Partager la publication "Récupérer les mots-clés « Not Provided » de Google Analytics depuis Google Search Console avec Python"
Dans cet article, nous verrons comment récupérer les mots-clés dans Google Search Console afin d’enrichir les données Google Analytics « Not Provided ».
Nous procèderons pour cela avec un (petit) programme en Python.
Qu’est-ce que le « Not Provided » dans Google Analytics ?
Vous avez certainement remarqué que dans Google Analytics quand vous souhaitez connaître les mots clés par lesquels sont venus vos visiteurs à partir des moteurs de recherche, la plupart du temps vous obtenez un « Not Provided »
Regardez dans « Acquisition » -> « All traffic » -> « Channels » et choisir « organic search » :
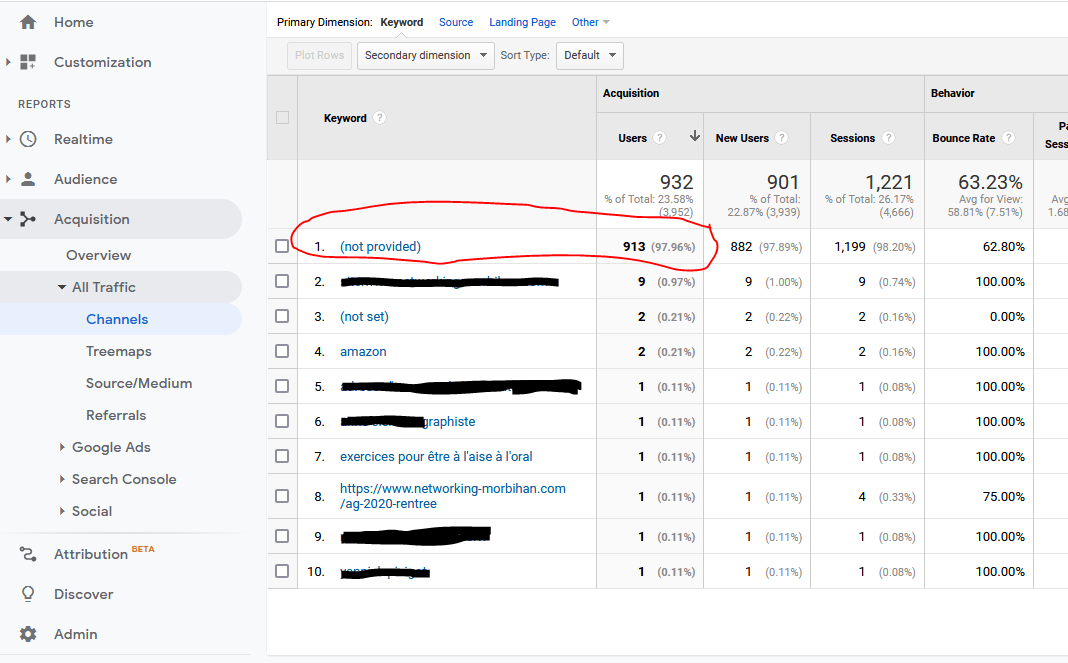
Comme vous pouvez le constater, près de 98 % des mots clés sont ici en « Not Provided », ce qui fait que cette information est inexploitable.
Il y a 10 ans, cette information était fournie par les Moteurs de Recherche, mais pour une politique de soi-disant protection des utilisateurs, cette information a été masquée depuis.
Mots Clés dans Google Search Console
Heureusement, dans l’Outil Google Search Console, il est possible de consulter la liste des mots-clés de vos visiteurs venus par Google.
Dans « Performance » vous pouvez visualiser l’ensemble des requêtes sur une période :
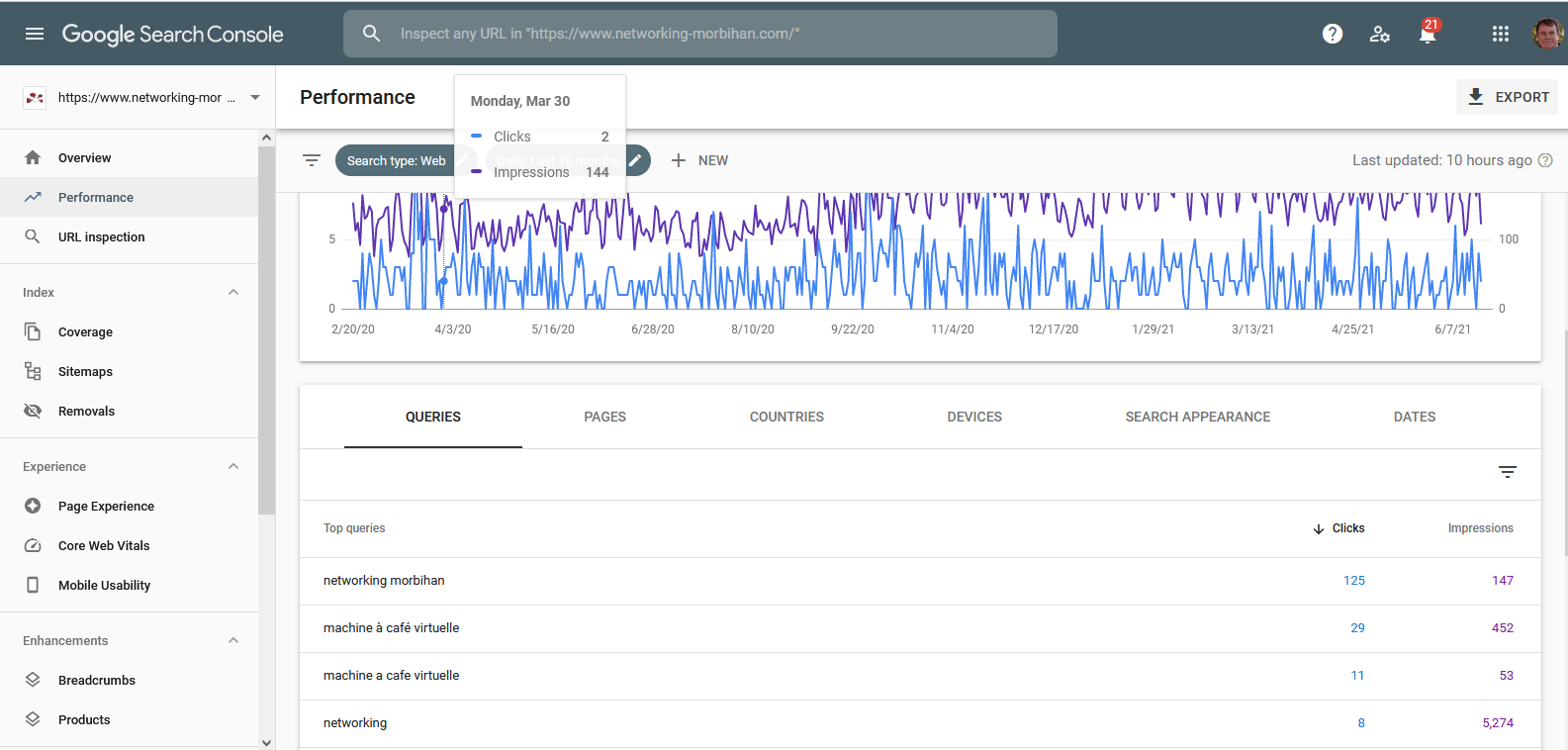
Toutefois, vous constaterez que cette information est générale et que vous ne pouvez pas relier cette information à une session d’un visiteur en particulier.
Cependant, il existe une solution permettant de rapprocher les informations de Google Analytics et de Google Search Console au moyen de leurs API respectives, grâce à un programme, ici en Python.
Création d’un projet dans la Console Développeur de Google et codes OAuth
Afin de pouvoir utiliser ces APIs nous allons créer un Projet sur la Console Développeurs de Google (à ne pas confondre avec Google Search Console) :
https://console.developers.google.com
Remarque : Google Developers Console est maintenant intégré à Google Cloud Platform et est aussi accessible à l’adresse https://console.cloud.google.com/.
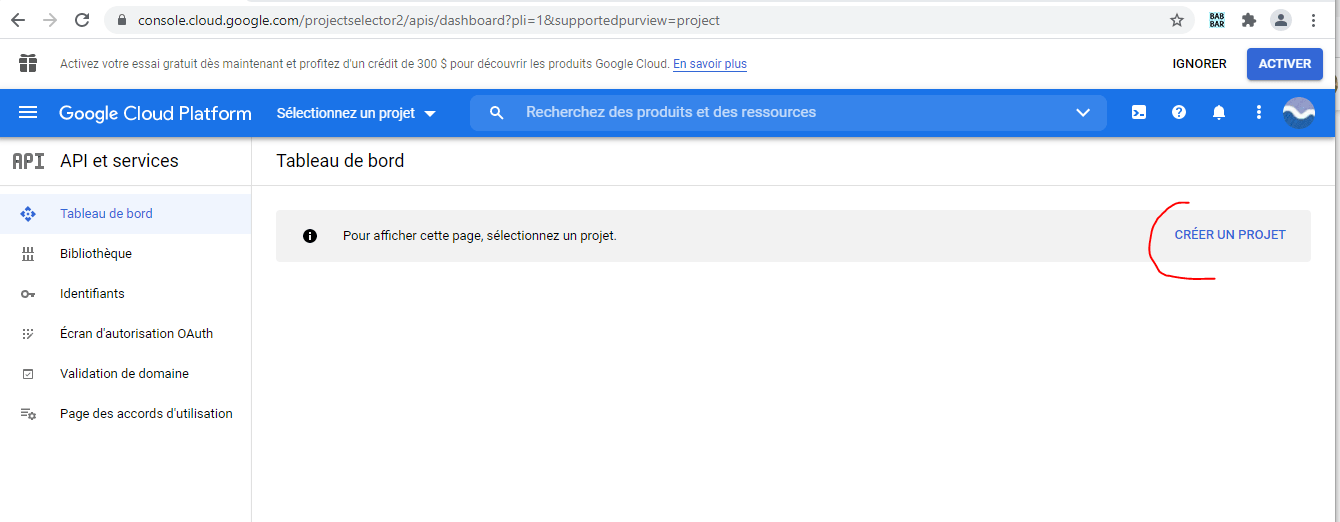
Si vous n’avez jamais créé de projet avec Google Developers Console, la page suivante du tableau de bord s’affiche. Cliquez sur « Créer un Projet »
Sinon la console s’ouvre sur le dernier projet ouvert :
Cliquez sur le nom du projet en cours pour développer la fenêtre et cliquez sur « nouveau projet » :
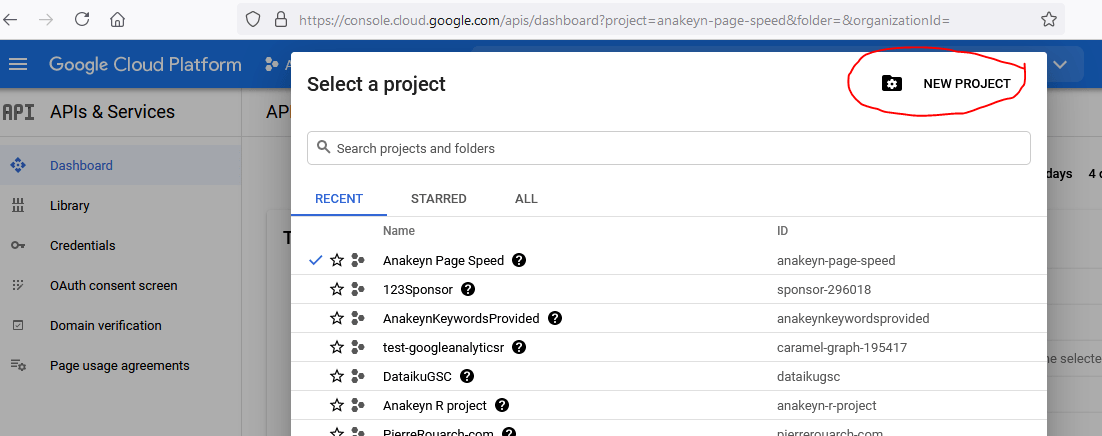
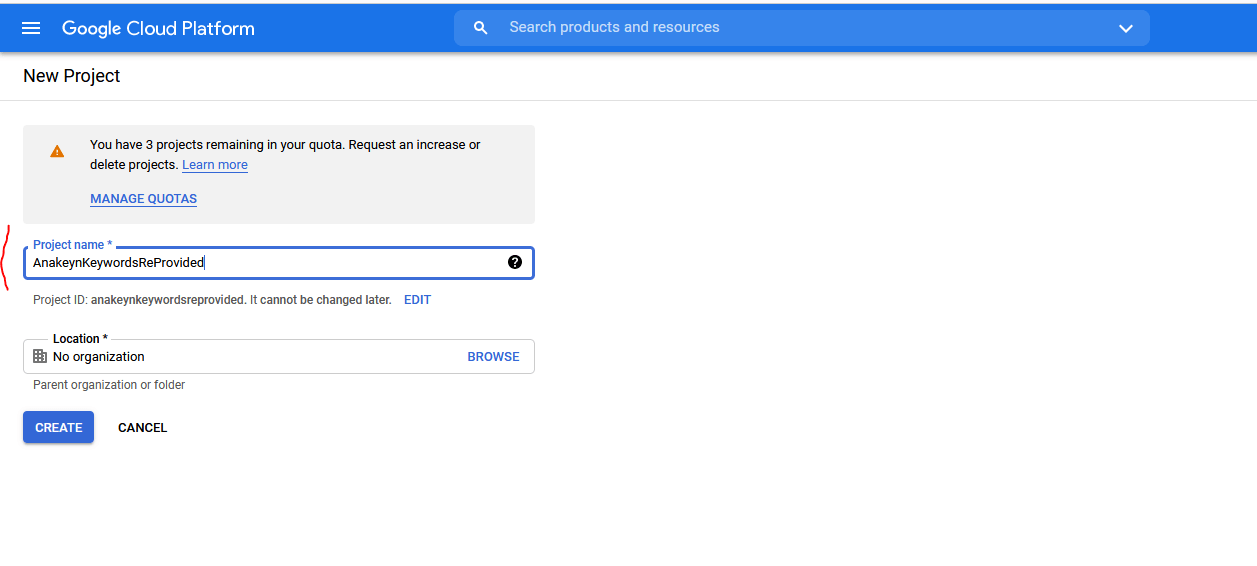
Indiquez ensuite un nom pour votre projet : par exemple ici « AnakeynKeywordsReProvided ».
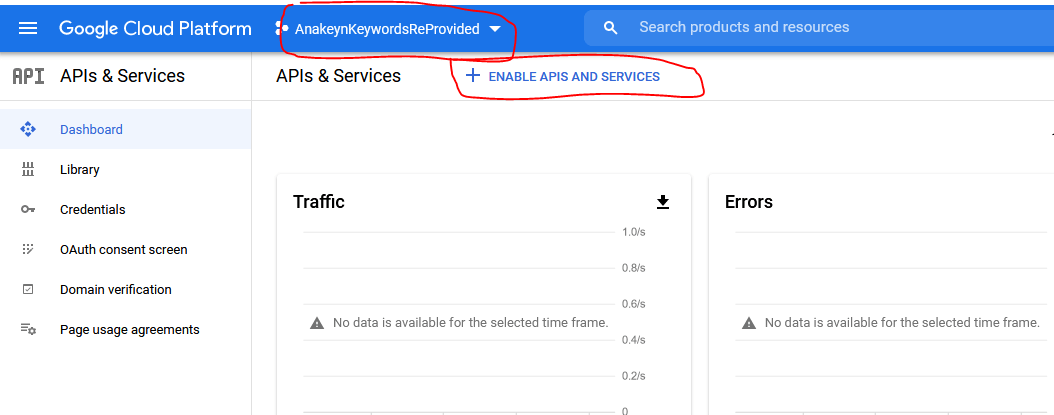
Le système revient sur le tableau de bord. Vérifiez que vous êtes sur le bon projet, ici « AnakeynKeywordsReProvided » et allez choisir vos APIs :
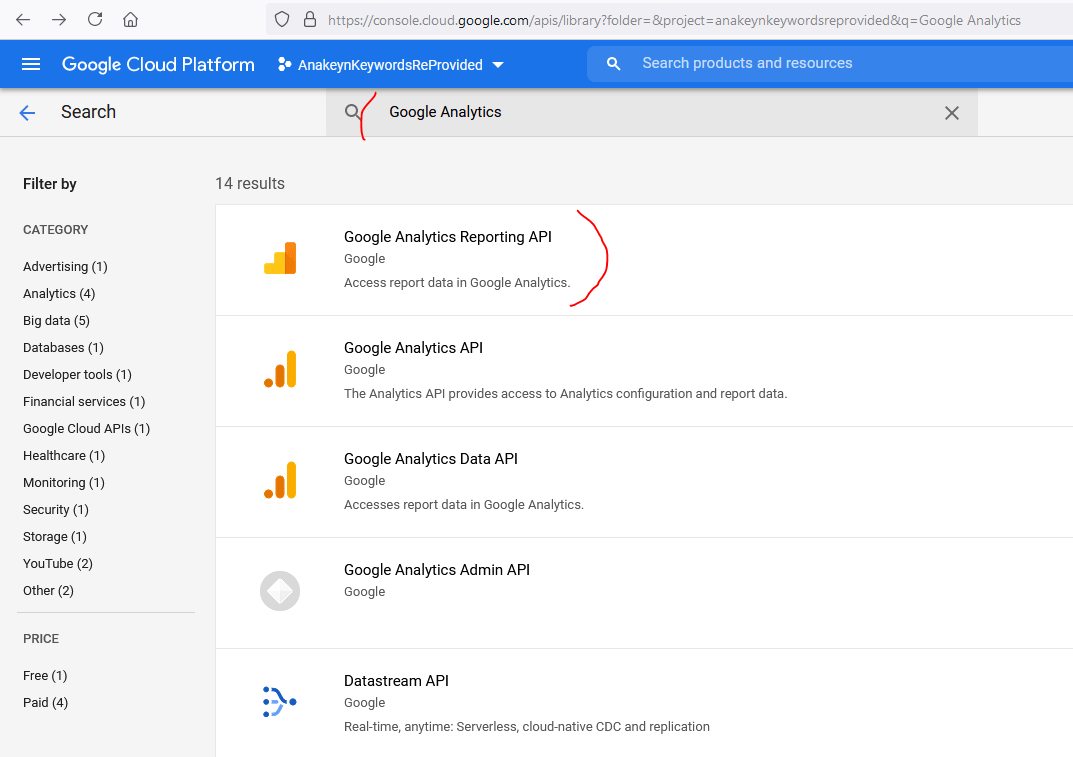
Recherchez ensuite « Google Analytics » et sélectionnez « Google Analytics Reporting API » :
Puis validez cette API :
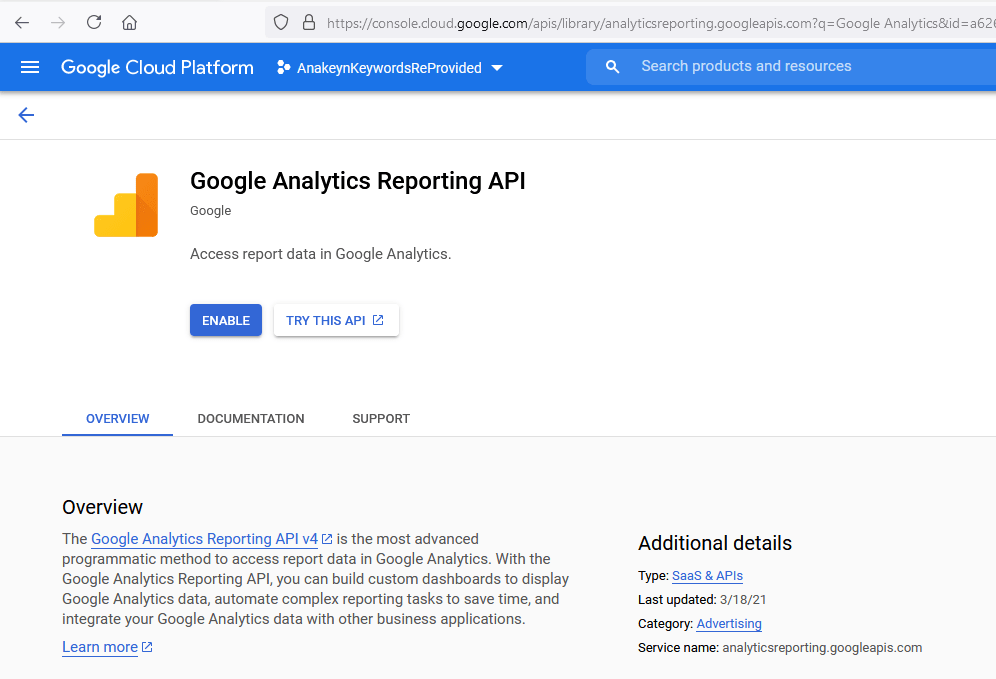
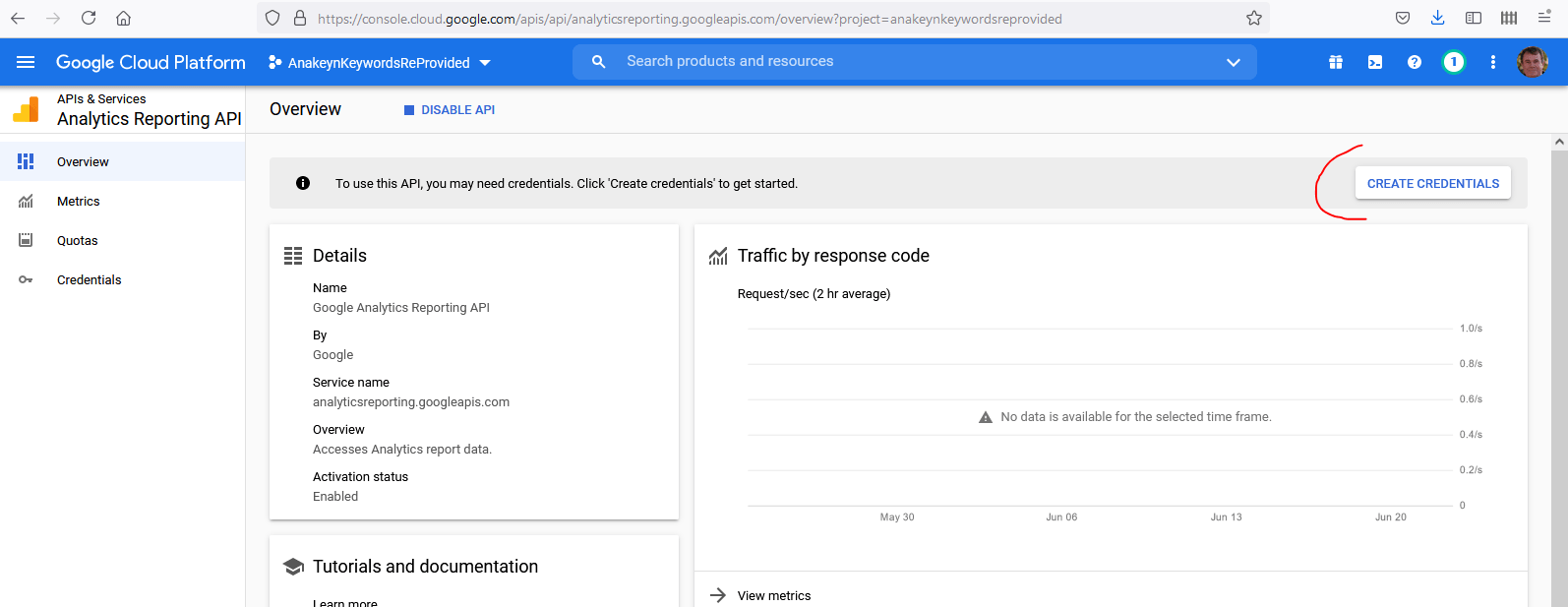
Une fois votre API validée, Google vous demande d’aller créer vos codes ou « Credentials » :
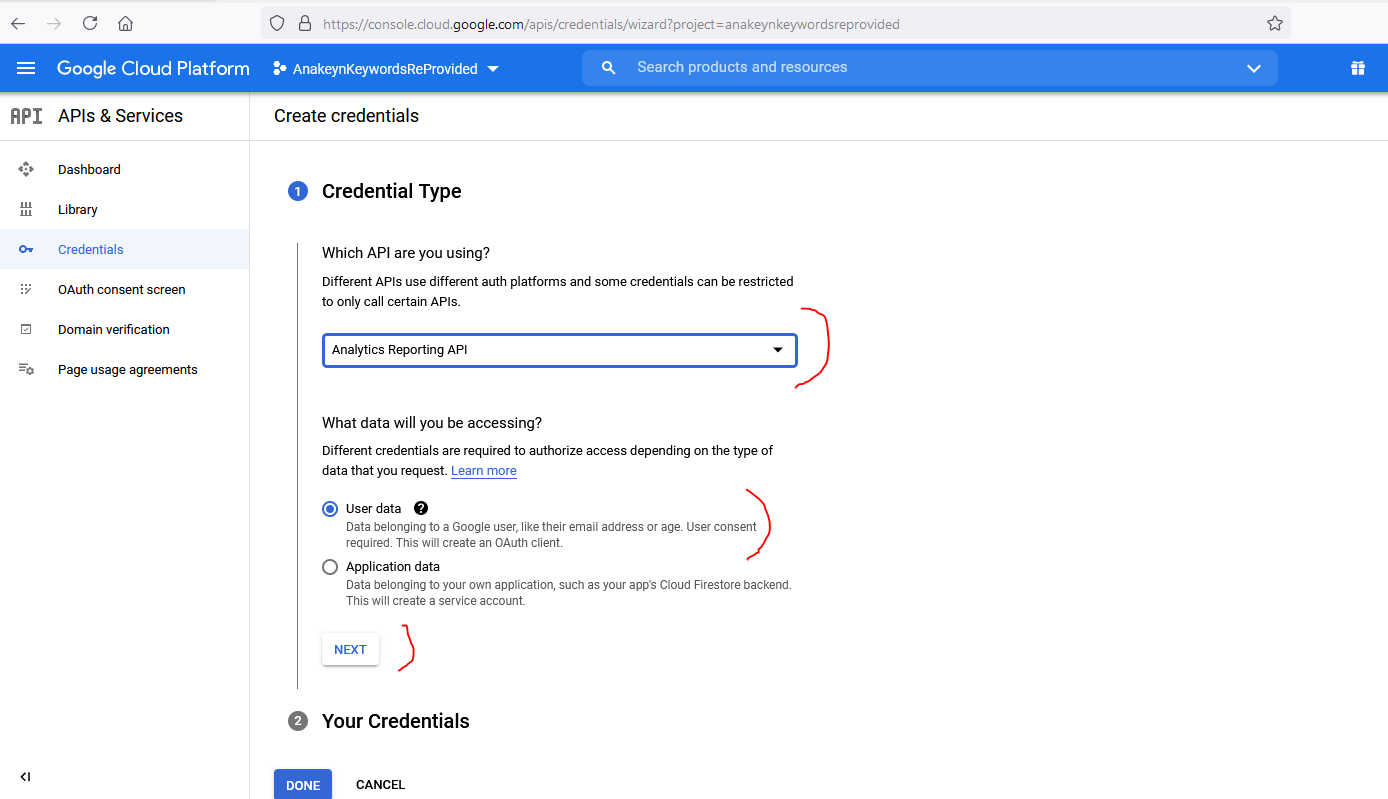
Sur la page suivante, ré-indiquez le choix de votre API, ici « Analytics Reporting API » et choisissez « User Data » – Les données Google Analytics appartenant à un utilisateur – puis appuyez sur « NEXT » :
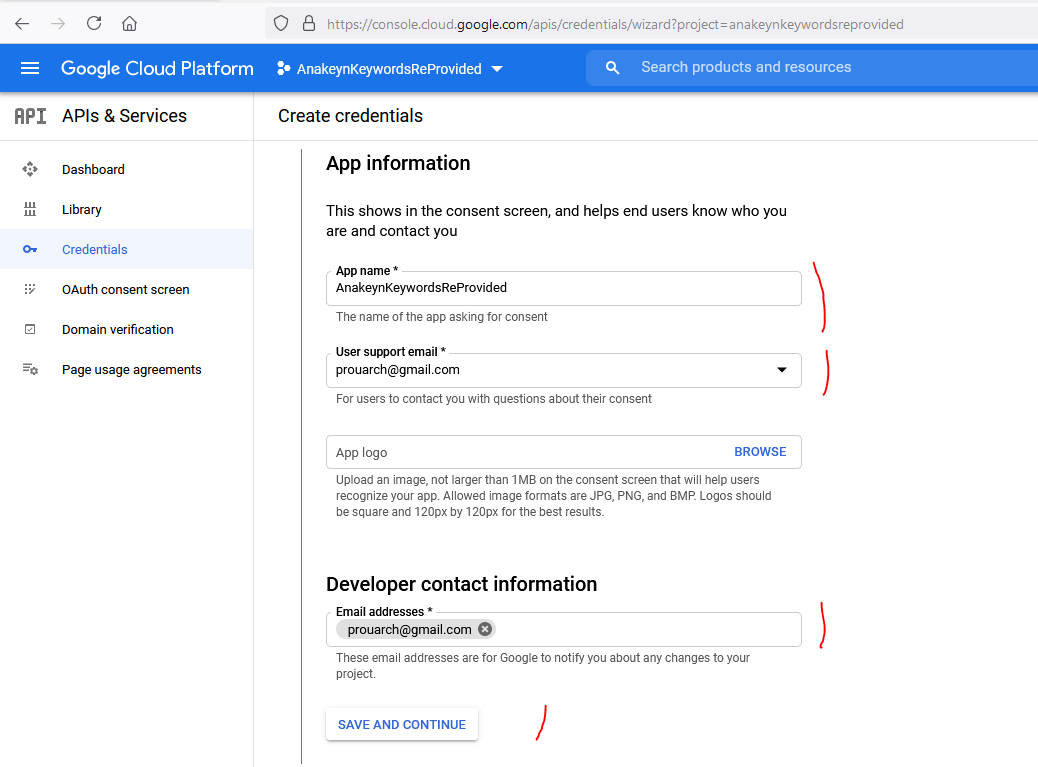
Indiquez ensuite le nom de votre application : on reprend le même nom « AnakeynKeywordsReProvided » :
Rubrique « Scopes » ou étendues de votre application. Ici c’est optionnel, et cela est de toute façon géré par le programme. Sautez cette étape :
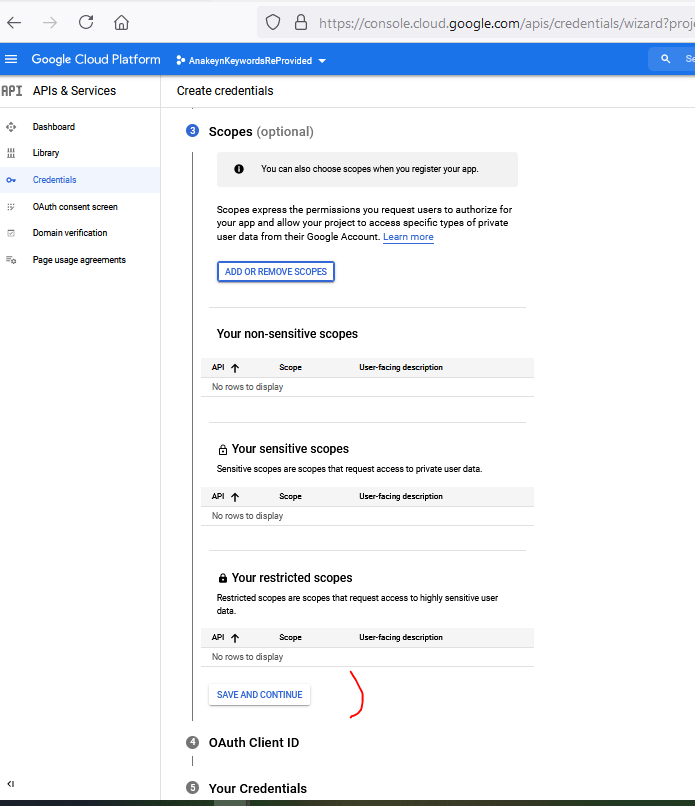
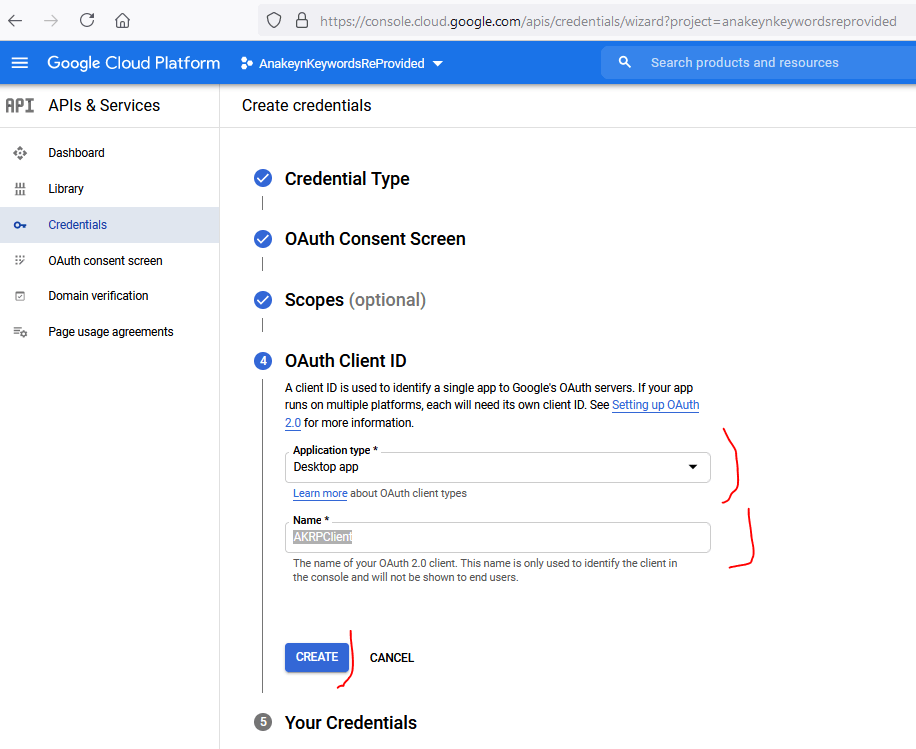
Sur la page « OAuth Client ID« , Google Nous demande le type d’application et un nom. J’indique « Desktop App » et comme nom de client quelque chose qui me rappelle mon application par exemple « AKRPClient » :
La page suivante s’affiche, cliquez directement sur « DONE«
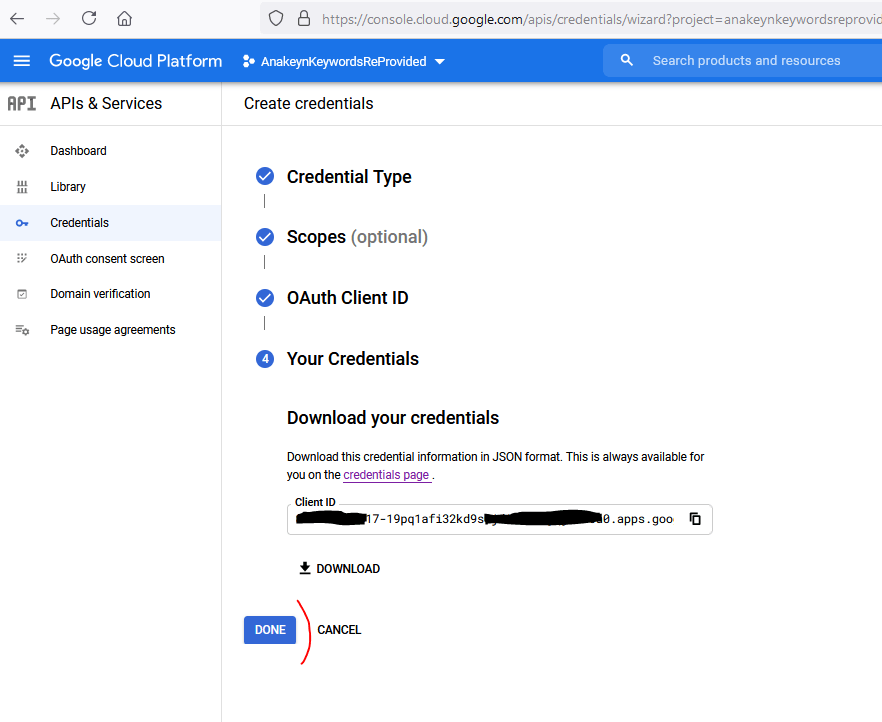
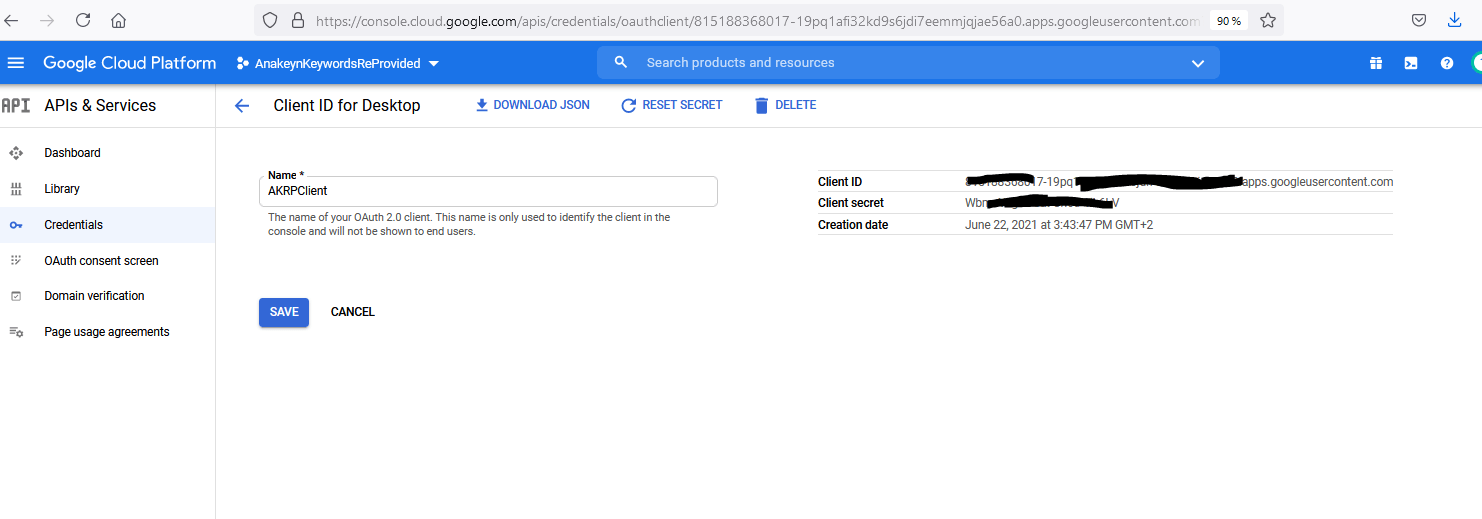
La page des « Credentials » s’affiche. Ouvrez « AKRPClient » :
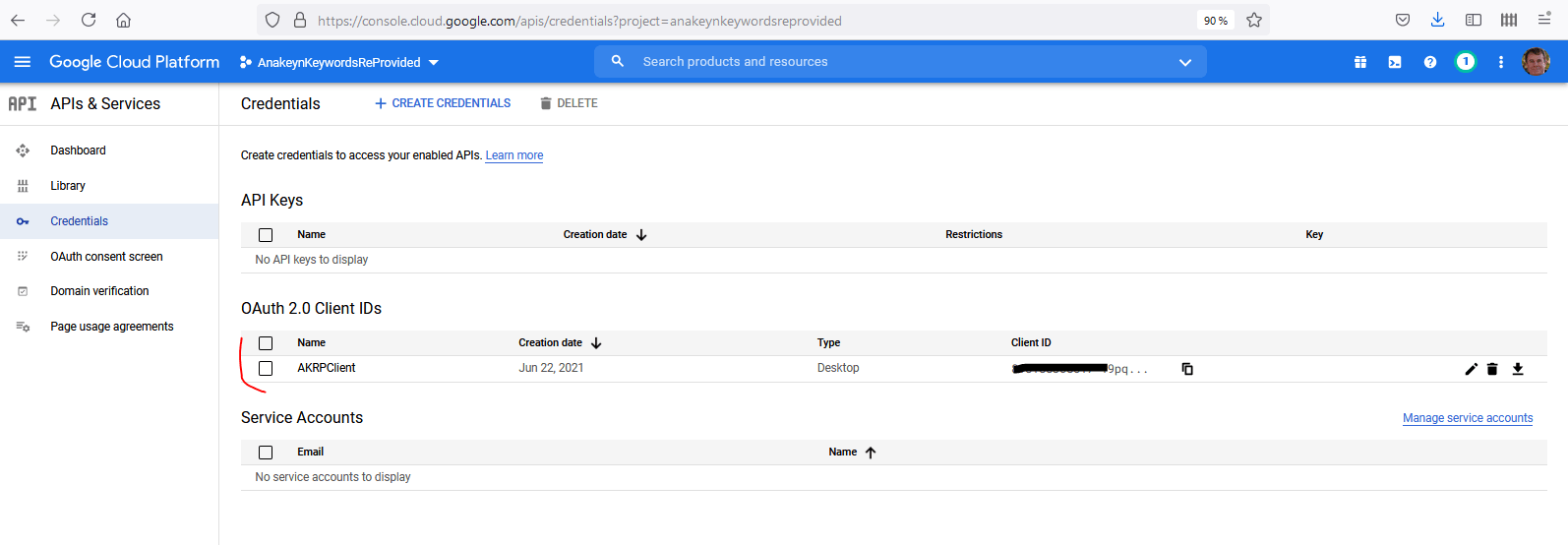
Copiez votre « Client ID » et votre « Client secret ». Vous en aurez besoin pas la suite pour notre programme Python.
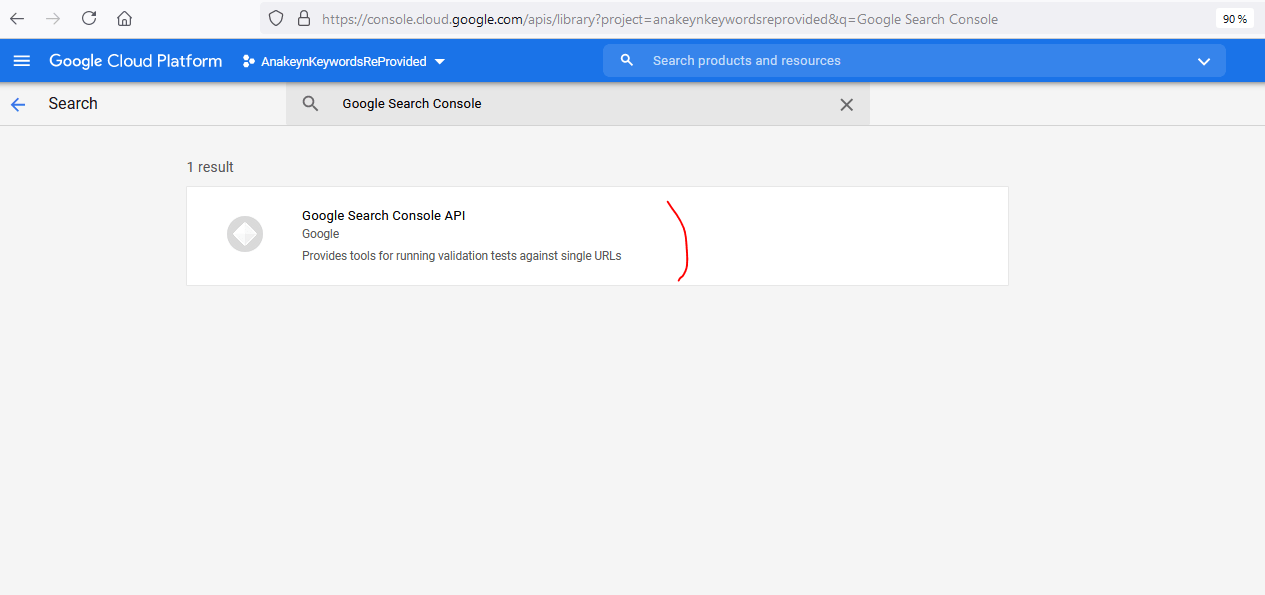
Retournez ensuite à la liste des APIs en cliquant sur « Library » dans le menu de gauche et recherchez « Coogle Search Console«
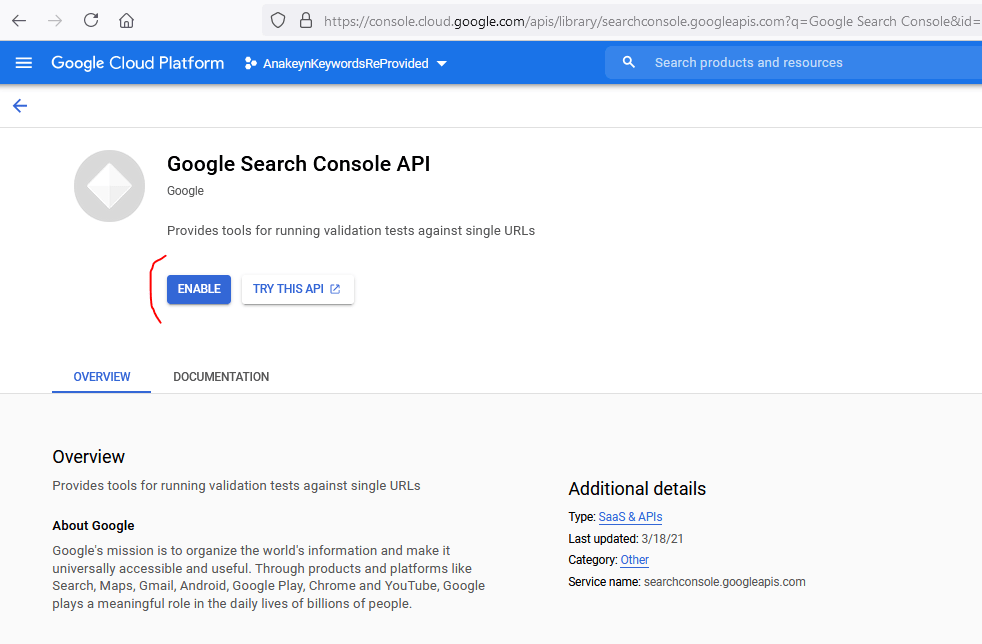
Validez ensuite l’API Google Search Console :
Revenir ensuite dans « API APIs & Services » onglet « OAuth consent Screen » : Votre application est en mode test : vous pouvez soit publier l’application soit ajouter des utilisateurs tests :
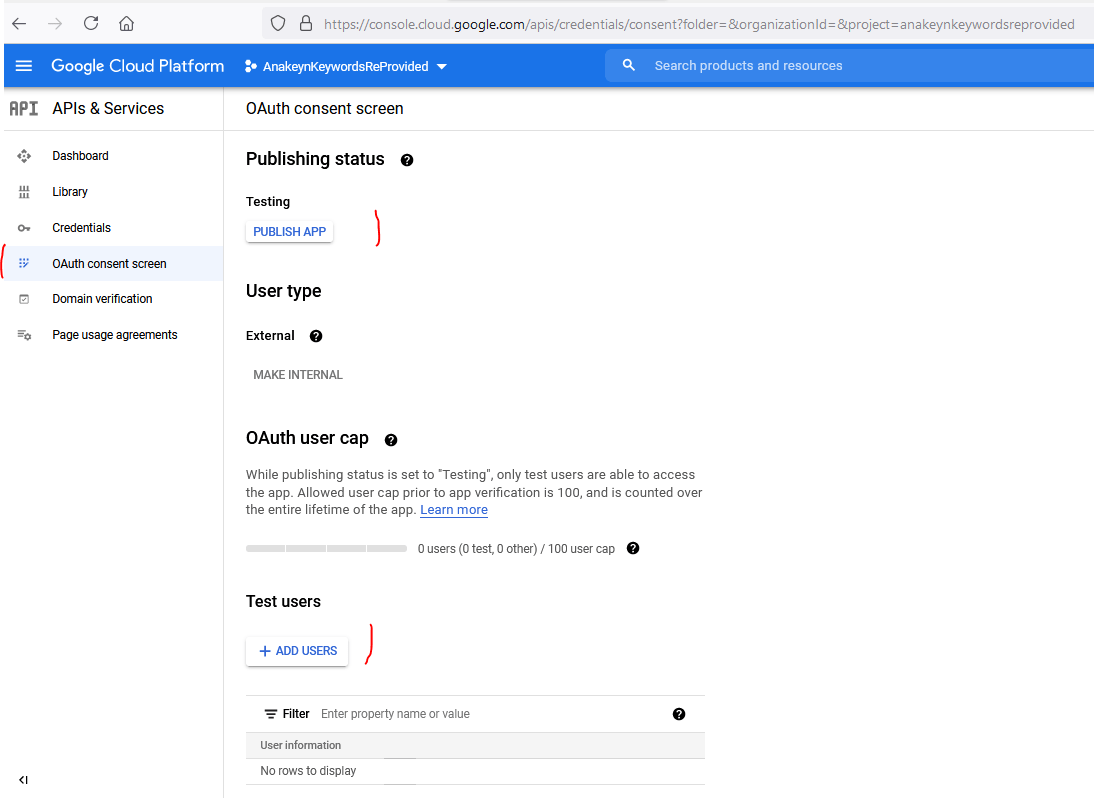
Pour ma part, je me suis ajouté en utilisateur test avec mon email.
Normalement, à ce stade, votre application est paramétrée sur Google Developers Console et vous pouvez l’utiliser. Comme indiqué précédemment, nous allons développer l’application en Python. Toutefois, avant, il vous faut récupérer les codes Google Analytics du site dont vous souhaitez récupérer les données.
Google Analytics
Dans notre cas, nous allons récupérer les données du site de l’association Networking Morbihan sur lesquelles nous avons déjà travaillé.
Attention ! Nous aurons besoin de l’ID du Compte Analytics, de l’ID de propriété et de l’ID de vue pour le site en question. Respectivement dans le programme : ACCOUNT_ID, WEBPROPERTY_ID et VIEW_ID.
L’ID de propriété est celui que vous mettez dans votre code de suivi. Par exemple « UA-12345678-12 ». L’ID de compte est le même que l’ID de propriété moins le préfixe « UA- » et le numéro de propriété (ici « -12 ») soit « 12345678 ».
En se positionnant sur un site et sur l’administration (roue dentée) on a les informations suivantes. Pour l’ID de vue cliquez sur « View Settings » à droite :
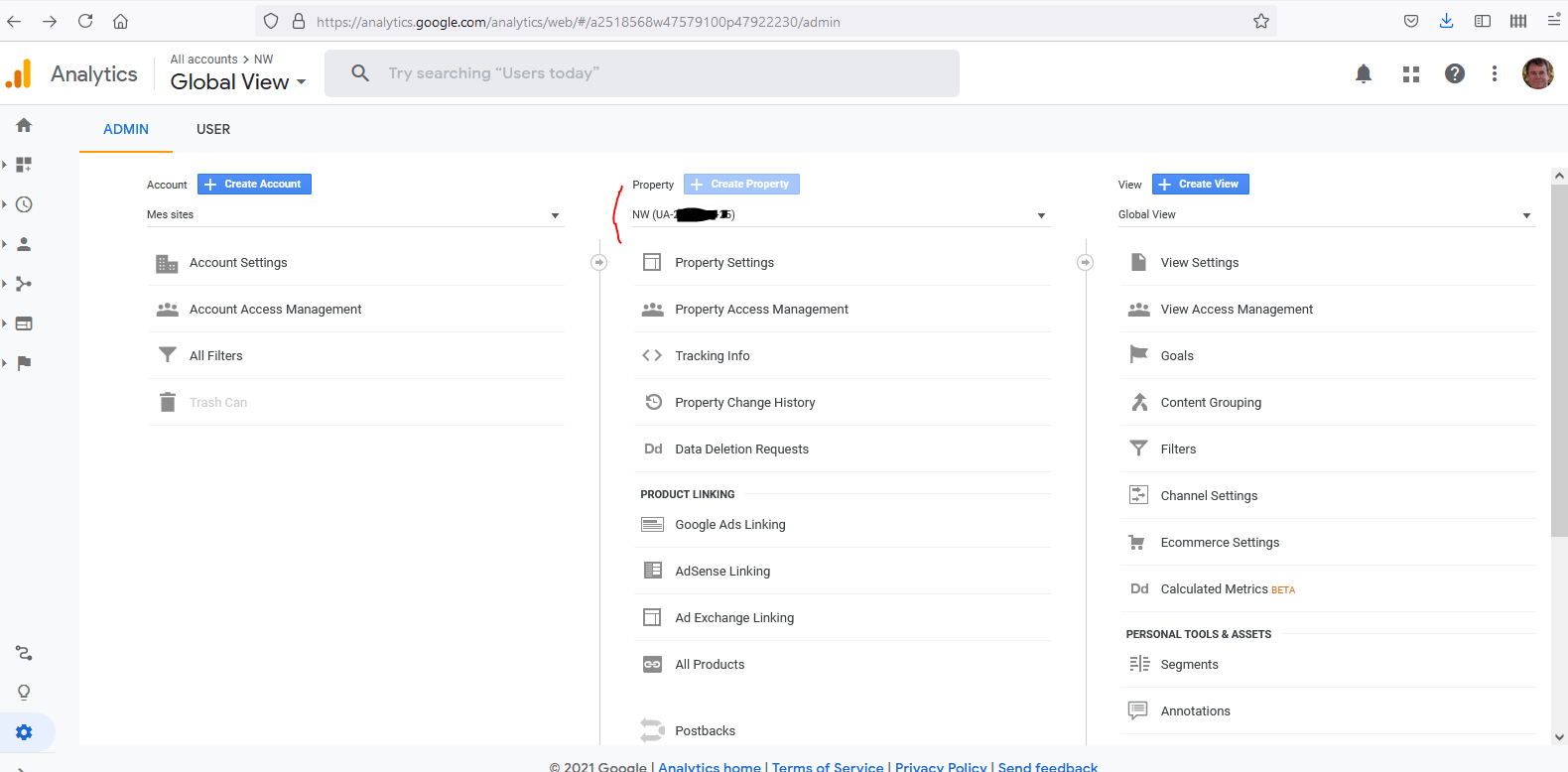
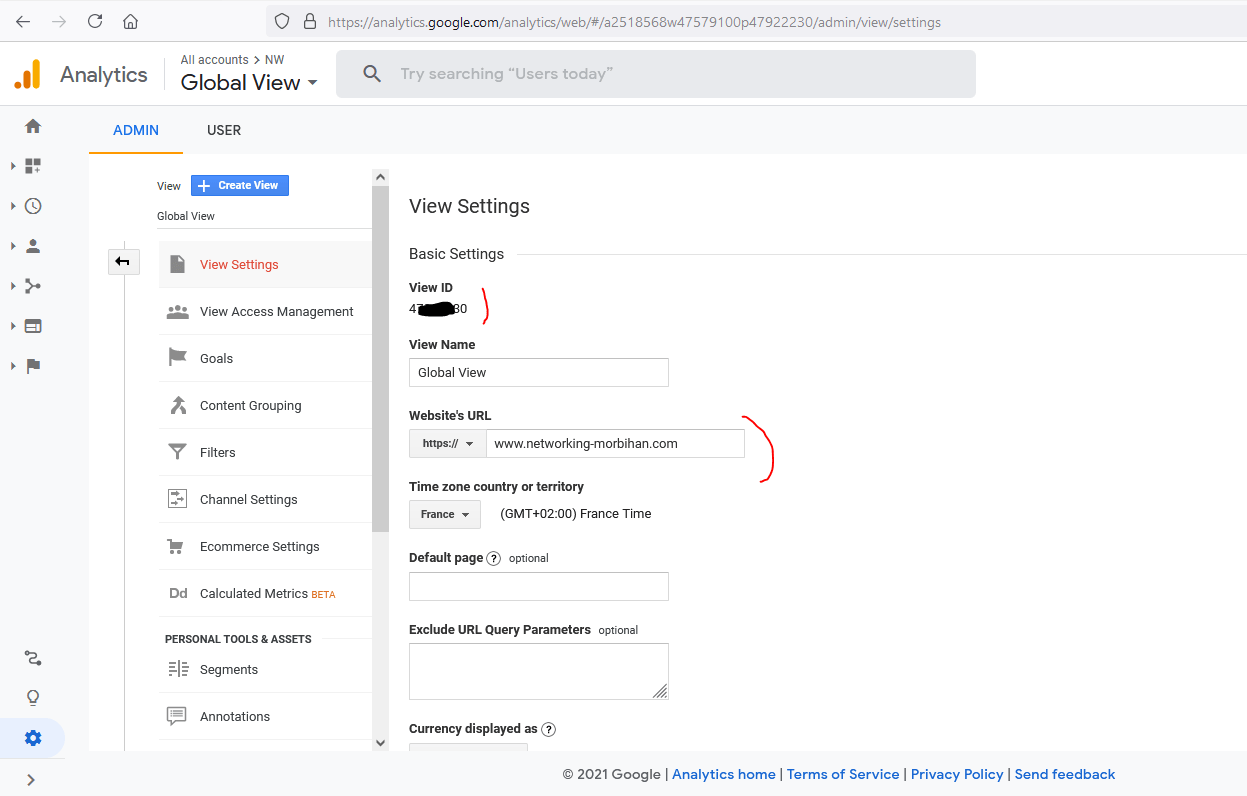
Pour la vue, vérifiez aussi l’URL du site qui doit aussi se trouver dans Google Search Console :
Google Search Console
Vérifiez que le site que vous souhaitez étudier est bien dans Google Search Console : https://search.google.com/search-console/about
Pour notre cas nous étudions https://www.networking-morbihan
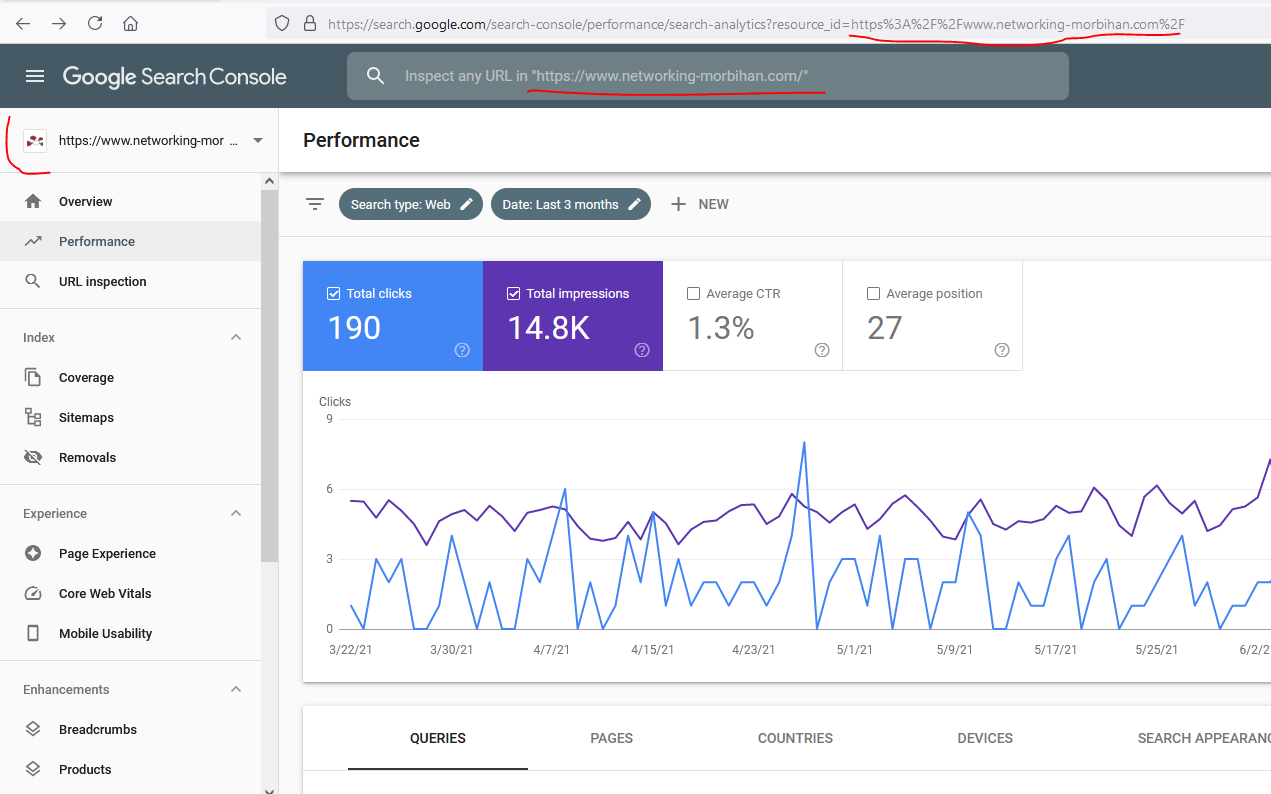
Regroupez vos codes API, Google Analytics et Google Search Console
Notez tous vos codes, vous en aurez besoin pas la suite pour configurer le programme dans le fichier config.py. Ces codes sont sous la forme :
- MYCLIENTID = « 123456789-abcdefghijklmnop.apps.googleusercontent.com »
- MYCLIENTSECRET = « abcdefghijklmnop »
- ACCOUNT_ID = ‘1234567’
- WEBPROPERTY_ID = ‘UA-1234567-2’
- VIEW_ID = ‘12345678’
- SITE_URL = « https://www.mysite.com »
Python Anaconda
Comme vous pouvez le lire sur ce Blog, nous conseillons d’utiliser la version Python d’Anaconda qui dispose de bibliothèques déjà installées pour les sciences de données.
Vous pouvez la télécharger à l’adresse https://www.anaconda.com/products/individual
Anaconda dispose de nombreux outils dont une environnement de développement intégré : Spyder
S’il vous manque des bibliothèques, vous pourrez utiliser la console « Anaconda Prompt » pour en installer. Avec Anaconda, l’outil d’installation est « conda » et non pas « pip » ou « pip3 ».
Par exemple, vous devrez installer la bibliothèque d’accès aux APIs de Google « google-api-python-client » :
conda install -c conda-forge google-api-python-clientPlus de détail ici : https://anaconda.org/conda-forge/google-api-python-client
Nous vous conseillons aussi de lire les documentations de Google suivantes (même si elles ne sont pas toujours à jour) :
- Quickstart: Run a Search Console App in Python
- Hello Analytics Reporting API v4; Python quickstart for installed applications
Code Source
Vous pouvez soit récupérer les morceaux de code source ci-dessous, ou bien tout récupérer d’un coup gratuitement dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-python-anakeyn-keywords-reprovided/
Configuration : fichier config.py
La configuration est dans un fichier Python séparé config.py (de ce fait vous devez aussi créer un fichier __init__.py vide dans le répertoire). Indiquez vos codes personnels. De toute façon ceux-ci sont faux :-).
# -*- coding: utf-8 -*- """ Created on Sat Jun 19 18:50:19 2021 @author: Pierre """ #Fill your Google API clients MYCLIENTID = "123456789-abcdefghijklmnop.apps.googleusercontent.com" MYCLIENTSECRET = "abcdefghijklmnop" #Fill Your Google Analytics and Google Search Console Information ACCOUNT_ID = '1234567' WEBPROPERTY_ID = 'UA-1234567-2' VIEW_ID = '12345678' SITE_URL = "https://www.mysite.com"
Le reste du programme se trouve dans un fichier que j’ai appelé AnakeynKeywordsReProvided.py :
Import de la configuration et des bibliothèques nécessaires
# -*- coding: utf-8 -*- """ Created on Sat Jun 19 18:50:19 2021 @author: Pierre """ ################################################################################ #Anakeyn Keywords Re Provided v0.1 #This tool import data keywords information from Google Search Console in #order to fill Keywords information in Google Analytics Data to avoid "Not Provided" #keywords. ############################################################################### from config import MYCLIENTID, MYCLIENTSECRET, ACCOUNT_ID, WEBPROPERTY_ID, VIEW_ID, SITE_URL #import needed libraries import pandas as pd #for Dataframes #import numpy as np from datetime import date from datetime import datetime from datetime import timedelta from time import sleep import os print(os.getcwd()) #check
Connexion aux APIs de Google
Ce code est fourni par Google
#############################################################################
# Before you need to create a project in Google Developpers :
# https://console.developers.google.com/
# Choose APIs :
# - Google Analytics Reporting API #V4
# - Google Search Console API #V3
#
#Google Code
import argparse #Parser for command-line options, arguments and sub-commands
#Connection
from apiclient.discovery import build
import httplib2
from oauth2client import client
from oauth2client import file
from oauth2client import tools
SCOPES = ['https://www.googleapis.com/auth/analytics.readonly',
'https://www.googleapis.com/auth/analytics.edit', 'https://www.googleapis.com/auth/webmasters']
# Parse command-line arguments.
parser = argparse.ArgumentParser(
formatter_class=argparse.RawDescriptionHelpFormatter,
parents=[tools.argparser])
flags = parser.parse_args([])
.
# Create a flow object for OAuth MYCLIENTID / MYCLIENTSECRET connection
flow = client.OAuth2WebServerFlow(client_id=MYCLIENTID,
client_secret=MYCLIENTSECRET,
scope=SCOPES)
# Prepare credentials, and authorize HTTP object with them.
# If the credentials don't exist or are invalid run through the native client
# flow. The Storage object will ensure that if successful the good
# credentials will get written back to a file.
storage = file.Storage('akrpcredentials.dat')
credentials = storage.get()
######################################################
#Here a window will open if .dat file doesn't exist
if credentials is None or credentials.invalid:
credentials = tools.run_flow(flow, storage, flags)
http = credentials.authorize(http=httplib2.Http())
Nota Bene : la première fois que l’on se connecte aux APIs et que le fichier de credentials en .dat n’est pas créé, un navigateur s’ouvre. Vous devez vous connecter avec votre compte Google correspondant à Google Analytics et Google Search Console et fournir les autorisations.
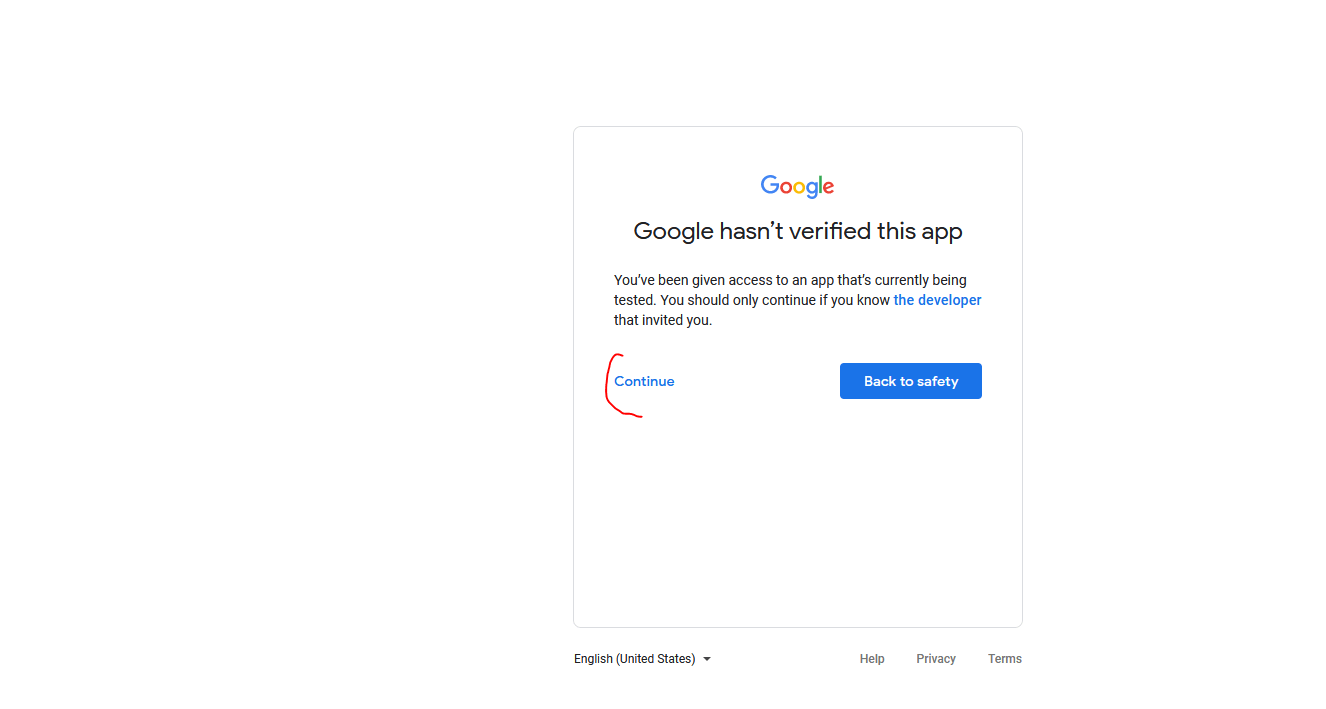
Si l’application est en test vous aurez un message d’alerte. Cliquez sur « Continue »
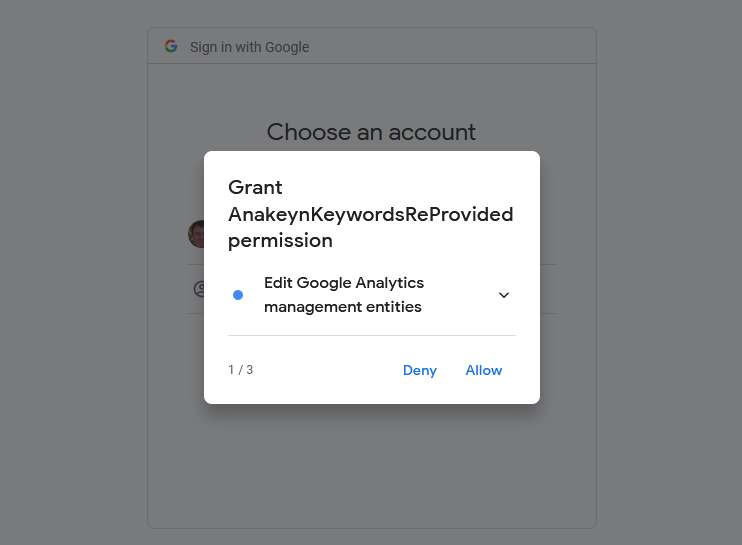
Autorisez les permissions (qui correspondent aux Scopes dans le programme) :
Transformation de la Réponse Google en Pandas Dataframe
Ce code permet de transformer une réponse de l’API De Google en Dataframe, plus facilement exploitable en Python. J’ai repris ce code ici : https://www.themarketingtechnologist.co/getting-started-with-the-google-analytics-reporting-api-in-python/
#######################################################################
#Transform Google Analytics response in dataframe
#see here :
#https://www.themarketingtechnologist.co/getting-started-with-the-google-analytics-reporting-api-in-python/
def dataframe_response(response):
list = []
# get report data
for report in response.get('reports', []):
# set column headers
columnHeader = report.get('columnHeader', {})
dimensionHeaders = columnHeader.get('dimensions', [])
metricHeaders = columnHeader.get('metricHeader', {}).get('metricHeaderEntries', [])
rows = report.get('data', {}).get('rows', [])
for row in rows:
# create dict for each row
dict = {}
dimensions = row.get('dimensions', [])
dateRangeValues = row.get('metrics', [])
# fill dict with dimension header (key) and dimension value (value)
for header, dimension in zip(dimensionHeaders, dimensions):
dict[header] = dimension
# fill dict with metric header (key) and metric value (value)
for i, values in enumerate(dateRangeValues):
for metric, value in zip(metricHeaders, values.get('values')):
#set int as int, float a float
if ',' in value or '.' in value:
dict[metric.get('name')] = float(value)
else:
dict[metric.get('name')] = int(value)
list.append(dict)
df = pd.DataFrame(list)
return df
######################################################################
Import des données dans Google Analytics
Pour plus d’information sur Google Analytics V4, consultez le guide de Google à l’adresse : https://developers.google.com/analytics/devguides/reporting/core/v4.
Remarque : L’API De Google Analytics limite les données à 9 dimensions et 10 métriques. C’est suffisant pour notre cas. Pour en savoir plus sur les Dimensions et les Métriques consultez l’explorateur à l’adresse https://ga-dev-tools.appspot.com/dimensions-metrics-explorer/
L’API De Google Analytics permet de remonter très loin dans le temps, toutefois, comme celle de Google Search Console est limité à 16 mois, nous avons aussi choisi cette limite ici.
#########################################################################
# get DATA from Analytics V4 (Google Analytics Reporting API )
#https://developers.google.com/analytics/devguides/reporting/core/v4
##########################################################################
#Max 9 dimensions , 10 metrics
#https://ga-dev-tools.appspot.com/dimensions-metrics-explorer/
#create severall start dates
OneDay = date.today()
Last7Days = date.today() - timedelta(days=7)
Last28Days = date.today() - timedelta(days=28)
Last3Months = date.today() - timedelta(days=30*3)
Last6Months = date.today() - timedelta(days=30*6)
Last12Months = date.today() - timedelta(days=30*12)
Last15Months = date.today() - timedelta(days=30*15)
Last16Months = date.today() - timedelta(days=30*16)
#Choose one start date
myStartDate = Last16Months
if myStartDate == Last16Months :
myGSCStartDate = myStartDate
else :
myGSCStartDate = myStartDate - timedelta(days=30) #for Google Search Console add 30 Days to get more data
#in strings :
myStrStartDate = myStartDate.strftime("%Y-%m-%d")
myStrGSCStartDate = myGSCStartDate.strftime("%Y-%m-%d")
myStrEndDate = date.today().strftime("%Y-%m-%d")
def get_dfGA(analyticsV4, VIEW_ID, ACCOUNT_ID):
# Use the Analytics Service Object to query the Analytics Reporting API V4.
return analyticsV4.reports().batchGet(
body={
'reportRequests': [
{
'viewId': VIEW_ID,
'pageSize': 100000, #to exceed the limit of 1000
'dateRanges': [{'startDate': myStrStartDate, 'endDate': myStrEndDate}],
'metrics': [{'expression': 'ga:users'},{'expression': 'ga:sessions'}],
'dimensions': [{'name': 'ga:date'},
{'name': 'ga:sourceMedium'},
{'name': 'ga:countryIsoCode'}, #Country ISO-3166-1 alpha-2
{'name': 'ga:deviceCategory'},
{'name': 'ga:keyword'},
{'name': 'ga:landingPagePath'}]
}]
},
quotaUser = ACCOUNT_ID
).execute()
# Build the service object. V4 Google Analytics API
analyticsV4 = build('analyticsreporting', 'v4', credentials=credentials)
response = get_dfGA(analyticsV4, VIEW_ID, ACCOUNT_ID) #get data from Google Analytics
#Data From GA in DataFrame
dfGA = dataframe_response(response) #transform response in dataframe
#Change columns names in order to avoid "ga:" in name
dfGA = dfGA.rename(columns={'ga:date': 'date',
'ga:sourceMedium': 'sourceMedium',
'ga:countryIsoCode': 'countryIsoCode2',
'ga:deviceCategory': 'deviceCategory',
'ga:keyword': 'keyword',
'ga:landingPagePath': 'landingPagePath',
'ga:users': 'users',
'ga:sessions': 'sessions'})
#Entire page URL
dfGA['page']=dfGA.apply(lambda x : SITE_URL + x['landingPagePath'],axis=1)
#transform date string in datetime
dfGA.date = pd.to_datetime(dfGA.date, format="%Y%m%d")
#Tidy dfGA according to sessions
dfGA = dfGA.loc[dfGA.index.repeat(dfGA['sessions'])] #split in multiple rows according to sessions value
dfGA.reset_index(inplace=True, drop=True) #reset index
dfGA['sessions'] = 1 #all sessions to one.
dfGA = dfGA.drop(columns=['users']) #remove users column (not used)
#verifs
#dfGA.dtypes
#dfGA.count()
#dfGA.head(20)
#Save in excel
#dfGA.to_excel("dfGA.xlsx", sheet_name='dfGA', index=False)
#Select only google / organic
dfGAGoogleOrganic = dfGA.loc[dfGA['sourceMedium'] == 'google / organic']
dfGAGoogleOrganic.reset_index(inplace=True, drop=True) #reset index
#Save in Excel
#dfGAGoogleOrganic.to_excel("dfGAGoogleOrganic.xlsx", sheet_name='dfGAGoogleOrganic', index=False)
Récupération des données de Google Search Console sur la même période
Nota Bene : quand on demande à Google Search Console des informations avec la requête et la page de destination, celui-ci échantillonne les données et nous avons (beaucoup) moins d’informations sur les clics dans Google Search Console que dans Google Analytics . Nous verrons comment régler ce problème par la suite.
###################################################################################
#########################################################################
# get DATA from Google Search Console
##########################################################################
#open a Google Search console service (previously called Google Webmasters tools)
webmastersV3 = build('webmasters', 'v3', credentials=credentials)
#################################################################################################
####### Get Precise traffic from Google Search Console : clicks, impressions, ctr, poition, date, country, device
# + Queries and landing Page ##############
# Beware : When we ask for "precise traffic" i.e : with query and landing page we don't get all traffic !
dfGSC = pd.DataFrame() #global dataframe for precise traffic
maxStartRow = 1000000000 #to avoid infinite loop
myStartRow = 0
while ( myStartRow < maxStartRow):
df = pd.DataFrame() #dataframe for this loop
mySiteUrl = SITE_URL
myRequest = {
'startDate': myStrGSCStartDate, #older date for Google Search Console (1 month more than GA)
'endDate': myStrEndDate, #most recent date
'dimensions': ["date", "query","page","country","device"], #Country ISO 3166-1 alpha-3
'searchType': 'web', #for the moment only Web
'rowLimit': 25000, #max 25000 for one Request
'startRow' : myStartRow # for multiple resquests 'startRow':
}
response = webmastersV3.searchanalytics().query(siteUrl=mySiteUrl, body=myRequest, quotaUser=ACCOUNT_ID).execute()
print("myStartRow:",myStartRow)
#set response (dict) in DataFrame for treatments purpose.
df = pd.DataFrame.from_dict(response['rows'], orient='columns')
if ( myStartRow == 0) :
dfGSC = df #save the first loop df in global df
else :
dfGSC = pd.concat([dfGSC, df], ignore_index=True) #concat this loop df with global df
if (df.shape[0]==25000) :
myStartRow += 25000 #continue
else :
myStartRow = maxStartRow+1 #stop
#split keys in date query page country device
dfGSC[["date", "query", "page", "country", "device"]] = pd.DataFrame(dfGSC["keys"].values.tolist())
dfGSC.date = pd.to_datetime(dfGSC.date, format="%Y-%m-%d")
dfGSC = dfGSC.drop(columns=['keys']) #remove Keys (not used)
#Save in Excel
#dfGSC.to_excel("dfGSC.xlsx", sheet_name='dfGSC', index=False)
###########################################################################################
# Tidy the Dataframe (one row by observation, one column by variable)
###########################################################################################
#Create rows with impressions whithout clicks
dfGSC['ImpressionsMinusClicks']=dfGSC.apply((lambda x : x['impressions'] - x['clicks']),axis=1)
dfGSCImpressions = dfGSC.loc[dfGSC.index.repeat(dfGSC['ImpressionsMinusClicks'])] #split in multiple rows according to 'ImpressionsMinusClicks' value
dfGSCImpressions.reset_index(inplace=True, drop=True) #reset index
dfGSCImpressions['impressions'] = 1 #all impressions to one.
dfGSCImpressions['clicks'] = 0 #all clicks to zero.
#Create rows with clicks
dfGSCClicks = dfGSC.loc[dfGSC.index.repeat(dfGSC['clicks'])] #split in multiple rows according to clicks value
dfGSCClicks.reset_index(inplace=True, drop=True) #reset index
dfGSCClicks['impressions'] = 1 #all impressions to one.
dfGSCClicks['clicks'] = 1 #all clicks to one.
dfGSCTidy = pd.concat([dfGSCImpressions, dfGSCClicks ])
dfGSCTidy.reset_index(inplace=True, drop=True) #reset index
#sort
dfGSCTidy.sort_values(by=["date", "clicks", "country", "device", ], ascending=[True, False, True, True],inplace=True)
dfGSCTidy.reset_index(inplace=True, drop=True) #reset index
#remove 'ImpressionsMinusClicks' column, not needed anymore
dfGSCTidy.drop(columns='ImpressionsMinusClicks', inplace=True)
Calcul d’un poids pour les impressions
Comme on l’a vu précédemment, nous n’avons pas le même nombre de clics dans Google Search Console que dans Google Analytics. Afin de rapprocher les informations des 2 sources, nous allons nous baser sur les impressions dans Google Search Console en tirant au hasard parmi des potentiels couples (Mots-clés, Pages) pondérés.
Pour le poids nous allons partir d’un taux de clics théorique selon le numéro de page d’impression et la position sur la première page. Si vous souhaitez plus d’information consulter cet article : https://www.smartinsights.com/search-engine-optimisation-seo/seo-analytics/comparison-of-google-clickthrough-rates-by-position/
###############################################################################################
#calculate a "weight" for the future weight sample according to "actual" ctr and theorical Ctr according to position
#source https://www.smartinsights.com/search-engine-optimisation-seo/seo-analytics/comparison-of-google-clickthrough-rates-by-position/
def calculateWeight(ctr, position) :
ctrFirstPage = [0.342, 0.171, 0.114, 0.081, 0.074, 0.051, 0.041, 0.033, 0.029, 0.026]
ctrSecondPage = 0.02
ctrOtherPage = 0.01
if ctr>0.0 :
weight = ctr
elif position < 11.0 :
weight = ctrFirstPage[int(position)-1]
elif ((position>10.0) & (position<21.0)) :
weight = ctrSecondPage
else :
weight = ctrOtherPage
return weight
dfGSCTidy['weight']= dfGSCTidy.apply(lambda x: calculateWeight(x.ctr, x.position), axis=1)
#Save in Excel
#dfGSCTidy.to_excel("dfGSCTidy.xlsx", sheet_name='dfGSCTidy', index=False)
Récupération des données IsoCode2 de pays pour Google Search Console.
Dans Google Search console les pays sont codés sur 3 lettres et dans Google Analytics sur 2 lettres. Si l’on veut utiliser le Pays comme facteur différenciant nous sommes obligés de récupérer cette information.
Pour cela, vous aurez besoin du fichier de correspondances que vous pouvez télécharger à l’adresse : https://www.anakeyn.com/v3/wp-content/uploads/2021/06/countries_codes_and_coordinates.csv
########################################################################
# Get Country Isocode 2 to compare with GA traffic
# Read Country Code data
dfCountryCodes = pd.read_csv("countries_codes_and_coordinates.csv", sep=';', usecols=["countryIsoCode3","countryIsoCode2"])
dfCountryCodes['countryIsoCode3']=dfCountryCodes['countryIsoCode3'].str.strip() #need to do that to avoid NaN in Merge
dfCountryCodes['countryIsoCode2']=dfCountryCodes['countryIsoCode2'].str.strip() #need to do that to avoid NaN in Merge
dfCountryCodes.dtypes
dfCountryCodes.info()
#Merge dfGSCTidy with Country Codes
dfGSCTidy['countryIsoCode3'] = dfGSCTidy['country'].apply(lambda x: x.upper())
dfGSCTidy['countryIsoCode3'] = dfGSCTidy['countryIsoCode3'].str.strip() #need to do that to avoid NaN in Merge
dfGSCTidy.info()
dfGSCTidyCountries= pd.merge(left=dfGSCTidy, right=dfCountryCodes, how='left', left_on='countryIsoCode3', right_on='countryIsoCode3')
#Save in Excel
#dfGSCTidyCountries.to_excel("dfGSCTidyCountries.xlsx", sheet_name='dfGSCTidyCountries', index=False)
dfGSCTidyCountries.dtypes
dfGSCTidyCountries.date = pd.to_datetime(dfGSCTidyCountries.date, format="%Y-%m-%d")
Modification des Not Provided
Dans cette dernière partie nous essayons d’être le plus précis possible dans l’échantillon dans lequel nous allons tirer le bon couple (mot-clé, page) :
- En premier on compare l’URL de la page, la date, le pays et le type d’appareil.
- En second l’URL de la page, le pays et le type d’appareil.
- En troisième l’URL de la page et le type d’appareil.
- Enfin l’URL de la page uniquement.
Si l’on ne trouve rien on indiquera « (Not Found) ».
On peut évidemment améliorer l’algorithme, mais celui-ci donne des résultats assez probants sans faire de choses trop sophistiquées.
#########################################################################################
########################################################################################
###############################Change (not Provided) with good query in dfGAGoogleOrganic
#Prepare dfGAReProvided
dfGAReProvided = dfGAGoogleOrganic
dfGAReProvided.dtypes
dfGAReProvided['sourceMedium']
dfGAReProvided['countryIsoCode2']
dfGAReProvided['deviceCategory'] = dfGAReProvided['deviceCategory'].str.upper()
dfGAReProvided['page'] = SITE_URL + dfGAReProvided['landingPagePath']
dfGAReProvided['clicks'] = ""
dfGAReProvided['impressions'] = ""
dfGAReProvided['ctr'] = ""
dfGAReProvided['position'] = ""
dfGAReProvided['GSCDate'] = ""
dfGAReProvided['weight'] = ""
dfGAReProvided['factors'] = ""
for index, row in dfGAReProvided.iterrows():
print("index:", index)
print("date:", row['date'])
print("page:", row['page'])
print("countryIsoCode2:", row['countryIsoCode2'])
print("deviceCategory:", row['deviceCategory'])
#select page date country device rows in dfGSCTidy according
factors = 4
print("4 factors")
dfSelection = dfGSCTidyCountries.loc[(dfGSCTidyCountries['page']==row['page']) & (dfGSCTidyCountries['date']==row['date']) & (dfGSCTidyCountries['countryIsoCode2']==row['countryIsoCode2']) & (dfGSCTidyCountries['device']==row['deviceCategory'])]
if dfSelection.size==0 :
factors=3
print("3 factors")
dfSelection = dfGSCTidyCountries.loc[(dfGSCTidyCountries['page']==row['page']) & (dfGSCTidyCountries['countryIsoCode2']==row['countryIsoCode2']) & (dfGSCTidyCountries['device']==row['deviceCategory']) ]
if dfSelection.size==0 :
factors=2
print("2 factors")
dfSelection = dfGSCTidyCountries.loc[(dfGSCTidyCountries['page']==row['page']) & (dfGSCTidyCountries['device']==row['deviceCategory'])]
if dfSelection.size==0 :
factors=1
print("1 factor")
dfSelection = dfGSCTidyCountries.loc[(dfGSCTidyCountries['page']==row['page'])]
if dfSelection.size==0 :
factors=0
print("None factor")
#dfSelection = dfGSCTidyCountries
#sleep(1)
if factors > 0 :
#Sample data
dfSampleRow = dfSelection.sample(n=1, weights=dfSelection['weight'])
dfSampleRow.reset_index(inplace=True, drop=True) #reset index
#Remove randomly selected row in dfGSCTidy for next loop
#dfGSCTidy = dfGSCTidy.drop(dfSampleRow['myIndex'])
mySampleRow = dfSampleRow.iloc[0,:] #df to series
############## insert Data
dfGAReProvided.loc[index,'keyword']=mySampleRow['query']
dfGAReProvided.loc[index,'clicks'] = mySampleRow['clicks']
dfGAReProvided.loc[index,'impressions'] = mySampleRow['impressions']
dfGAReProvided.loc[index,'ctr'] = mySampleRow['ctr']
dfGAReProvided.loc[index,'position'] = mySampleRow['position']
dfGAReProvided.loc[index,'GSCDate'] = mySampleRow['date']
dfGAReProvided.loc[index,'weight'] = mySampleRow['weight']
dfGAReProvided.loc[index,'factors'] = factors
else :
#No data Found
dfGAReProvided.loc[index, 'keyword'] = "(Not Found)"
dfGAReProvided.loc[index,'factors'] = factors
#Save in Excel
dfGAReProvided.to_excel("dfGAReProvided.xlsx", sheet_name='dfGAReProvided', index=False)
############ END END END
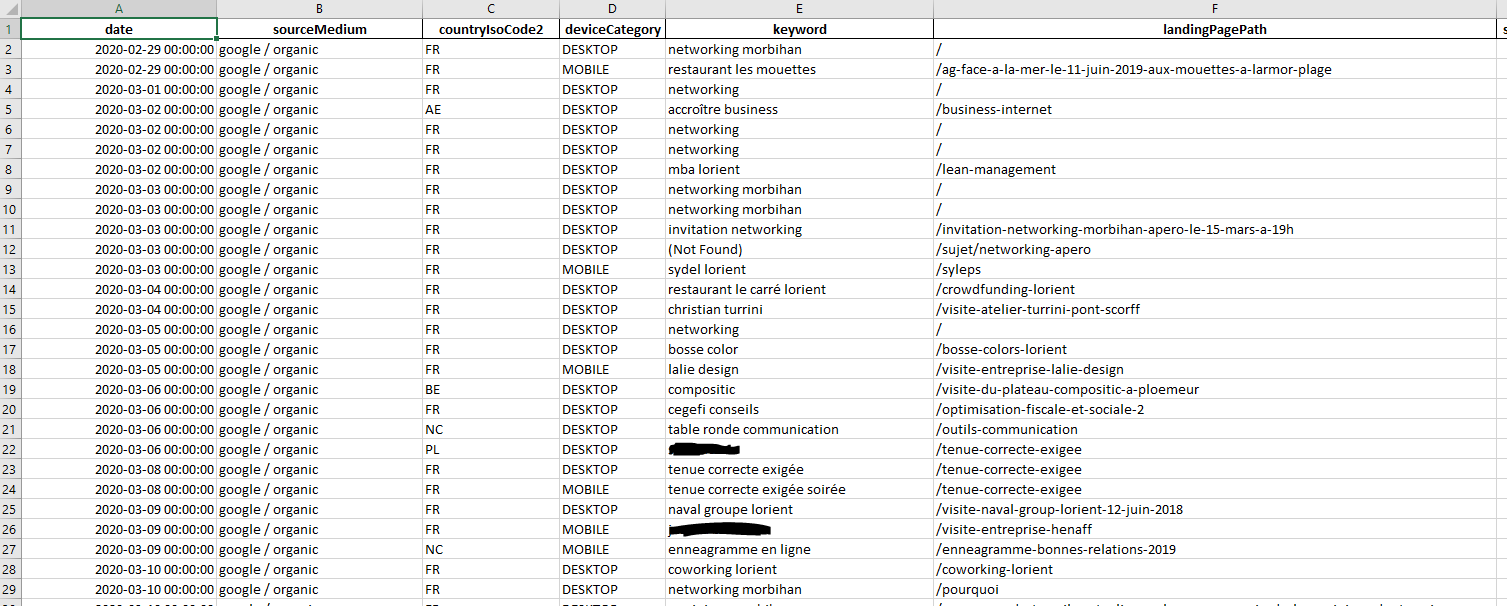
Résultats :
Le résultat est sauvegardé dans un fichier Excel « dfGAReProvided.xlsx ».
Suggestions, Remarques bienvenues en commentaire.
A bientôt,
Pierre