiliserons que 2 types de fonctions d’activation courantes :
- La fonction ReLU (pour Rectifier Linear Unit ou Unité de Rectification Linéaire) que nous utiliserons dans les couches cachées.
- La fonction sigmoïde qui est utilisée dans les problèmes de classification binaire en sortie du réseau de neurones. Rem : comme notre cas où l’on veut savoir si l’on est en première page de Google ou non.
Représentation des fonctions sigmoïde et ReLU :
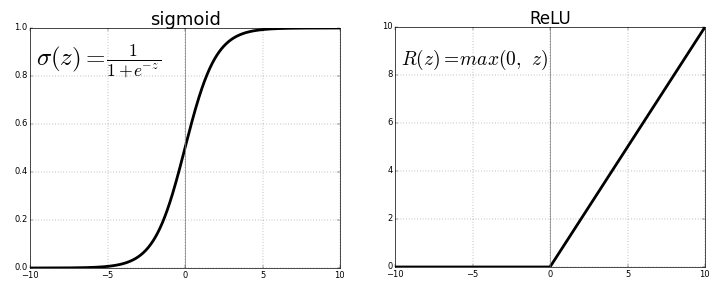
Rétropropagation
Pour apprendre le réseau a besoin de minimiser ses erreurs.
Pour essayer de faire simple le principe est toujours le même :
- Le réseau apprend sur des données d’entrainement (dont on connait les résultats) et valide sur des données de test (dont on connait aussi les résultats)
- Puis il mesure les erreurs au moyen de la fonction de perte déterminée par le Data Scientist selon le problème.
- Ensuite il modifie les poids synaptiques (W) qui entrainent les plus fortes erreurs*
- Puis recommence l’entrainement du modèle jusqu’à arriver à une stabilisation des erreurs.
*On parle de rétropropagation car la mesure des erreurs se fait de la dernière couche du réseau à la première couche du réseau (en sens inverse de l’information).
Pour en savoir plus sur la backpropagation et la méthode de descente de gradient voir sur Wikipédia par exemple.
Nous allons en rester là pour les aspects théoriques, car le but n’est pas de faire un cours de mathématiques, mais de comprendre les principes généraux pour pouvoir utiliser les outils logiciels.
De quoi aurons nous besoin ?
Python Anaconda 3.6
Comme précédemment, téléchargez la version de Python Anaconda qui vous convient selon votre ordinateur.
Attention ! la version actuelle est la 3.7 et la bibliothèque TensorFlow nécessaire aux réseaux de neurones ne fonctionne pas correctement avec celle-ci.
Il faut downgrader Anaconda en Python 3.6. Voir notre article sur l‘installation de TensorFlow et Keras (ainsi que les commentaires).
TensorFlow 1.5 et Keras 2
La version de Tensorflow actuelle est la 2.0 toutefois celle-ci a été compilée pour des processeurs modernes qui ne sont pas compatible avec ma machine. J’ai donc utilisé TensorFlow 1.5 et Keras 2 pour être compatible.
La ligne de commande dans le prompt d’Anaconda pour installer Tensorflow et Keras est la suivante (c’est la même dans l’environnement de base ou dans un environnement spécifique) :
conda install tensorflow=1.5 keras=2 -c defaults -c conda-forge
Jeu de données
Téléchargez le jeu de données Mots-clés/Pages/Positions/Caractéristiques sur notre GitHub à l’adresse : https://raw.githubusercontent.com/Anakeyn/GSCCompetitorsDeepLearning1/master/dfQPPS7.csv
Code Source
Vous pouvez copier/coller les morceaux de code source suivants soit télécharger le tout gratuitement dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-python-classification-via-reseau-de-neurones-feedforward/
Chargement des bibliothèques utiles
Si vous n’avez pas installé les bibliothèques nécessaires dans votre environnement, n’oubliez pas de les installer à partir du prompt d’Anaconda avec les commandes conda install ou pip.
# -*- coding: utf-8 -*- """ Created on Sun Nov 24 10:29:18 2019 @author: Pierre """ ########################################################################## # GSCCompetitorsDL1 # Auteur : Pierre Rouarch - Licence GPL 3 # Classification des pages Web dans Google sur un mot clé en fonctions de caractérisitiques # Deep Learning sur un univers de concurrence 1 # Utilisation d'un réseau de neurones feedforward simple pour une classification binaire # Données enrichiees via Scraping précédemment. ##################################################################################### ################################################################### # On démarre ici ################################################################### #Chargement des bibliothèques générales utiles #Remarque installer les bibliothèques manquantes via conda install #import numpy as np #pour les vecteurs et tableaux notamment import matplotlib.pyplot as plt #pour les graphiques #import scipy as sp #pour l'analyse statistique - non utilisé. import pandas as pd #pour les Dataframes ou tableaux de données import os #scaler from sklearn.preprocessing import StandardScaler #Autres Scalers pas forcément utile mais peuvent être testés. #from sklearn.preprocessing import MinMaxScaler #fom sklearn.preprocessing import minmax_scale #from sklearn.preprocessing import MaxAbsScaler #from sklearn.preprocessing import StandardScaler #from sklearn.preprocessing import RobustScaler #from sklearn.preprocessing import Normalizer #from sklearn.preprocessing import QuantileTransformer #rom sklearn.preprocessing import PowerTransformer from sklearn.model_selection import train_test_split #for Deep Learning from keras import models from keras import layers print(os.getcwd()) #verif my path #mon répertoire sur ma machine - nécessaire quand on fait tourner le programme #par morceaux dans Spyder. #myPath = "C:/Users/Pierre/MyPath" #os.chdir(myPath) #modification du path #print(os.getcwd()) #verif
Récupération du jeu de données
On récupère le même jeu de données que précédemment pour le Machine Learning et on crée un set d’entrainement et un set de test.
#############################################################
# Deep Learning sur les données enrichies après scraping
#############################################################
#Lecture des données suite à scraping ############
dfQPPS8 = pd.read_csv("dfQPPS7.csv")
dfQPPS8.info(verbose=True) # 12194 enregistrements.
dfQPPS8.reset_index(inplace=True, drop=True)
#Variables explicatives
X = dfQPPS8[['isHttps', 'level',
'lenWebSite', 'lenTokensWebSite', 'lenTokensQueryInWebSiteFrequency', 'sumTFIDFWebSiteFrequency',
'lenPath', 'lenTokensPath', 'lenTokensQueryInPathFrequency' , 'sumTFIDFPathFrequency',
'lenTitle', 'lenTokensTitle', 'lenTokensQueryInTitleFrequency', 'sumTFIDFTitleFrequency',
'lenDescription', 'lenTokensDescription', 'lenTokensQueryInDescriptionFrequency', 'sumTFIDFDescriptionFrequency',
'lenH1', 'lenTokensH1', 'lenTokensQueryInH1Frequency' , 'sumTFIDFH1Frequency',
'lenH2', 'lenTokensH2', 'lenTokensQueryInH2Frequency' , 'sumTFIDFH2Frequency',
'lenH3', 'lenTokensH3', 'lenTokensQueryInH3Frequency' , 'sumTFIDFH3Frequency',
'lenH4', 'lenTokensH4','lenTokensQueryInH4Frequency', 'sumTFIDFH4Frequency',
'lenH5', 'lenTokensH5', 'lenTokensQueryInH5Frequency', 'sumTFIDFH5Frequency',
'lenH6', 'lenTokensH6', 'lenTokensQueryInH6Frequency', 'sumTFIDFH6Frequency',
'lenB', 'lenTokensB', 'lenTokensQueryInBFrequency', 'sumTFIDFBFrequency',
'lenEM', 'lenTokensEM', 'lenTokensQueryInEMFrequency', 'sumTFIDFEMFrequency',
'lenStrong', 'lenTokensStrong', 'lenTokensQueryInStrongFrequency', 'sumTFIDFStrongFrequency',
'lenBody', 'lenTokensBody', 'lenTokensQueryInBodyFrequency', 'sumTFIDFBodyFrequency',
'elapsedTime', 'nbrInternalLinks', 'nbrExternalLinks' ]] #variables explicatives
X.info()
y = dfQPPS8['group'] #variable à expliquer,
##Sciikit Learn Scalers - choose one
scaler = StandardScaler() # Standard Scaler
#scaler = MinMaxScaler() #pas mieux
#scaler = minmax_scale()
#scaler = MaxAbsScaler()
#scaler = RobustScaler() #moins bon que standard scaler
#scaler = Normalizer()
#scaler = QuantileTransformer()
#scaler = PowerTransformer()
scaler.fit(X)
X_Scaled = pd.DataFrame(scaler.transform(X.values), columns=X.columns, index=X.index)
X_Scaled.info()
#check some values
plt.hist( X_Scaled['isHttps'])
plt.hist( X_Scaled['lenTokensWebSite'])
#Manual Scaled - same as StandardScaler
#X_Mean = X
#X_Mean -= X_Mean.mean(axis=0)
#X_ManualScaled = X_Mean
#X_ManualScaled /= X_Mean.std(axis=0)
#plt.hist( X_ManualScaled['isHttps'])
#plt.hist( X_ManualScaled['lenTokensWebSite'])
#X_Scaled = X_ManualScaled
########################################################
#on choisit random_state = 42 en hommage à La grande question sur la vie, l'univers et le reste
#dans "Le Guide du voyageur galactique" par Douglas Adams. Ceci afin d'avoir le même split
#tout au long de notre étude.
X_train, X_test, y_train, y_test = train_test_split(X_Scaled,y, random_state=42)
X_train.shape
#(9145, 61)
Réseau de Neurones FeedForward
On crée le réseau de neurones à proprement parlé. Ici nous avons créé un réseau très simple avec 2 couches cachées de 40 neurones.
Pourquoi 40 Neurones ?
Selon des règles empiriques il est conseillé de suivre les recommandations suivantes pour déterminer le nombre de neurones dans une couche cachée (quitte à modifier ce nombre par la suite si cela ne convient pas) :
- Le nombre de neurones dans une couche cachée doit être entre la taille de la couche d’entrée et la taille de la couche de sortie.
- Le nombre de neurones doit être d’une taille de 2/3 de la somme de la taille de la couche d’entrée plus la taille de la couche de sortie.
- Le nombre de neurones dans une couche cachée ne dois pas être plus grand que 2 fois la taille de la couche d’entrée
Dans notre cas notre couche d’entrée est de 61 (qui correspond à nos variables explicatives) et la taille de sortie est 1 (on veut savoir si notre page est dans les 10 premières ou non donc c’est codé sur une valeur) :
D’où (61+1)*2/3 = 41,33 donc on va prendre 40 pour commencer.
############################################################## #Réseau de Neurones unitsNumber = 40 #nombre de neurones par couche cachée #(~2/3*( 61+1)) #Define Sample Neural Network Model with 2 hidden layers model = models.Sequential() # model.add(layers.Dense(unitsNumber, activation='relu', input_shape=(61,))) model.add(layers.Dense(unitsNumber, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) #pour avoir une probabilité en sortie # compile the model with custom metrics #Choose one optimizer : rmsprop is generally a good enough choice. model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc']) #you could check #model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc']) #model.compile(optimizer='sgd',loss='binary_crossentropy',metrics=['acc']) #model.compile(optimizer='Nadam',loss='binary_crossentropy',metrics=['acc']) #Fit the model to data history = model.fit(X_train, y_train, epochs=30, batch_size=16, validation_data=(X_test, y_test))
Graphiques et résultats
############################################################
#Graphiques et résultats
history_dict = history.history
history_dict.keys()
# dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
acc = history_dict['acc']
val_acc = history_dict['val_acc'] #ce qui nous intéresse
epochs = range(1, len(acc) + 1)
#perte
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.savefig("QPPS8-FNN-Loss.png", bbox_inches="tight", dpi=600)
plt.show()
#précision
plt.clf()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy FNN')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.savefig("QPPS8-FNN-Accuracy.png", bbox_inches="tight", dpi=600)
plt.show() #!!!! affiche et remet à zéro => sauvegarder avant
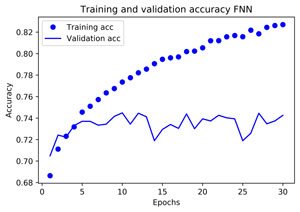
max(acc) #meilleure valeur de la précision sur le train set 0.8270092947030733
acc.index(max(acc)) #29
max(val_acc) #meilleure valeur de la précision de validation sur le test set 0.7448343719838681
#Meilleur que xgBoost non optimisé : 0.734 mais moins bien que KNN 0.7553
val_acc.index(max(val_acc)) #indice correspondant # 9
##########################################################################
# MERCI pour votre attention !
##########################################################################
#on reste dans l'IDE
#if __name__ == '__main__':
# main()
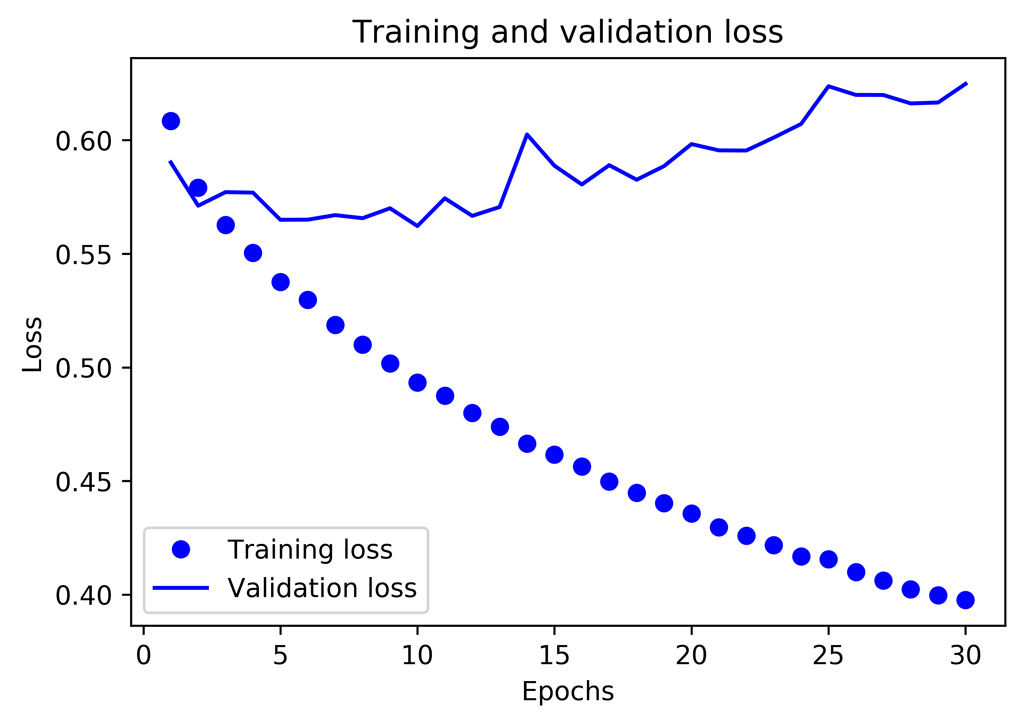
La perte diminue rapidement pour les données d’entrainement alors qu’elle augmente pour les données de test : il y a risque de sur optimisation dans ce modèle.
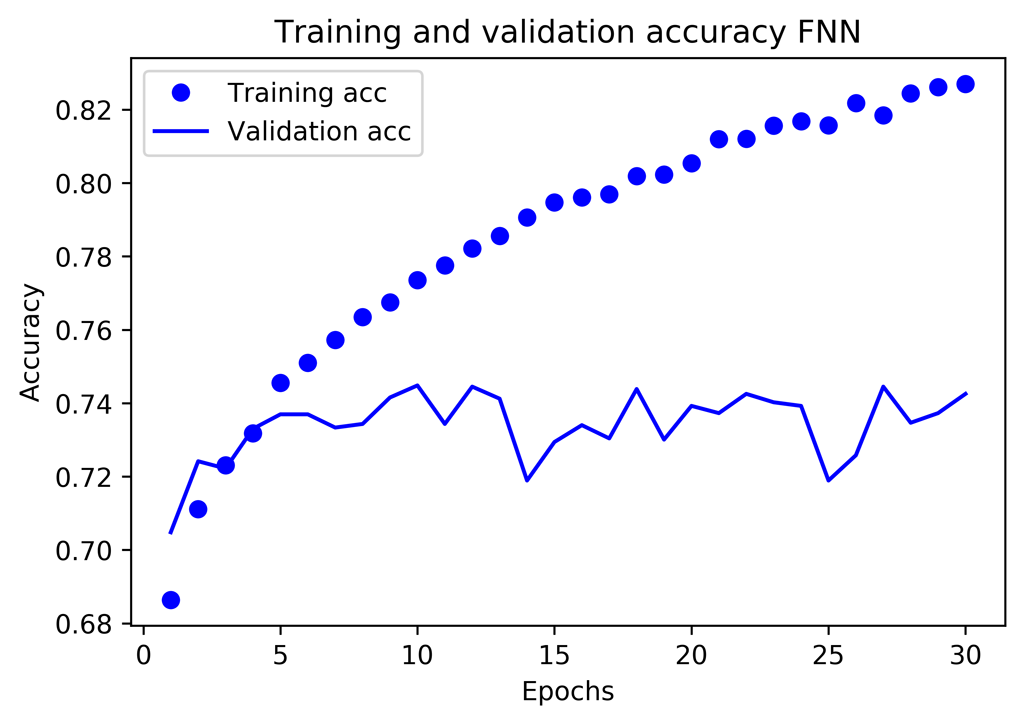
Même constat que précédemment : la précision sur les données d’entrainement augmente alors que la précision sur les données de test reste stable -> Sur optimisation potentielle.
La meilleure précision obtenue pour le set de test est de 0.7448 ce qui meilleur que ce que nous avions eu avec un XGBoost non optimisé (0.734), et ce qui est encourageant.
Voir aussi notre essai avec un réseau de neurones convolutifs.
Merci de votre attention,
Pierre