Partager la publication "Comment récupérer des données Google Search Console dans Dataiku DSS 6.0"
Dans cet article nous verrons comment récupérer les données de « Performance Web » de votre site (notamment les mots clés) de Google Search Console dans Dataiku Data Science Studio 6.0.
Nous ferons ensuite différents traitements sur ces données. Ceci vous permettra de voir une partie de l’étendue des possibilités de DSS dans la manipulation de données sans avoir à programmer (en partie).
Toutefois, pour importer les données de Google Search Console, nous aurons besoin de créer une extension ou plugin dans Dataiku DSS. Cette extension sera réalisée en Python et nous vous présenterons le code source.
De quoi aurons-nous besoin ?
Google Search Console API :
Afin de récupérer les données de Google Search Console il sera nécessaire de faire appel à son API (Application Programming Interface).
Remarque : nous avions déjà abordé l’import de donnée de Google Search Console dans différents articles notamment « Récupérez des données de positionnement de vos pages via Google Search Console API« .
Toutefois, cette fois-ci nous allons utiliser une autre méthode pour accéder à l’API de Google à savoir le « compte de service » ou « Service Account« .
Un compte de service est comme votre compte Google, mais au lieu d’être attaché à une personne (vous) il sera attaché à une application (ici notre plugin dans DSS) qui pourra accéder aux données de Google Search Console.
Pour le paramétrer suivez la procédure suivante :
Créez un projet dans la console développeur :
Allez à l’adresse : https://console.developers.google.com et connectez-vous avec votre compte Google.
Si vous n’avez jamais utilisé la console développeur auparavant, acceptez les conditions d’utilisation, puis cliquez sur Créer un projet.
Sinon :
cliquez sur le petit triangle en face du nom du projet en cours en haut à gauche. Une fenêtre s’ouvre :
Cliquez sur « Nouveau projet » en haut à droite de la fenêtre.
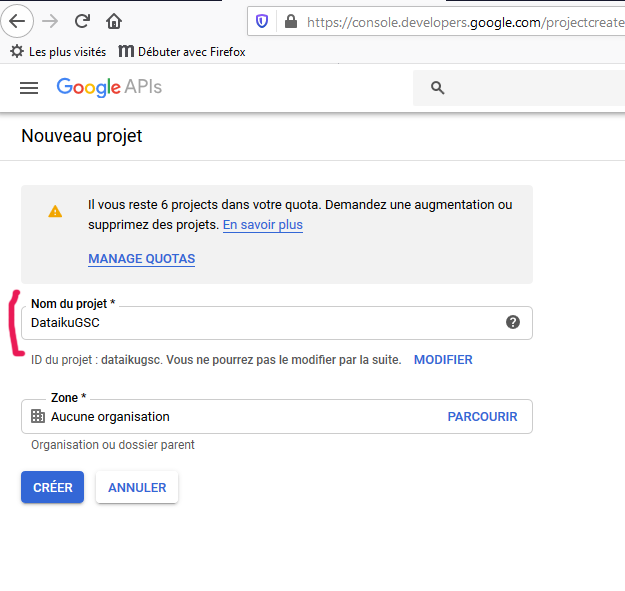
et donnez-lui un nom explicite et cliquez sur « Créer ».
Ensuite, sélectionnez le projet que vous venez de créer en cliquant sur le petit triangle noir et en sélectionnant votre projet dans la liste.
Activez l’API DE GOOGLE SEARCH CONSOLE pour Ce compte de service :
Complètement en haut à gauche de la console repérez le menu avec 3 barres horizontales :
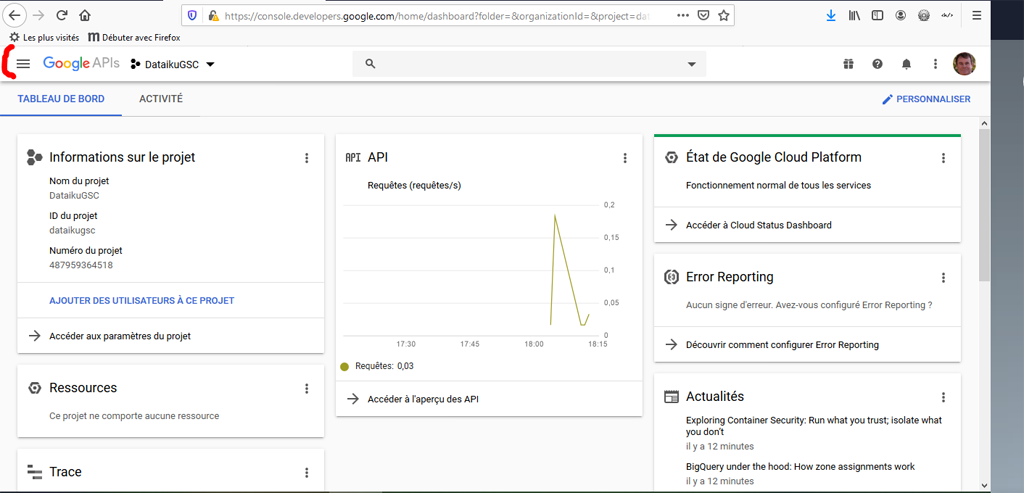
Sur le Menu choisissez API et services > Bibliothèque
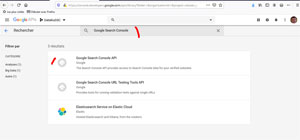
Recherchez « Google Search Console » et sélectionnez « Google Search Console API » puis activez-là sur la page suivante.
Créez le compte de service ou service account :
Recliquez sur le menu 3 barres et choisissez IAM et administration > Comptes de Services
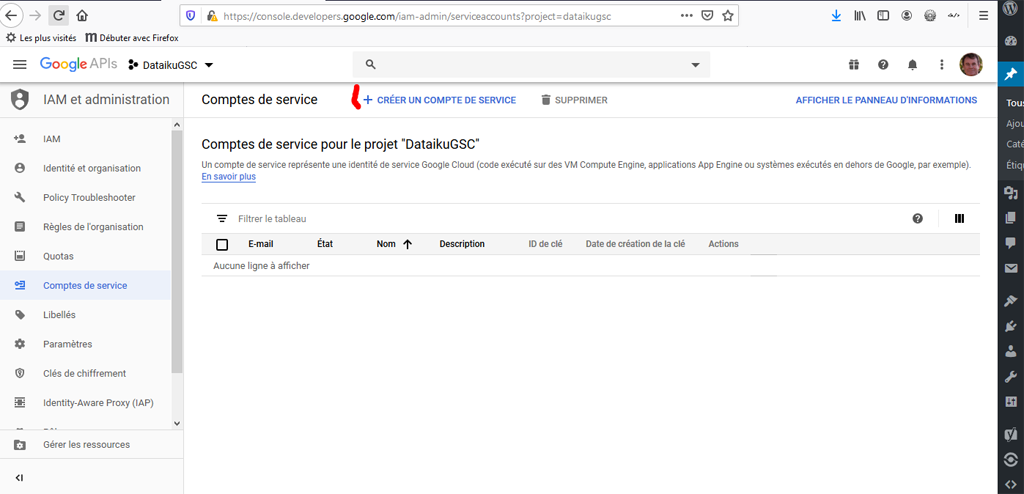
Et allez créer un compte de service :
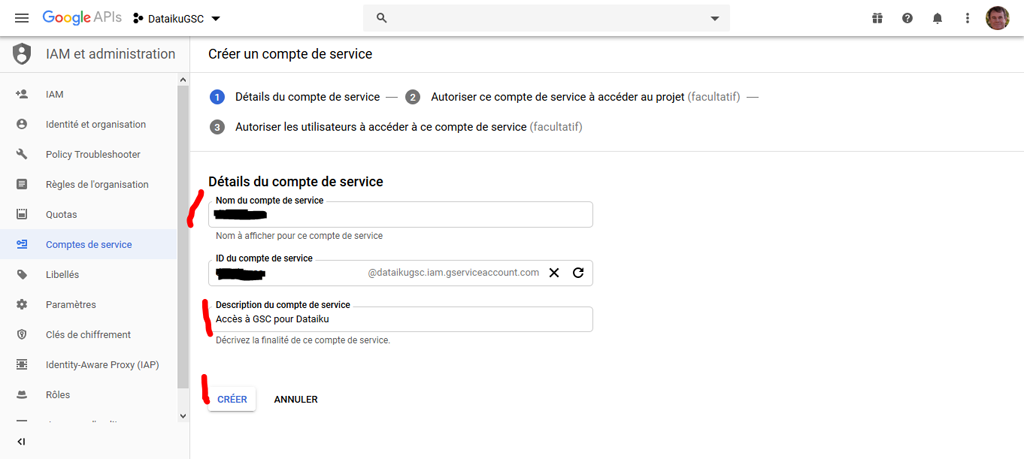
Indiquez un nom (obligatoire) et une description (facultative) et cliquez sur « Créer »
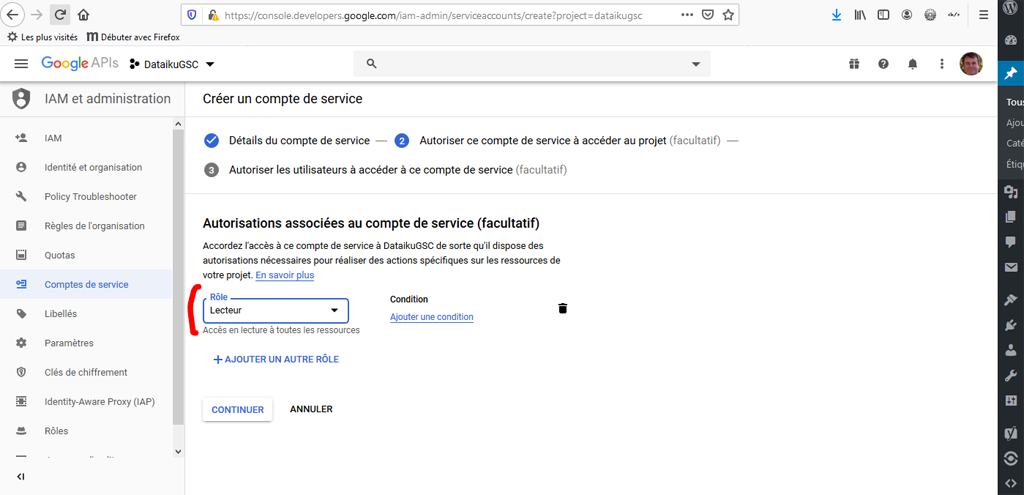
Assignez le rôle « Lecteur » au compte de service et cliquez sur « continuer ».
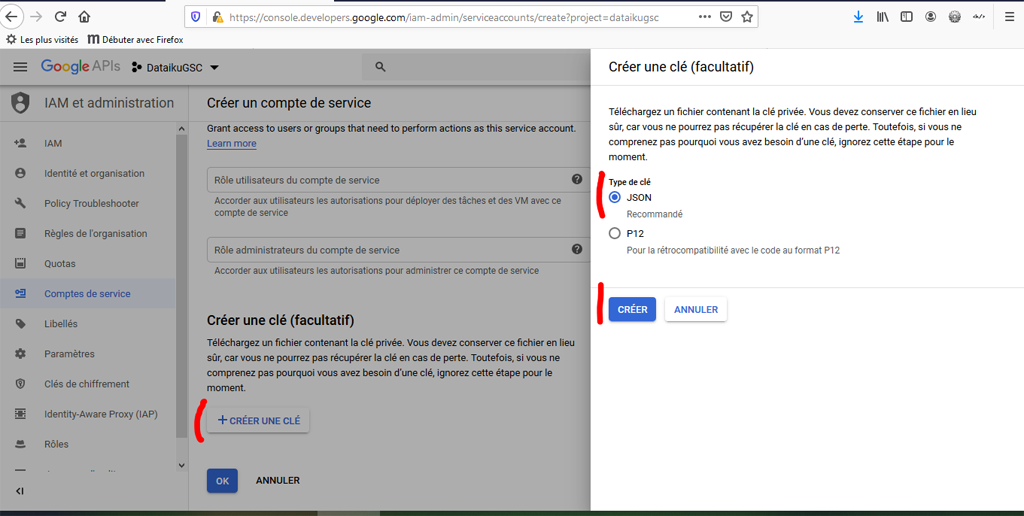
Tout en bas de la page, cliquez sur « Créer une clé », assurez-vous que vous avez le format « JSON » puis cliquez sur créer.
Le système va créer un fichier .json, téléchargez-le et sauvegardez-le en lieu sûr. En revenant sur la page « Comptes de service » votre compte s’affiche maintenant :
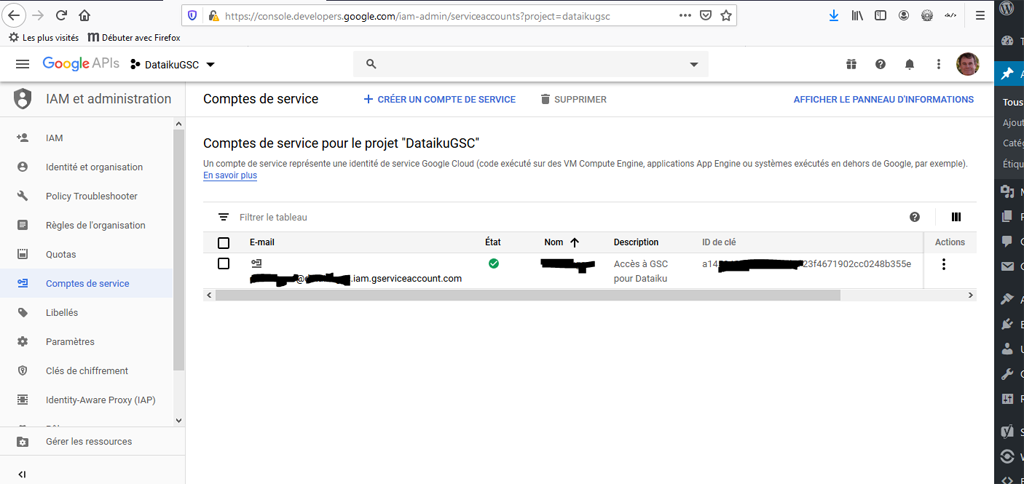
Copier l’adresse email dans votre presse-papier vous allez en avoir besoin !!!
Google Search Console
Attention !!! Il reste encore une étape : Autoriser le compte de service à accéder aux données du site souhaité.
Pour cela : RDV sur Google Search Console : https://search.google.com/search-console/
Pour le site souhaité (ici pour nous https://www.anakeyn.com), allez dans les paramètres, puis utilisateurs et autorisations :
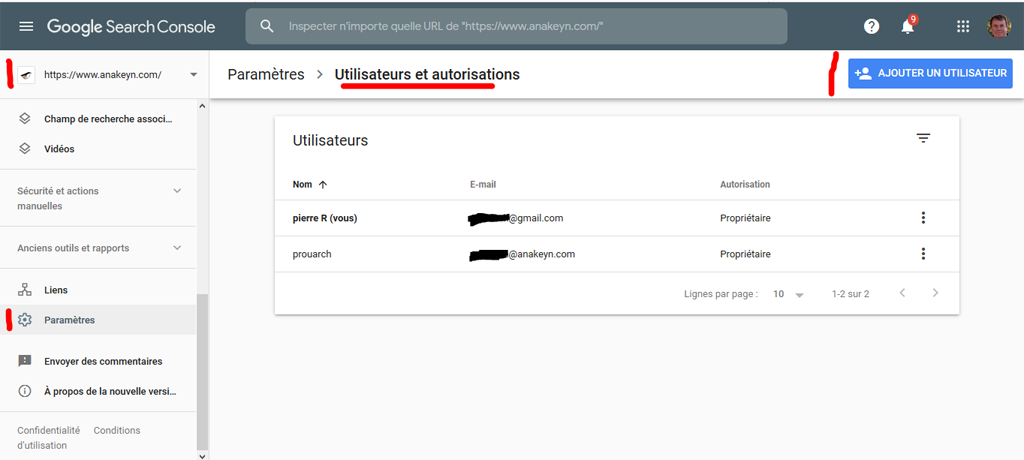
Puis ajouter l’email du compte de service comme utilisateur avec autorisation totale.
Voilà : normalement vous pourrez accéder aux données de votre site à partir de Dataiku DSS.
Dataiku DSS :
Rappel : pour installer Dataiku DSS 6.0 reportez-vous à notre article précédent : https://www.anakeyn.com/2020/01/23/installation-prise-en-main-dataiku-dss-6-0-sous-windows-10/.
Pour démarrer Dataiku DSS dans Ubuntu, dans la console Linux tapez DATA_DIR/bin/dss start
Pour accéder à Dataiku, ouvrez un navigateur Firefox ou Chrome et allez à l’adresse http://<your server adress>:11000 (souvent http://127.0.0.1:11000)
Si vous ne les avez pas changés le login et le mot de passe au démarrage sont « admin » et « admin »
Installation de notre Plugin dans Dataiku
Création d’un nouveau projet
Pour tester le plugin nous allons créer un nouveau projet (à blanc) dans Dataiku DSS :
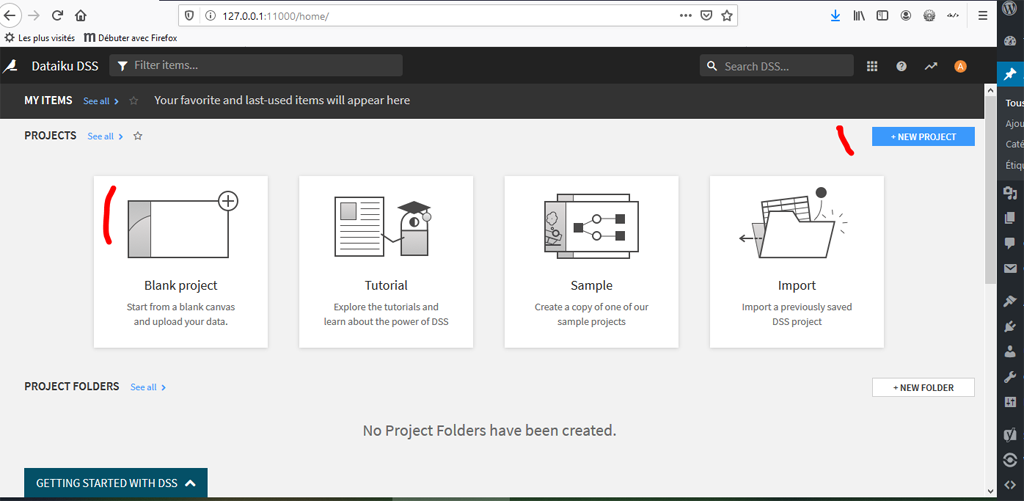
Une fois le projet créé, repérez en haut à droite le logo en forme de grille :
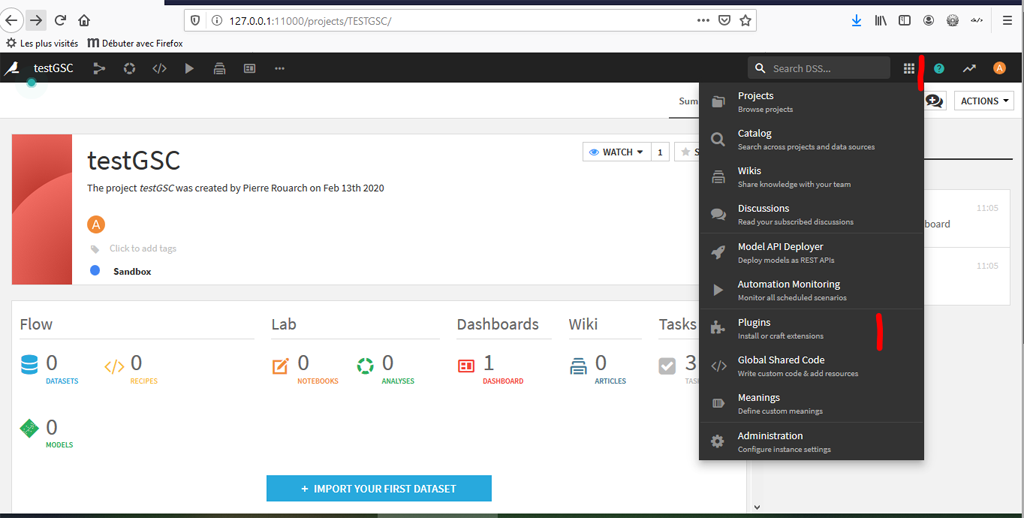
Et choisissez l’option « Plugins ».
Installation du Plugin
On arrive sur la « boutique » de plugins de Dataiku.
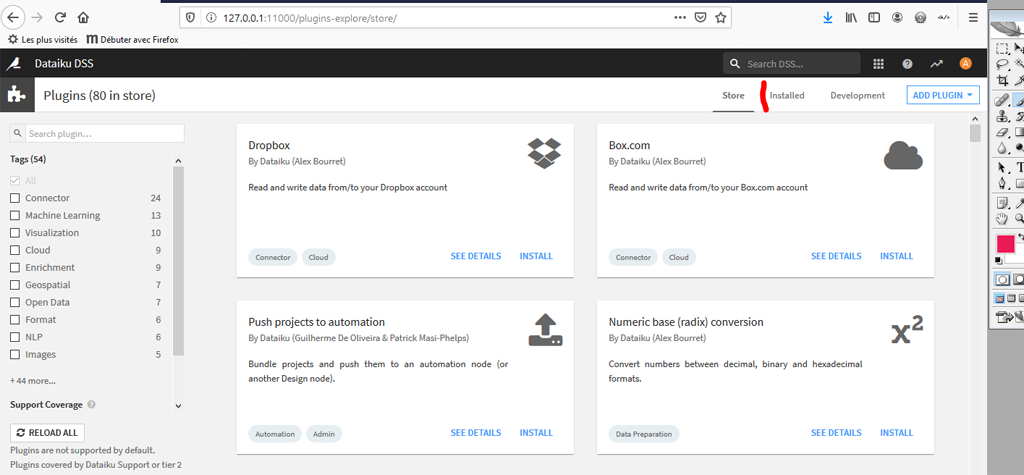
La plupart de ces Plugins « officiels » ont été écrits par Dataiku et ne fonctionnent pas avec la version gratuite de DSS :-(. Il existe toutefois d’autres méthodes pour installer des plugins.
Avant l’installation vérifions quels sont nos plugins déjà installés en cliquant sur l’onglet « Installed » :
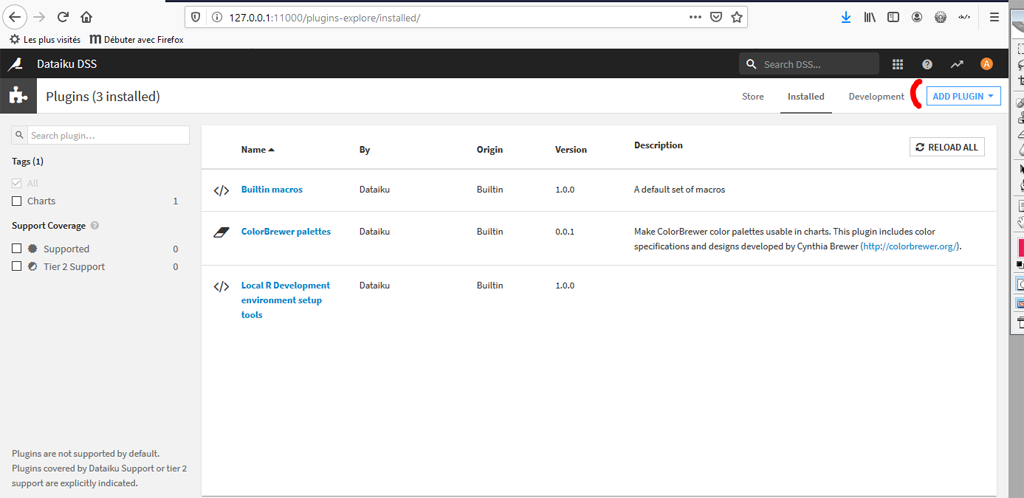
Dataiku DSS installe 3 plugins par défaut :
- Builtin Macros : une bibliothèque de macros par défaut
- ColorBrewer palettes : un plugin qui permet d’utiliser les palettes de couleurs « Brewer » dans les graphiques.
- Local R Development environment setup tools : permet notamment de développer des plugins en R (ce que nous ferons peut être)
Pour ajouter un nouveau plugin (hors du store) cliquez sur le bouton « Add Plugin » en haut à droite :
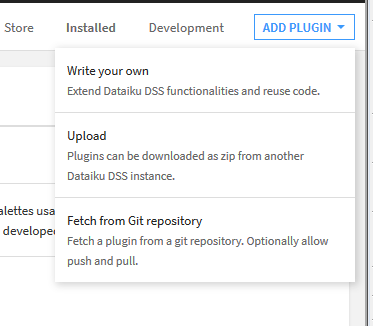
Vous avez 3 possibilités :
- Soit écrire votre propre Plugin directement. DSS propose un éditeur de code source ou vous pouvez soit créer, soit modifier des plugins existants.
- Charger le plugin depuis un dépôt GitHub.
- Ou bien Télécharger un plugin au format .zip : Nous vous proposons de télécharger gratuitement celui-ci à partir de notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-python-plugin-import-goolge-search-console-pour-dataiku/ sur votre ordinateur puis ensuite de l’uploader dans Dataiku.
Si le système le propose, choisissez directement l’option de Mode Développement, nous irons voir cela par la suite.
Le système prend quelque temps pour « créer le plugin » .
Création de l’environnement de développement
Il est possible aussi que le système vous demande de créer un « environnement » pour le plugin -> faites-le.
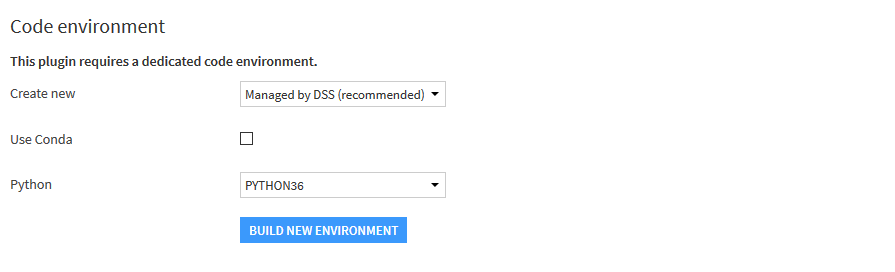
Choisissez l’option par défaut « Managed by DSS » et normalement le Python avec lequel vous avez installé Dataiku, soit, pour nous « PYTHON36 ». Attention cela prend un certain temps pour charger et installer les bibliothèques.
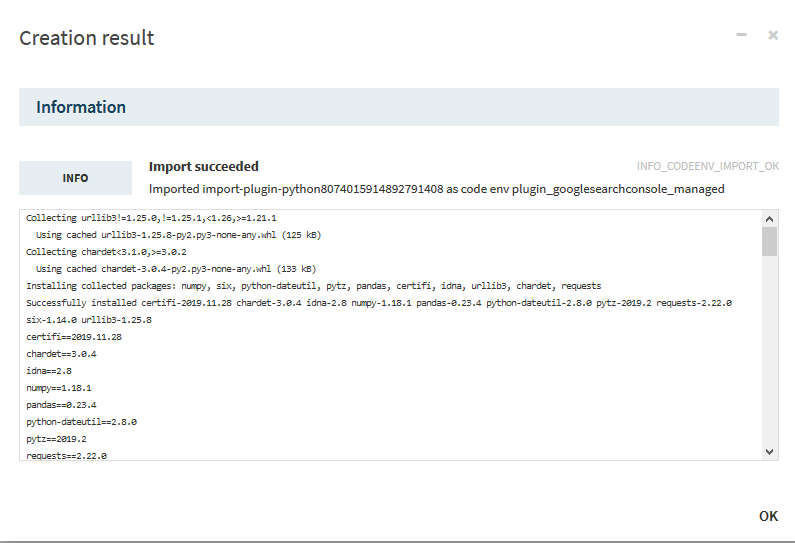
Ceci permettra à votre plugin de s’exécuter dans un environnement Python différent de celui de Dataiku DSS et ainsi d’éviter des problèmes d’incompatibilité éventuels.
Page du Plugin
La page principale du plugin présente ses caractéristiques générales.
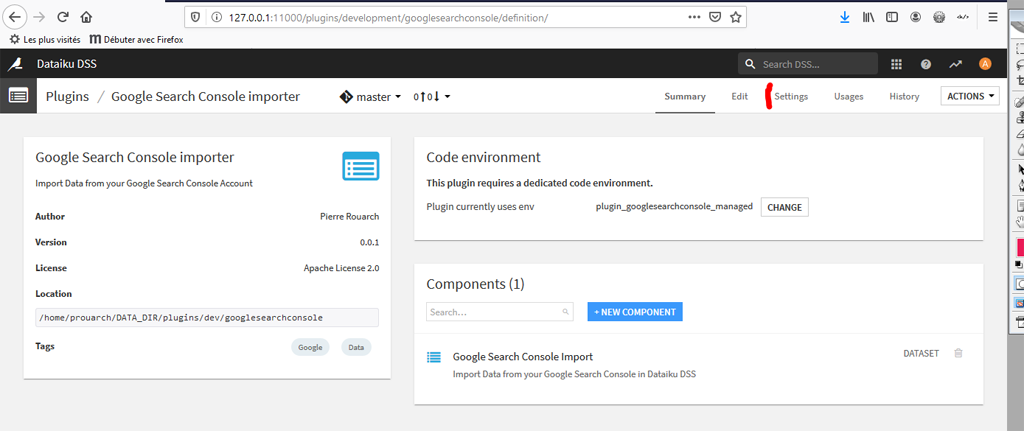
Notez que notre plugin ne comporte qu’un seul composant, du type « Dataset« . C’est un connecteur qui va créer directement un dataset à partir des données de Google Search Console. Il existe d’autres types de plugins. Nous aurons l’occasion de revenir sue ce sujet dans de prochains articles.
Cliquez sur l’onglet « Settings » pour aller paramétrer notre plugin.
Paramétrage du plugin
Vous pouvez dans la zone « JSON Service account » soit copier/coller le contenu du fichier JSON pour le compte de service que vous aviez précieusement sauvegardé précédemment :-).
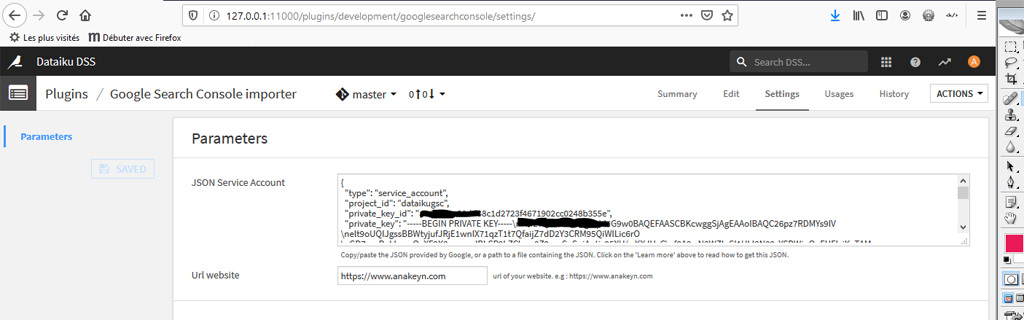
Soit indiquer le chemin et le nom du fichier.
Remarque : dans notre cas Dataiku étant installé dans Ubuntu sous Windows, le disque C: de Windows est accessible de Linux avec le chemin « /mnt/c/ ». Essayez d’avoir un chemin court.
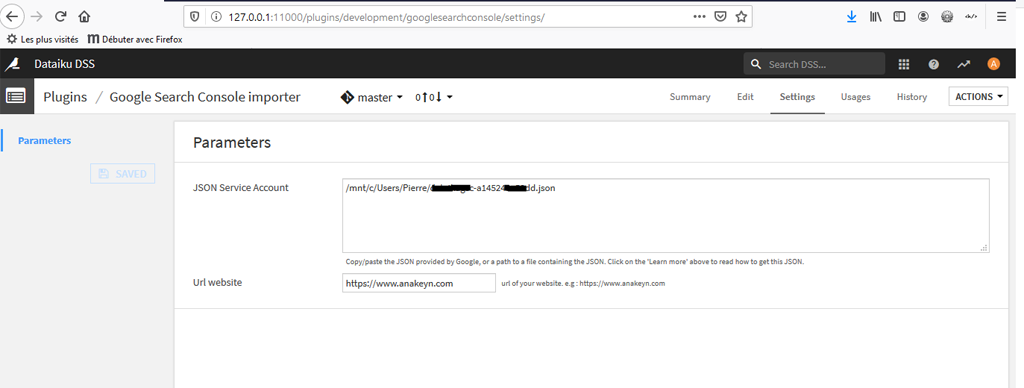
Le site Web est celui pour lequel vous avez autorisé le compte de service précédemment dans Google Search Console.
Utilisation du Plugin
L’objectif de cette partie est de retrouver les fameux mots clés « not provided » que l’on a dans Google Analytics. On pourra aussi faire un graphique inédit (impossible avec Google Search Console 🙂 )
Pour utiliser le plugin, revenons à l’accueil puis au projet que nous avions créé précédemment :
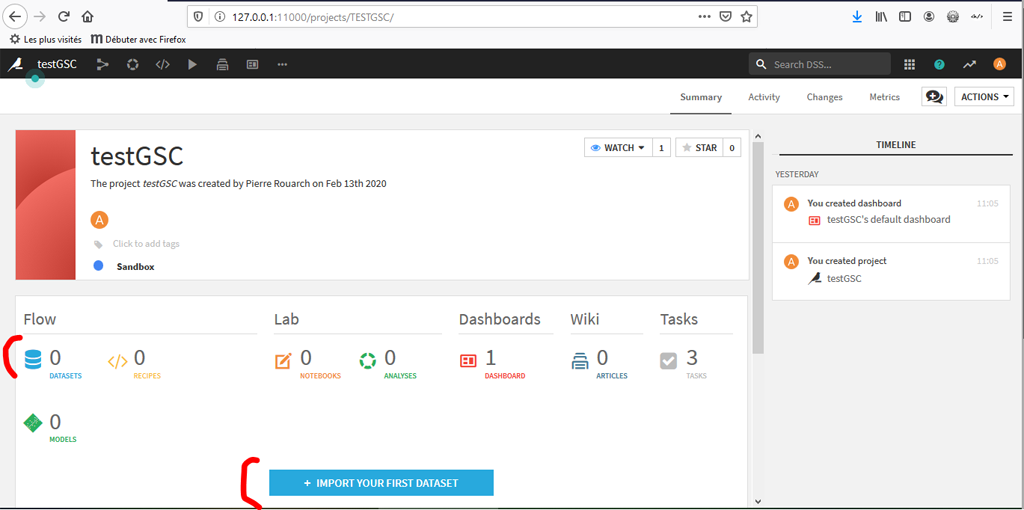
Comme notre plugin est du type « Dataset » cliquez sur « Datasets » ou sur « Import your first Dataset »
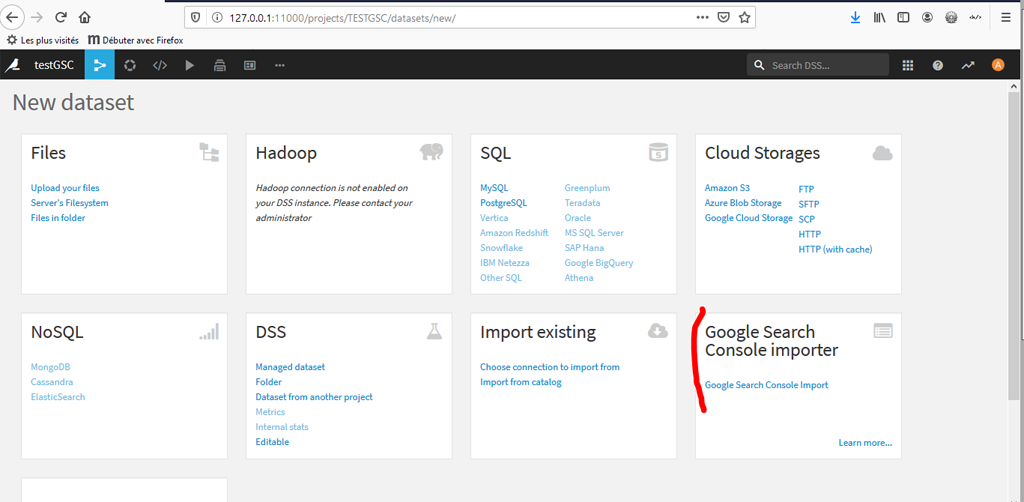
Choisissez « Google Search Console Importer » en bas à droite.
Prévisualisation des données
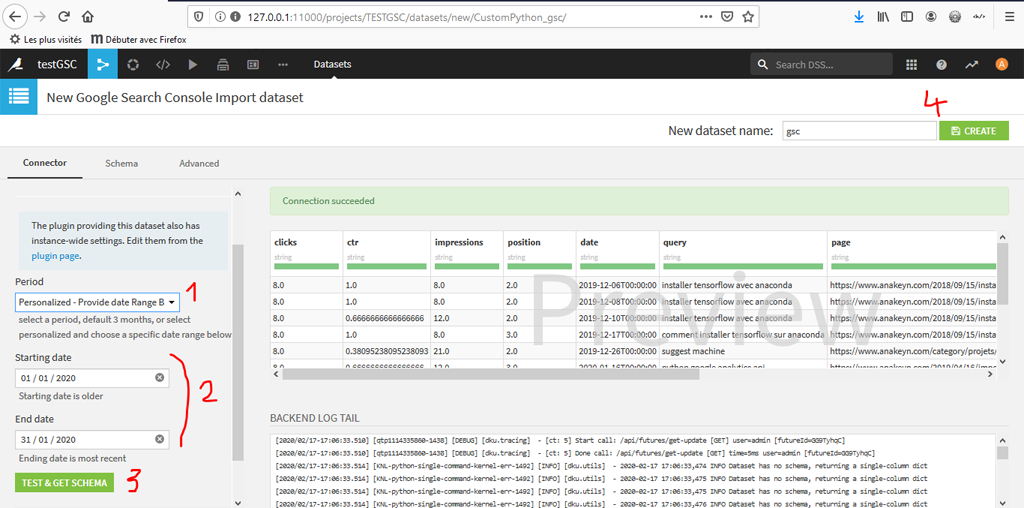
Procédure pour prévisualiser les données
- Choix de la période
Les périodes prédéfinies sont les mêmes que celle dans Google Search Console : 1 jour, 7 jours, 28 jours … Personnalisées
- Date de début et de fin
Si vous avez choisi une période personnalisée. En ce qui nous concerne nous avons opté pour le mois de janvier 2020.
- Test & Schéma
Lancer la procédure. Cela peut prendre un certain temps si la période que vous avez choisie est longue et/ou que vous avez beaucoup de données dans Google Search Console.
- Créer le Dataset
Si tout est ok, donnez un nom au Dataset et créez-le
Première Visualisation des données
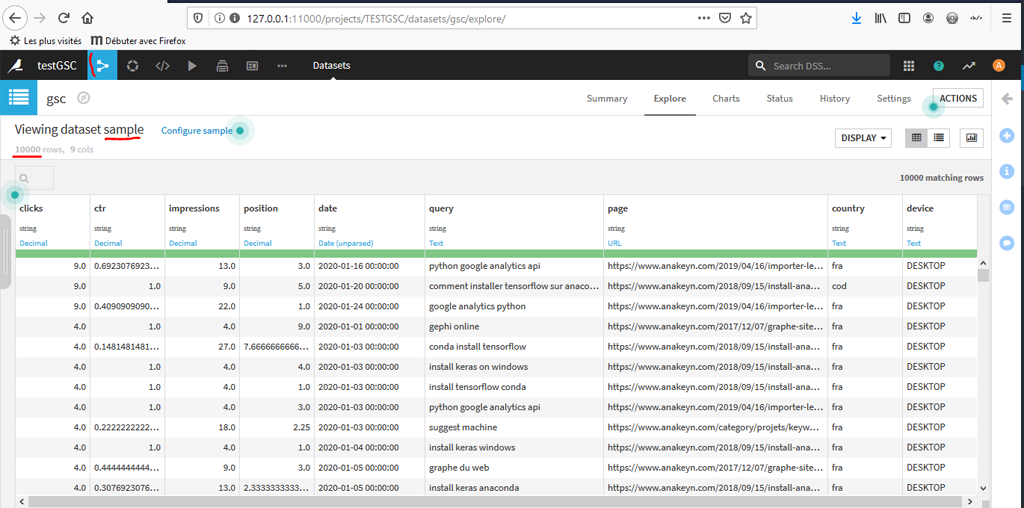
Comme vous pouvez le constater, Dataiku échantillonne les données par défaut à un maximum de 10000 enregistrements.
Ceci est très pratique pour préserver la ressource mais ne nous arrange pas à ce stade. Malheureusement, l’option « configure sample » ne permet pas de choisir d’utiliser toutes les données. Cette option nous permet seulement de déterminer la taille de l’échantillon, or on ne connait pas la taille globale de notre jeu de données.
Pour cela on va retourner au « Flux » de notre projet : icône « < » en haut à gauche, puis « Flow »
Calcul du nombre d’enregistrements
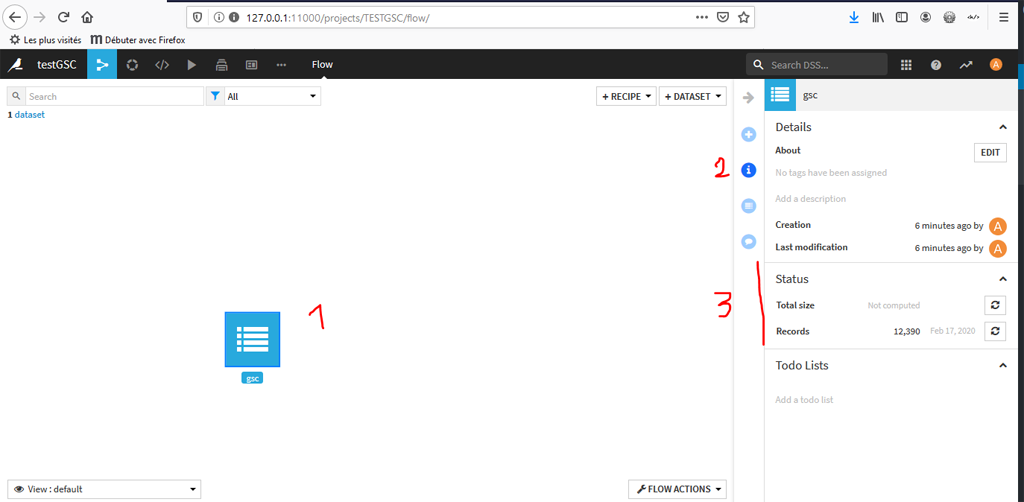
- Sélectionnez le dataset GSC.
- Sélectionnez l’option « détails » : petit icône « i ».
- Sélectionnez « compute » et « compute records » pour calculez le nombre d’enregistrements.
- Notez bien le nombre d’enregistrements (pour nous ici 12390).
- Puis double – cliquez sur l’icône du Dataset pour revenir à la page de visualisation des données.
Modification de la taille de l’échantillon
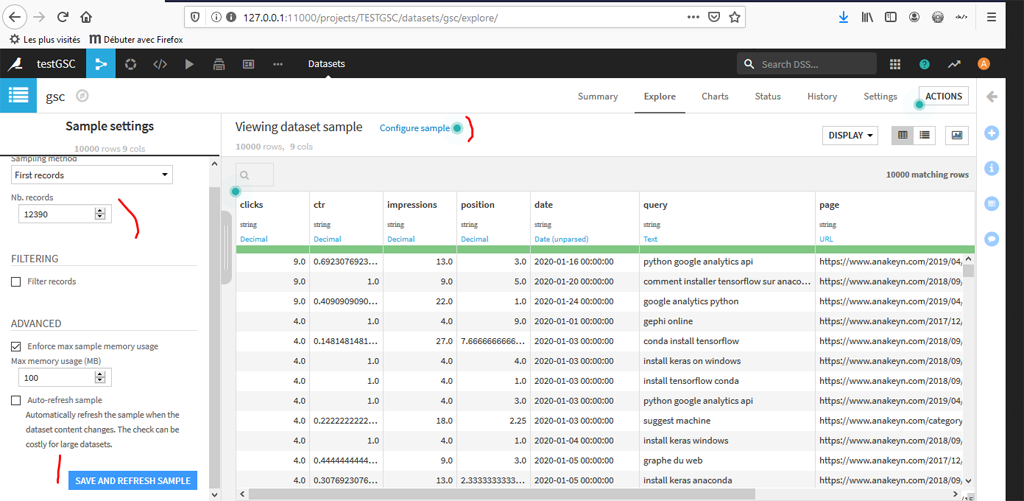
- Cliquez sur « configure sample » -> l’onglet de gauche s’ouvre.
- Indiquez le nouveau nombre d’enregistrements,
- et Validez.
- Retournez ensuite à la page de « Flow ».
Préparation des données
Si vous êtes attentif vous avez peut-être constaté que les données n’étaient pas tout à fait au bon format (par exemple des chaines pour des entiers) .
Nous allons donc utiliser une « Recette » (« Recipe ») pour préparer les données au format qui nous intéresse.
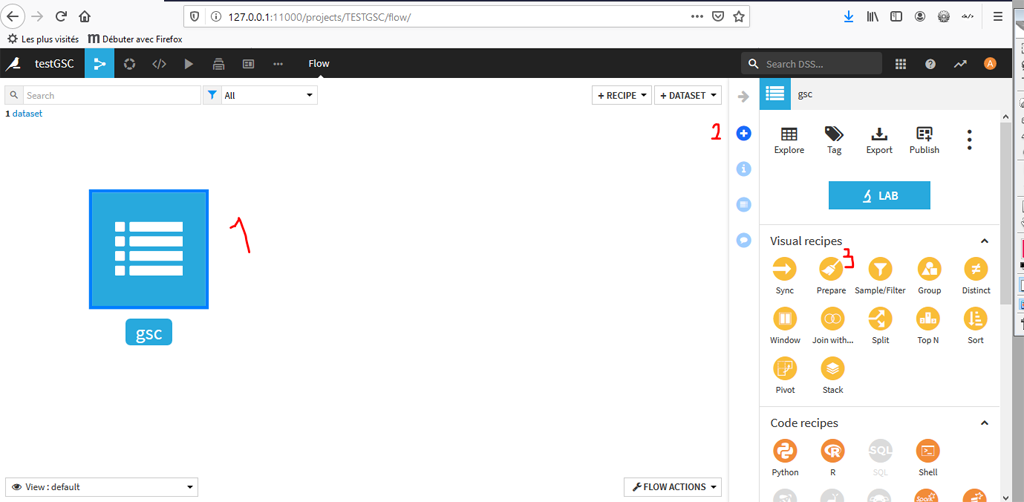
- Cliquez sur le Dataset
- Cliquez sur l’icône « + » : »Actions » pour faire apparaitre les recettes.
- Choisissez « Prepare » dans les recettes visuelles.
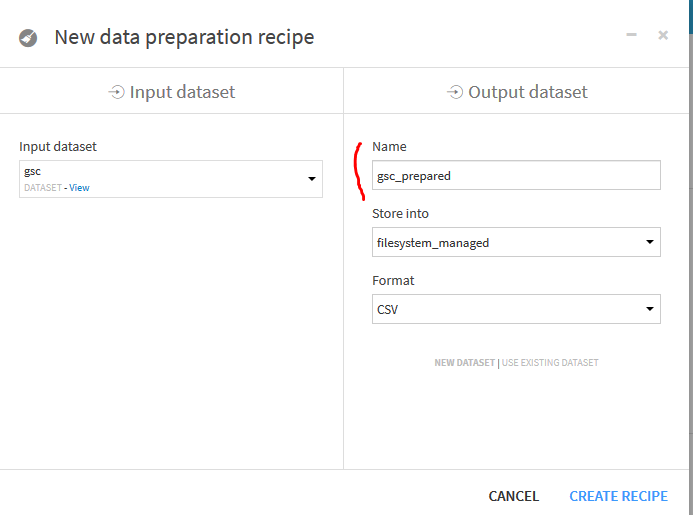
Indiquez un nom pour le prochain dataset et laissez les autres options par défaut et validez.
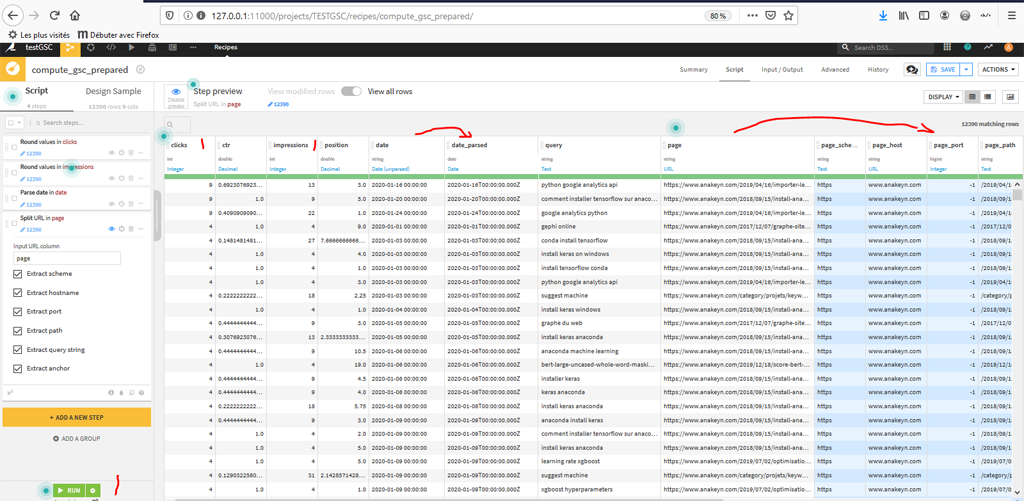
On va nettoyer les données ici :
- Clicks : arrondi et format entier
- Impressions : arrondi et format entier
- Date : création de « date_parsed » au format date et non pas chaîne de caractères.
- Page : découpez l’URL pour récupérer notamment le path dans la page pour avoir un affichage plus court des noms pour nos futurs graphiques.
- Cliquez sur « Run » pour prendre en compte les modifications.
- Attendez la fin du « job » (affichage en bas) et retournez au « Flow ».
Filtrage des données
Cette étape a pour but de ne conserver que les clicks > 0, c’est à dire les impressions qui ont généré du trafic.
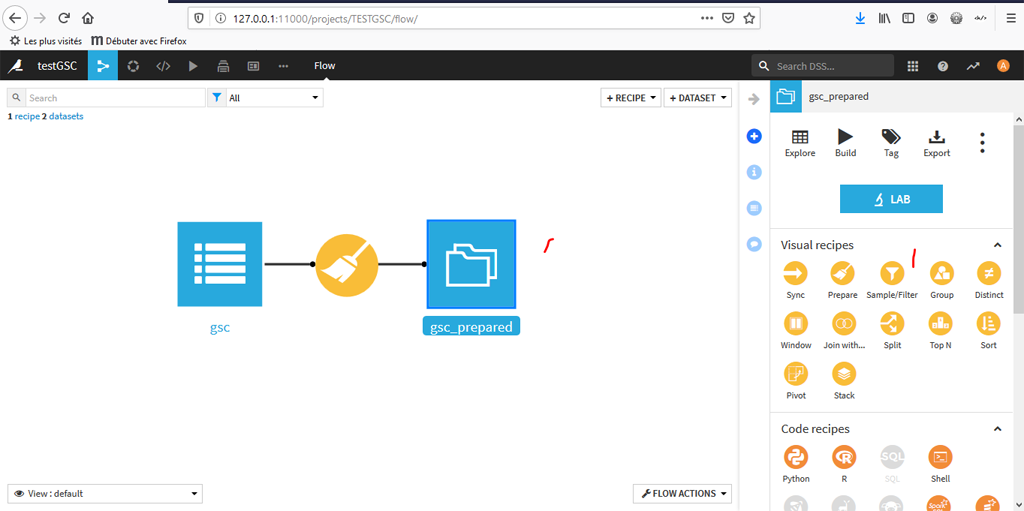
Avec le Dataset « gsc_prepared » choisissez la recette filtrage « Sample/Filter » :
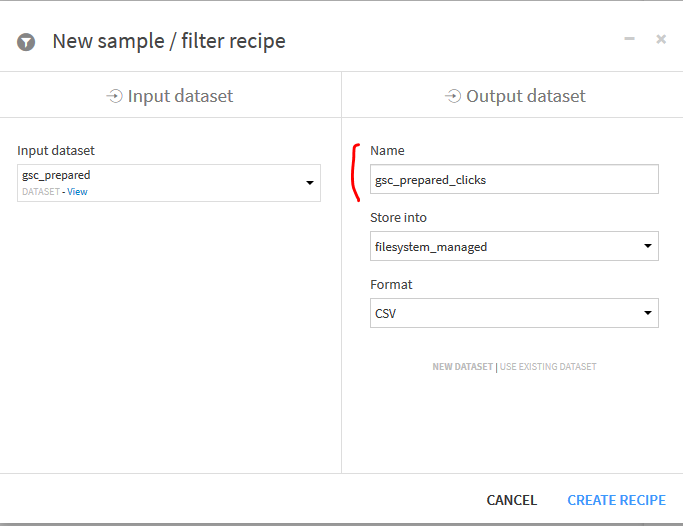
Indiquer un nom pour le Dataset en sortie, ici « gsc_prepared_clicks » et laissez les autres données par défaut.
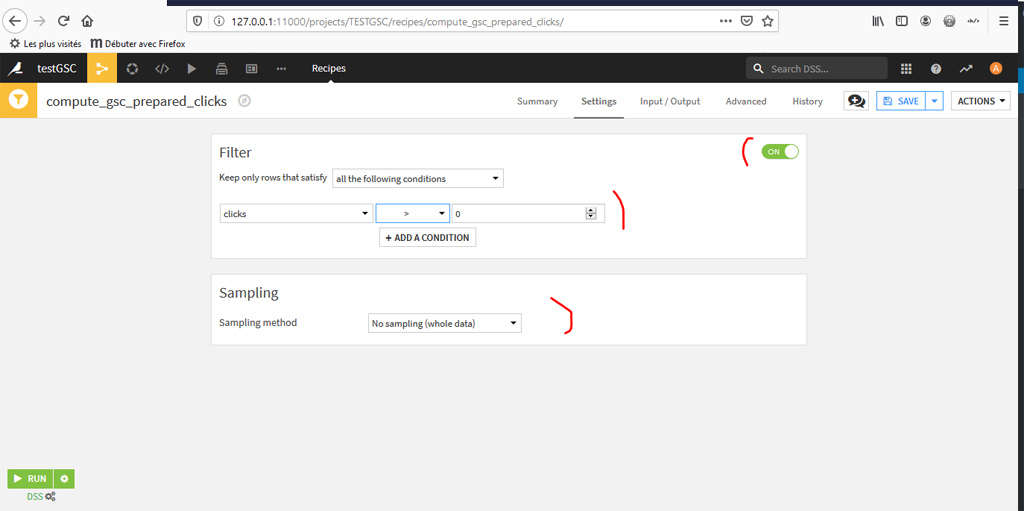
Cliquez sur « On » pour activer le filtrage ; déterminez la condition ici clicks > 0 ; Indiquez l’échantillonnage, ici on travaille sur tout le Dataset ; Puis « Run » en bas à gauche.
Une fois le job terminé, vous pouvez aller voir les résultats :
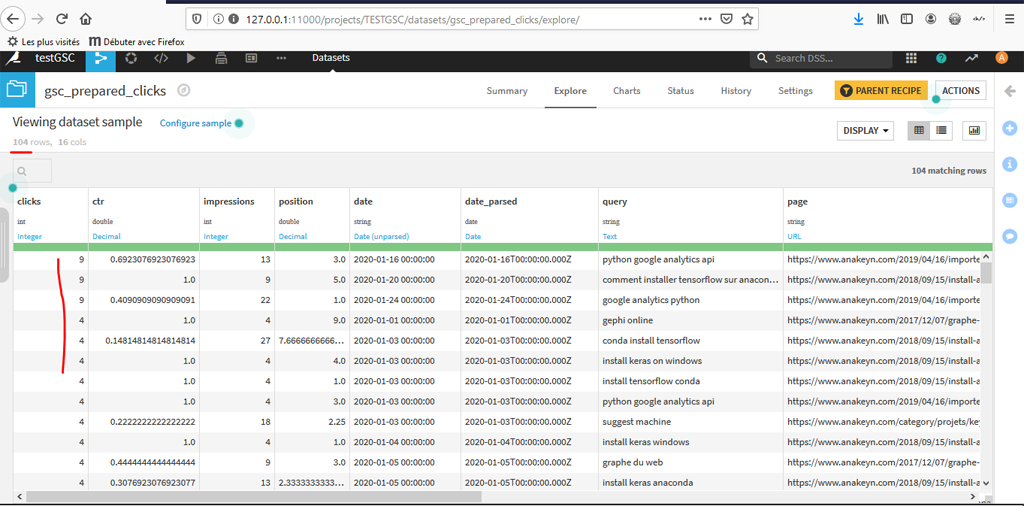
Comme vous pouvez le constater, le jeu de données comporte 104 lignes. Mais il y a des lignes ou l’on a plusieurs clics. Or, pour avoir un jeu de données propre concernant les clics, il faudrait que l’on ait une observation de clic par ligne sinon on va biaiser les calculs de moyennes quand on fera des regroupement par la suite.
Malheureusement, il n’existe pas (ou je ne l’ai pas trouvée) de recette toute faite dans DSS pour dupliquer les lignes en fonction d’une valeur dans une colonne. On parle ici de ranger les données, en anglais « tidying data ».
Nous allons donc la développer en Python.
Ranger les données par clics
Revenez au flow :
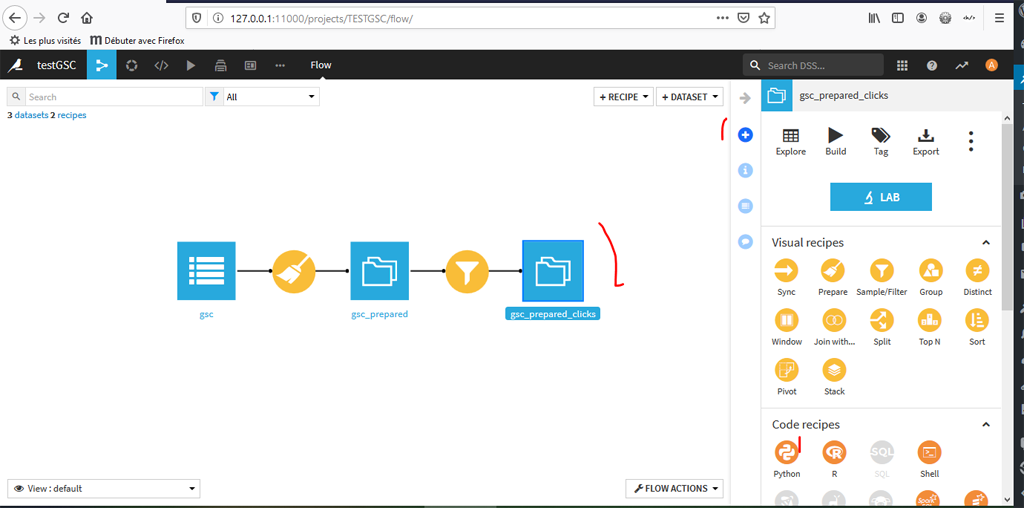
Sélectionnez le Dataset « gsc_prepared_clicks », vérifiez que vous êtes dans le mode « Actions » (« + ») et sélectionnez la Recette par code « Python ».
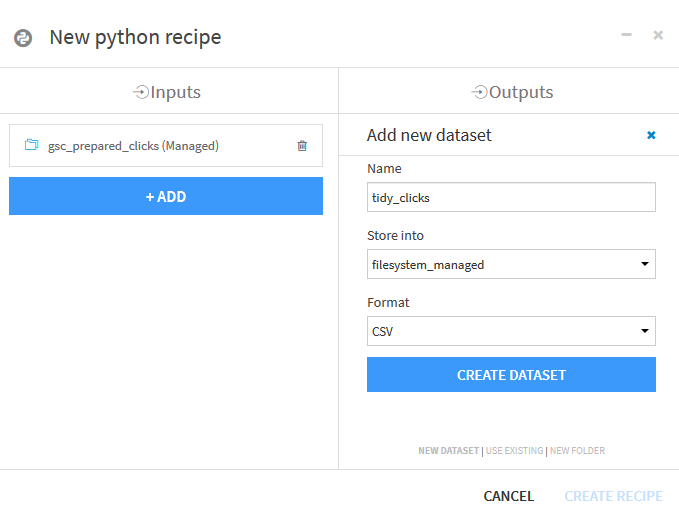
Choisissez le nom du Dataset en sortie, pour nous « tidy_clicks », créez-le et créez la recette.
Le système ouvre un éditeur de code avec le code de base d’une fonction recette Python :
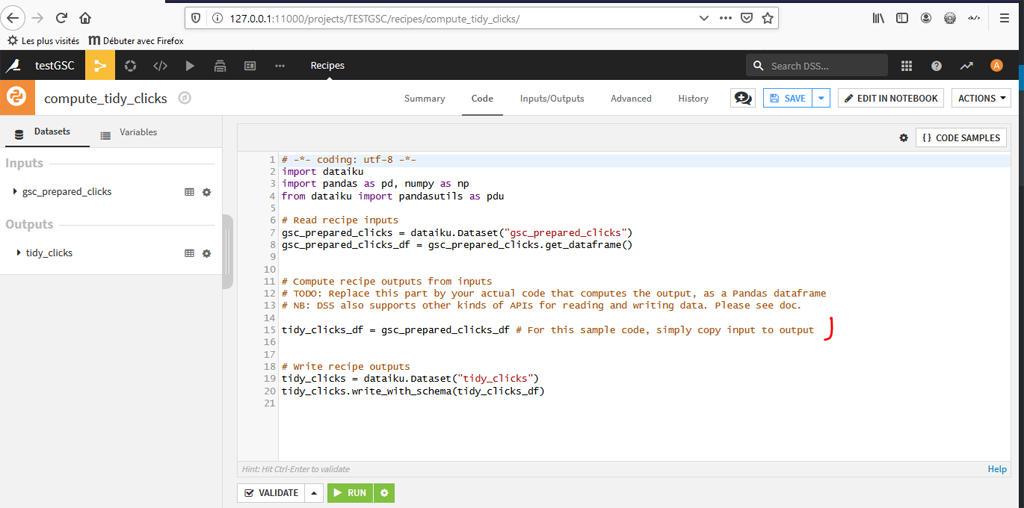
Remplacez le code suivant :
tidy_clicks_df = gsc_prepared_clicks_df # For this sample code, simply copy input to output
Par le code suivant :
# New Code by Pierre Rouarch df = gsc_prepared_clicks_df #More convenient to work with a small dataframe name df = df.loc[df.index.repeat(df['clicks'])] #split in multiple rows according to clicks value df.reset_index(inplace=True, drop=True) #reset index df['impressions'] = df['impressions'].astype(float) #change impressions datatype in float df['impressions']= df.apply(lambda x : x['impressions']/x['clicks'],axis=1) #recalculate impressions for one click df['clicks'] = 1 #all clicks to one. tidy_clicks_df = df #set back to good name
Voyons le résultat :
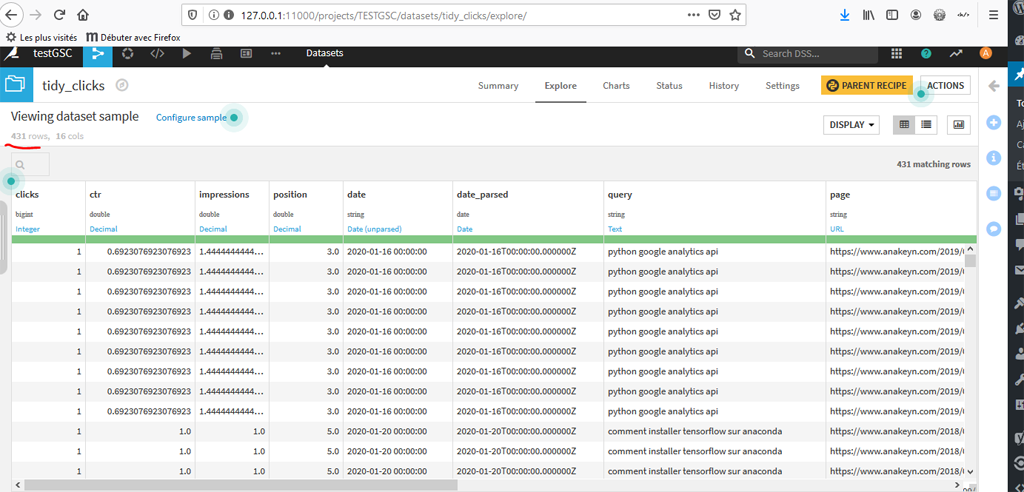
On constate que l’on a bien 431 lignes de 1 clic donc 431 clics.
Regrouper les clics par page pour comparer avec Google Analytics
Pour cela retournez sur le flow :
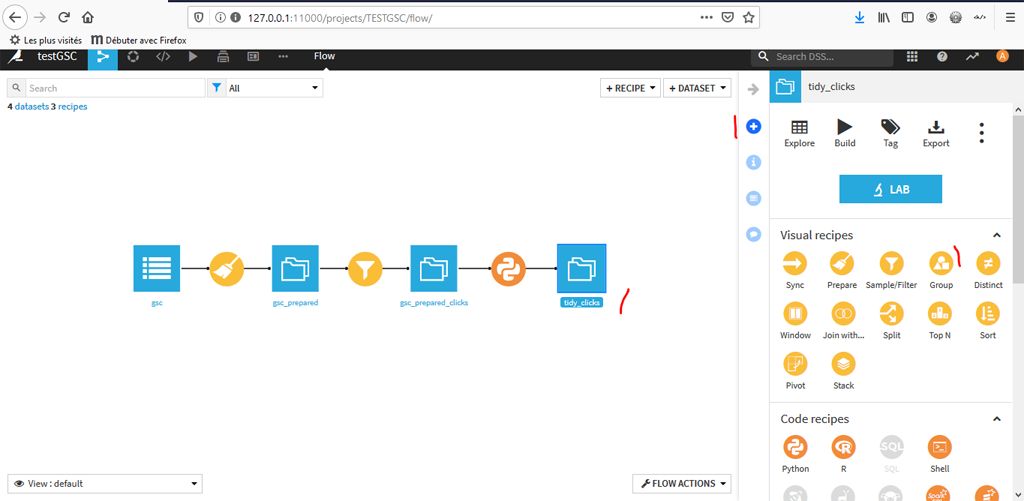
avec « tidy_clicks » choisissez la recette « Group »
Dans la fenêtre :
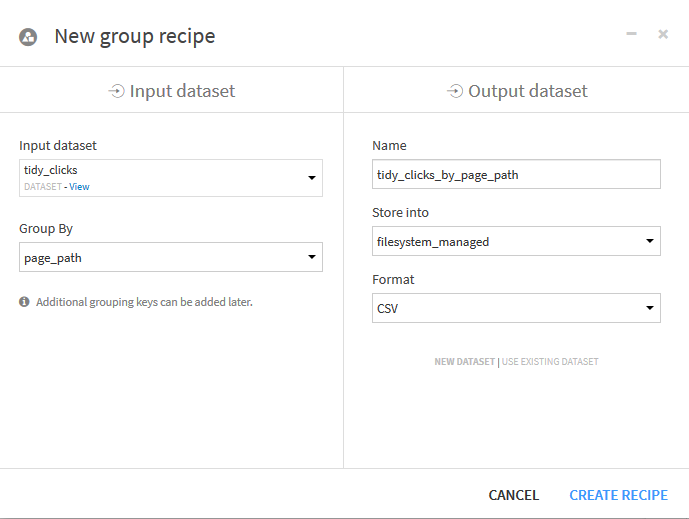
Choisissez le regroupement par page_path (plutôt que page pour des raisons d’affichage) , la page de la recette s’affiche :
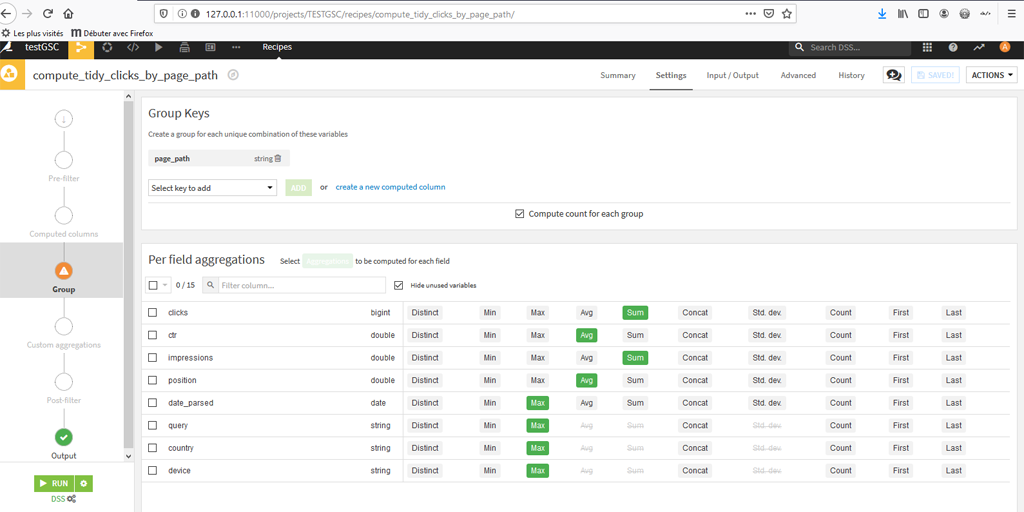
Choisissez les métriques (qui portent sens) pour les variables, suite au groupement par pages. Cliquez sur « Run » une fois vos choix effectués.
Visualisez le jeu de données et triez par « clicks_sum » :
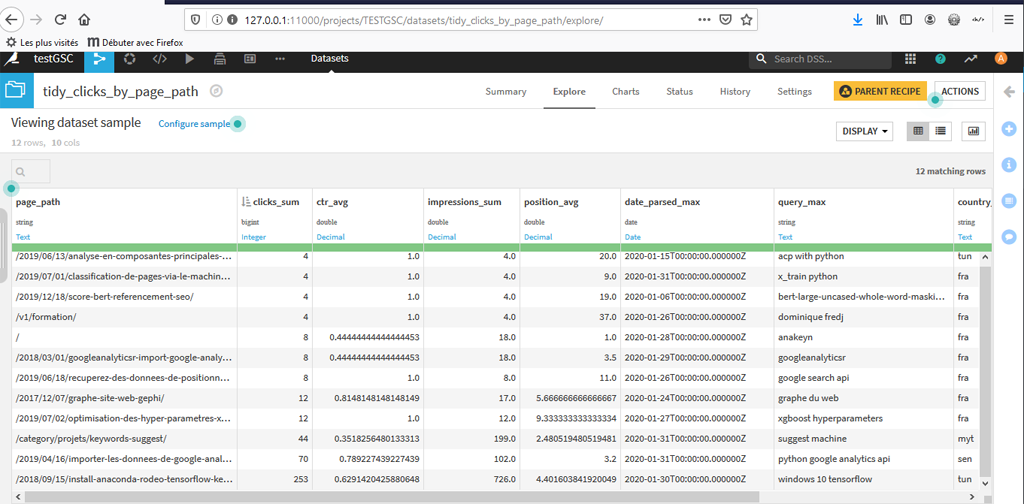
Le système n’a repéré que 12 pages recevant des clicks.
Remarque : sur les pages d’exploration des jeux de données, Dataiku ne permet pas de faire un tri descendant. Ce qui est bien dommage. Pour pouvoir faire des tris descendants il faut passer par la recette « sort ».
Par curiosité allons comparer avec les données de Google Analytics :
Pour cela, pour la même période allez dans Acquisition -> All Traffic -> Channel – > Organic Search -> Changez la 1ere dimension en « source » -> « google » -> ajoutez une seconde dimension : « Landing Page »
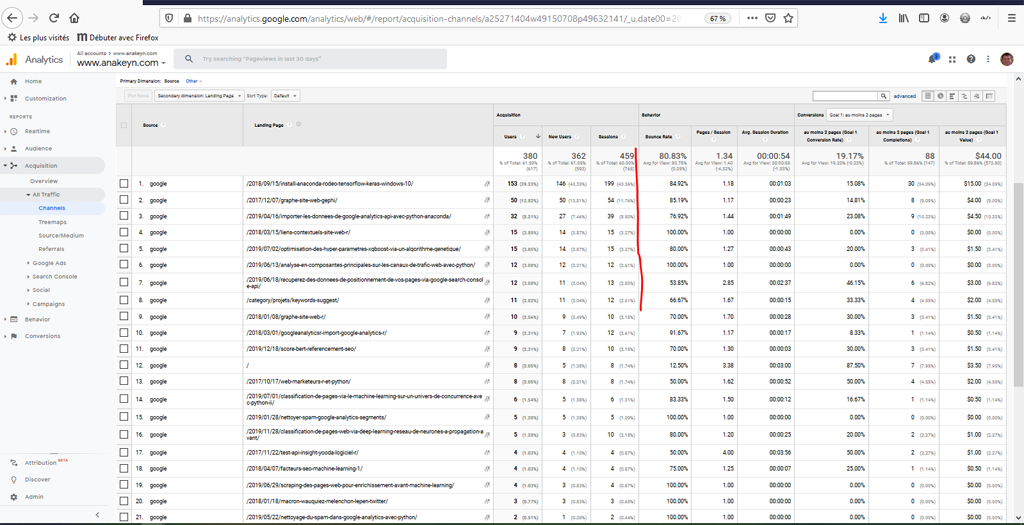
Pour info Google Analytics a repéré 33 pages ayant reçu du Trafic de Google.
La variable qui nous intéresse ici est la variable Sessions que l’on peut comparer à « clicks » dans Google Search Console.
Comme vous pouvez le constater nous n’avons pas tout à fait les mêmes résultats.
Il faut préciser que l’API de Google Search Console ne fournit par des données précises sur les requêtes et les pages et fait de l’échantillonnage. Pour pouvoir dimensionner les clicks nous avons utilisé dans notre programme une méthode brute de règle de 3 qui n’est pas très précise.
Il faudrait pouvoir affiner le modèle avec des méthodes statistiques et corriger les données de Google Search Console avec les données de Google Analytics, notamment si l’on veut récupérer les mots clés « not provided » de façon plus précise.
Regrouper les clicks par requêtes (et pages)
Pour cela retournons au flow et choisissons à nouveau le dataset Tidy_clicks que nous allons utiliser avec une nouvelle recette « Group ».
Cette fois choisissez « query » comme première variable de regroupement.
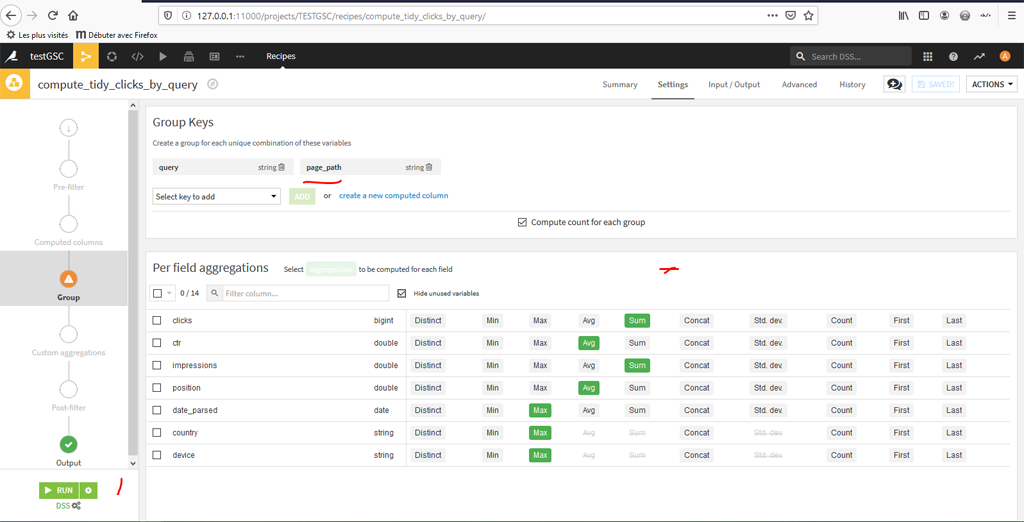
On ajoute « page_path » comme seconde variable de regroupement et on indique les variables et les métriques que l’on souhaite. Puis « Run ».
Une fois sur le descriptif du dataset par requête et par page :
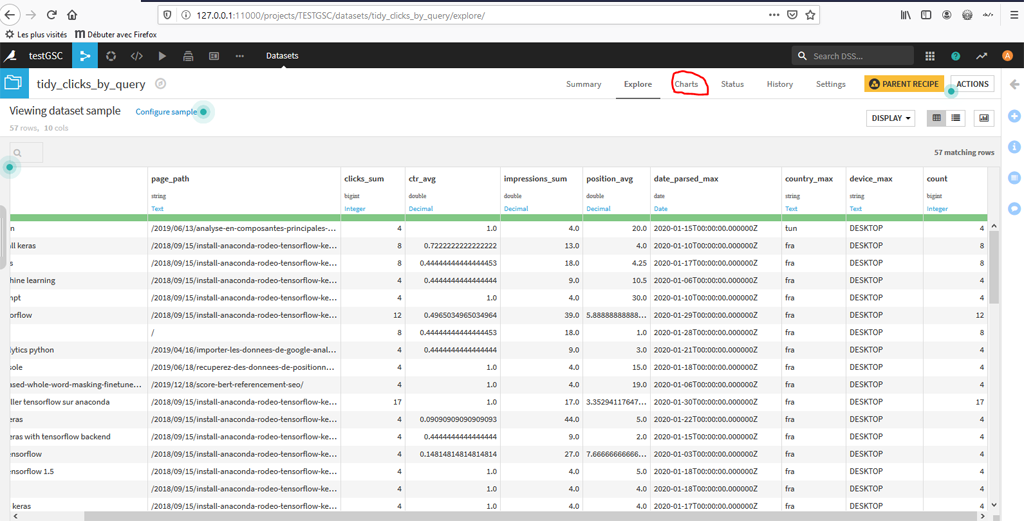
Vous pouvez aller sur l’onglet « Charts » pour créer un graphique :
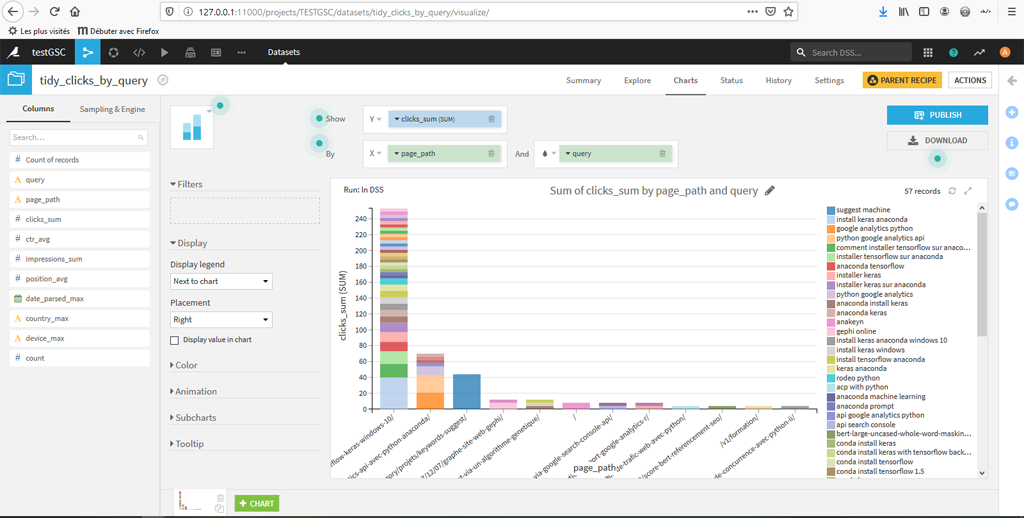
Ici nous avons choisi en X les pages et les requêtes et en Y la somme des clics. Cela ne se voit pas ici mais dans le logiciel, le graphique est dynamique et permet d’afficher le nombre de clics par page et par requête quand on passe la souris sur une zone.
Nous allons maintenant nous intéresser au code source du Plugin.
Code Source
Retournez à la page de notre plugin : Icône Grille ->Plugins-> installed -> Google Search Console Imported :
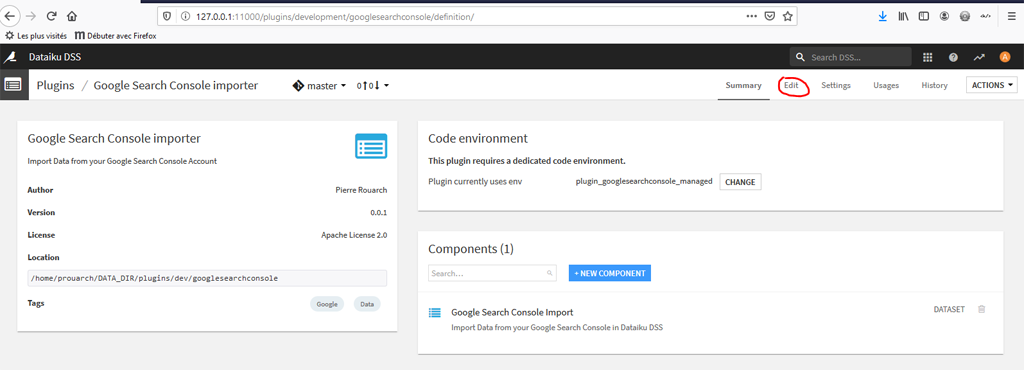
Cliquez sur l’onglet « Edit » pour voir le code source. A gauche vous pouvez voir la structure du plugin et les différents fichiers.
J’ai développé tous les répertoires dans le graphique ci-dessous :
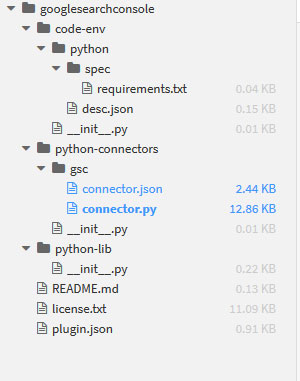
Le plugin contient 3 répertoires principaux :
- code-env : correspond à des informations concernant l’environnement d’exécution du Plugin.
- python-connectors : c’est le répertoire pour les plugins de type connecteur
- python-lib : c’est le répertoire réservé pour écrire des fonctions annexes afin de ne pas surcharger les composants. Il s’agit d’une convention proposée par Dataiku mais qui n’est pas obligatoire. Dans notre cas le ce répertoire ne contient aucune fonction.
Voyons les différents fichiers importants :
Fichier des paramètres du Plugin : plugin.json
Le fichier à la racine qui nous intéresse est « plugin.json ». Il décrit le plugin et permet aussi de déclarer les variables à paramétrer au niveau plugin :
{
"id" : "googlesearchconsole",
"version" : "0.0.1",
"meta" : {
"label" : "Google Search Console importer",
"description" : "Import Data from your Google Search Console Account",
"author" : "Pierre Rouarch",
"icon" : "icon-list-alt",
"licenseInfo" : "Apache License 2.0",
"url" : "https://github.com/Anakeyn/Dataiku-DSS-Anakeyn-GoogleSearchConsole",
"tags" : ["Google", "Data"]
},
"params": [
{
"name": "credentials",
"label": "JSON Service Account",
"description": "Copy/paste the JSON provided by Google, or a path to a file containing the JSON.",
"type": "TEXTAREA",
"mandatory" : true
},
{
"name": "webSite",
"label" : "Url website",
"type": "STRING",
"description":"url of your website. e.g : https://www.anakeyn.com",
"mandatory" : true
}
]
}
Comme vous pouvez le voir, c’est ici que l’on déclare les paramètres que l’on saisit dans Settings : credentials et webSite
Fichier des paramètres d’environnement desc.json
il se situe dans le sous répertoire /code-env/python et contient les informations concernant le Python à installer dans l’environnement du plugin.
{
"acceptedPythonInterpreters": ["PYTHON36", "PYTHON37"],
"forceConda": false,
"installCorePackages": true,
"installJupyterSupport": false
}
Fichier des bibliothèques requises requirements.txt
il se situe dans le sous répertoire /code-env/python/spec. C’est dans ce fichier que l’on indique les bibliothèques qui ne sont pas de base dans Python ou alors des versions spécifiques souhaitées, notamment pour éviter des conflits.
oauth2client google-api-python-client
Fichier des paramètres au niveau du composant connecteur : connector.json
Ce fichier se trouve dans le sous répertoire /python-connectors/gsc. Il indique les caractéristiques du composant et les paramètres que doit saisir l’utilisateur pour utiliser celui-ci.
Pour nous il s’agit des périodes pour les données à rapatrier de Google Search Console.
/* This file is the descriptor for the Custom python dataset googlesearchconsole */
{
"meta" : {
// label: name of the dataset type as displayed, should be short
"label" : "Google Search Console Import",
// description: longer string to help end users understand what this dataset type is
"description" : "Import Data from your Google Search Console in Dataiku DSS",
// icon: must be one of the FontAwesome 3.2.1 icons, complete list here at https://fontawesome.com/v3.2.1/icons/
"icon": "icon-list"
},
/* Can this connector read data ? */
"readable" : true,
/* Can this connector write data ? */
"writable" : true,
"canCountRecords" : false, /*not used */
/* params:
DSS will generate a formular from this list of requested parameters.
Your component code can then access the value provided by users using the "name" field of each parameter.
Available parameter types include:
STRING, INT, DOUBLE, BOOLEAN, DATE, SELECT, TEXTAREA, PRESET and others.
For the full list and for more details, see the documentation: https://doc.dataiku.com/dss/latest/plugins/reference/params.html
*/
"params": [
/* A "SELECT" parameter is a multi-choice selector. Choices are specified using the selectChoice field*/
{
"name": "period",
"label" : "Period",
"type": "SELECT",
"description": "select a period, default 3 months, or select personalized and choose a specific date range below",
"defaultValue" : "3months",
"selectChoices" : [
{ "value" : "1day", "label" : "Last available Day"},
{ "value" : "7days", "label" : "Last 7 days"},
{ "value" : "28days", "label" : "Last 28 days"},
{ "value" : "3months", "label" : "Last 3 months - default"},
{ "value" : "6months", "label" : "Last 6 months"},
{ "value" : "12months", "label" : "Last 12 months"},
{ "value" : "16months", "label" : "Last 16 months"},
{ "value" : "Personalized", "label" : "Personalized - Provide date Range Below"}
],
"mandatory": true
},
{
"name": "from_date",
"label": "Starting date ",
"type": "DATE",
"description":"Starting date is older",
"mandatory" : false
},
{
"name": "to_date",
"label": "End date",
"type": "DATE",
"description":"Ending date is most recent",
"mandatory" : false
}
]
}
Code source en Python du composant : connector.py
Ce fichier se trouve dans le sous répertoire /python-connectors/gsc.
Les fichiers connector.py sont tous construits sur la même trame fournie par Dataiku.
Le Connecteur que l’on crée est sous la forme d’une classe « Connector » définie par Dataiku.
Il contient des fonctions qui ne sont pas toutes utilisées. Cela dépend des besoins du plugin.
On va découper le code source en plusieurs morceaux pour pouvoir le commenter. Toutefois comme on l’a vu, vous pouvez le récupérer gratuitement en entier dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-python-plugin-import-goolge-search-console-pour-dataiku/
Chargement des bibliothèques utiles :
#for Dataiku from dataiku.connector import Connector #for Dataframes import pandas as pd #Datetime tools from datetime import date from datetime import datetime from datetime import timedelta import os #to read files import json #to manipulate json #for Google Search Console Reporting API V3 with service account from apiclient.discovery import build #from google-api-python-client from oauth2client.service_account import ServiceAccountCredentials #to use a Google Service
Notamment « Connector » depuis Dataiku et les bibliothèques de Google.
Initialisation du Composant
#my Connector Class
class MyConnector(Connector):
def __init__(self, config, plugin_config):
"""
The configuration parameters set up by the user in the settings tab of the
dataset are passed as a json object 'config' to the constructor.
The static configuration parameters set up by the developer in the optional
file settings.json at the root of the plugin directory are passed as a json
object 'plugin_config' to the constructor
"""
Connector.__init__(self, config, plugin_config) # pass the parameters to the base class
#perform some more initialization
SCOPES = ['https://www.googleapis.com/auth/webmasters.readonly']
#DISCOVERY_URI = ('https://www.googleapis.com/discovery/v1/apis/customsearch/v1/rest') #not used
#Plugin parameters (declare in plugin.json )
self.credentials = self.plugin_config.get("credentials")
self.webSite = self.plugin_config.get("webSite")
#Component parameters (deckare in connector.json)
self.period = self.config.get("period")
print(self.period)
if (self.period=="1day") :
self.from_date = date.today() - timedelta(days=2)
self.to_date = date.today() - timedelta(days=1)
if (self.period=="7days") :
self.from_date = date.today() - timedelta(days=8)
self.to_date = date.today() - timedelta(days=1)
if (self.period=="28days") :
self.from_date = date.today() - timedelta(days=29)
self.to_date = date.today() - timedelta(days=1)
if (self.period=="3months") :
self.from_date = date.today() - timedelta(days=30*3)
self.to_date = date.today() - timedelta(days=1)
if (self.period=="6months") :
self.from_date = date.today() - timedelta(days=30*6)
self.to_date = date.today() - timedelta(days=1)
if (self.period=="12months") :
self.from_date = date.today() - timedelta(days=30*12)
self.to_date = date.today() - timedelta(days=1)
if (self.period=="16months") :
self.from_date = date.today() - timedelta(days=30*16)
self.to_date = date.today() - timedelta(days=1)
if (self.period=="Personalized") :
#beware !! dates are in string in the forms, and there is a shift error of one minus day
self.from_date = datetime.strptime( self.config.get("from_date")[:10], '%Y-%m-%d')
#avoid shift error
self.from_date = self.from_date + timedelta(days=1)
self.to_date = datetime.strptime( self.config.get("to_date")[:10], '%Y-%m-%d')
#avoid shift error
self.to_date = self.to_date + timedelta(days=1)
if self.to_date < self.from_date:
raise ValueError("The end date occurs before the start date")
#get JSON Service account credentials from file or from text
file = self.credentials.splitlines()[0]
if os.path.isfile(file):
try:
with open(file, 'r') as f:
self.credentials = json.load(f)
f.close()
except Exception as e:
raise ValueError("Unable to read the JSON Service Account from file '%s'.\n%s" % (file, e))
else:
try:
self.credentials = json.loads(self.credentials)
except Exception as e:
raise Exception("Unable to read the JSON Service Account.\n%s" % e)
#get credentials from service account
credentials = ServiceAccountCredentials.from_json_keyfile_dict(self.credentials, SCOPES)
#open a Google Search console service (previously called Google Webmasters tools)
self.webmasters_service = build('webmasters', 'v3', credentials=credentials)
les paramètres du Plugin sont dans plugin_config et les paramètres du composant sont dans « config ».
Il y a un bug au niveau de l’outil calendrier de Dataiku qui nous renvoie toujours la date de la veille. Donc nous sommes obligés de corriger manuellement ce problème. A suivre si ce problème est corrigé par Dataiku.
Spécification du schéma de données
def get_read_schema(self):
"""
Returns the schema that this connector generates when returning rows.
The returned schema may be None if the schema is not known in advance.
In that case, the dataset schema will be infered from the first rows.
If you do provide a schema here, all columns defined in the schema
will always be present in the output (with None value),
even if you don't provide a value in generate_rows
The schema must be a dict, with a single key: "columns", containing an array of
{'name':name, 'type' : type}.
Example:
return {"columns" : [ {"name": "col1", "type" : "string"}, {"name" :"col2", "type" : "float"}]}
Supported types are: string, int, bigint, float, double, date, boolean
"""
# In this example, we don't specify a schema here, so DSS will infer the schema
# from the columns actually returned by the generate_rows method
return None
Cette fonction n’est pas utilisée et le schéma sera récupéré automatiquement à partir des données.
Génération des lignes de résultats
C’est le cœur de notre programme :
def generate_rows(self, dataset_schema=None, dataset_partitioning=None,
partition_id=None, records_limit = -1):
"""
The main reading method.
Returns a generator over the rows of the dataset (or partition)
Each yielded row must be a dictionary, indexed by column name.
The dataset schema and partitioning are given for information purpose.
"""
print ("Google Search Console plugin - Start generating rows")
print ("Google Search Console plugin - records_limits=%i" % records_limit)
###############################################################################
#Get Data Pages/Queries/positions/Clicks from Google Search Console
###############################################################################
dfAllTraffic = pd.DataFrame() #global dataframe for all traffic calculation
dfGSC = pd.DataFrame() #global dataframe for clicks
#convert dates in strings
myStrStartDate = self.from_date.strftime('%Y-%m-%d')
myStrEndDate = self.to_date.strftime('%Y-%m-%d')
####### Get Global Traffic ##############
maxStartRow = 1000000000 #to avoid infinite loop
myStartRow = 0
while ( myStartRow < maxStartRow):
df = pd.DataFrame() #dataframe for this loop
mySiteUrl = self.plugin_config.get("webSite")
myRequest = {
'startDate': myStrStartDate, #older date
'endDate': myStrEndDate, #most recent date
'dimensions': ["date", "country", "device"],
'searchType': 'web', #for the moment only Web
'rowLimit': 25000, #max 25000 for one Request
"aggregationType": "byPage",
'startRow' : myStartRow # for multiple resquests 'startRow':
}
response = self.webmasters_service.searchanalytics().query(siteUrl=mySiteUrl, body=myRequest).execute()
#set response (dict) in DataFrame for treatments purpose.
df = pd.DataFrame.from_dict(response['rows'], orient='columns')
if ( myStartRow == 0) :
dfAllTraffic = df #save the first loop df in global df
else :
dfAllTraffic = pd.concat([dfAllTraffic, df], ignore_index=True) #concat this loop df with global df
if (df.shape[0]==25000) :
myStartRow += 25000 #continue
else :
myStartRow = maxStartRow+1 #stop
#split keys in date country device
dfAllTraffic[["date", "country", "device"]] = pd.DataFrame(dfAllTraffic["keys"].values.tolist())
dfAllTraffic = dfAllTraffic.drop(columns=['keys']) #remove Keys (not used)
myTotalClicks = dfAllTraffic['clicks'].sum()
myTotalImpressions = dfAllTraffic['impressions'].sum()
####### Get Pages/Queries/positions/Clicks ##############
maxStartRow = 1000000000 #to avoid infinite loop
myStartRow = 0
while ( myStartRow < maxStartRow):
df = pd.DataFrame() #dataframe for this loop
mySiteUrl = self.plugin_config.get("webSite")
myRequest = {
'startDate': myStrStartDate, #older date
'endDate': myStrEndDate, #most recent date
'dimensions': ["date", "query","page","country","device"], #all available dimensions ?
'searchType': 'web', #for the moment only Web
'rowLimit': 25000, #max 25000 for one Request
'startRow' : myStartRow # for multiple resquests 'startRow':
}
response = self.webmasters_service.searchanalytics().query(siteUrl=mySiteUrl, body=myRequest).execute()
#set response (dict) in DataFrame for treatments purpose.
df = pd.DataFrame.from_dict(response['rows'], orient='columns')
if ( myStartRow == 0) :
dfGSC = df #save the first loop df in global df
else :
dfGSC = pd.concat([dfGSC, df], ignore_index=True) #concat this loop df with global df
if (df.shape[0]==25000) :
myStartRow += 25000 #continue
else :
myStartRow = maxStartRow+1 #stop
#split keys in date query page country device
dfGSC[["date", "query", "page", "country", "device"]] = pd.DataFrame(dfGSC["keys"].values.tolist())
dfGSC = dfGSC.drop(columns=['keys']) #remove Keys (not used)
mySampleClicks = dfGSC['clicks'].sum()
mySampleImpressions = dfGSC['impressions'].sum()
#Recalculate new clicks and Impressions
#recalculate All Clicks according to clicks volume ratio (we privilegiate clicks accuracy)
dfGSC['allClicks'] = dfGSC.apply(lambda x : round((x['clicks']*myTotalClicks)/mySampleClicks, 0),axis=1)
#Recalculate news All Impressions according to clicks volume ratio
dfGSC['allImpressions'] = dfGSC.apply(lambda x : round((x['impressions']*myTotalClicks)/mySampleClicks, 0),axis=1)
#Reclaculate news All ctr according to new All impressions and Clicks
dfGSC['allCTR'] = dfGSC.apply(lambda x : x['allClicks']/x['allImpressions'],axis=1)
#remove bad dates
#Change string date in datetime
dfGSC['date'] = dfGSC.apply(lambda x : datetime.strptime( x['date'][:10], '%Y-%m-%d'),axis=1)
mask = (dfGSC['date'] >= self.from_date) & (dfGSC['date'] <= self.to_date)
dfGSC = dfGSC.loc[mask]
dfGSC.reset_index(inplace=True, drop=True) #reset index
#remove old clicks, ctr and impression columns
dfGSC = dfGSC.drop(columns=['clicks', 'ctr', 'impressions'])
#rename All impressions, ctr and clicks in old names
dfGSC.rename(columns={'allImpressions':'impressions', 'allClicks':'clicks', 'allCTR':'ctr'}, inplace=True)
#reorganise in orignal order clicks, ctr, impressions, positions, date, query, page, country, device
dfGSC = dfGSC[["clicks", "ctr", "impressions", "position", "date", "query", "page", "country", "device"]]
#send rows got in dataframe transformed in dict
for row in dfGSC.to_dict(orient='records'):
yield row #Each yield in the generator becomes a row in the dataset.
Si vous êtes attentif, vous aurez constaté que nous faisons appel 2 fois à l’API de Google.
En effet, Google, c’est un peu comme la mécanique quantique ou on ne peut pas avoir à la fois la position et la quantité de mouvement d’une particule.
Ici, on ne peut pas avoir à la fois le volume de recherche et les contenus en pages et requêtes.
L’explication de Google à ce sujet est sur la page : https://developers.google.com/webmaster-tools/search-console-api-original/v3/how-tos/all-your-data.html#lose_data

Mon Dieu ! Google manquerait-il de ressources ? 🙂
Afin de récupérer un trafic cohérent nous avons fait un rapide calcul qu’il conviendrait toutefois d’affiner, pour mieux s’approcher de la réalité.
Fin du code source
les dernières fonctions ne sont pas utilisées.
def get_writer(self, dataset_schema=None, dataset_partitioning=None,
partition_id=None):
"""
Returns a write object to write in the dataset (or in a partition)
The dataset_schema given here will match the the rows passed in to the writer.
Note: the writer is responsible for clearing the partition, if relevant
"""
raise Exception("Unimplemented")
def get_partitioning(self):
"""
Return the partitioning schema that the connector defines.
"""
raise Exception("Unimplemented")
def get_records_count(self, partition_id=None):
"""
Returns the count of records for the dataset (or a partition).
Implementation is only required if the field "canCountRecords" is set to
true in the connector.json
"""
raise Exception("unimplemented")
Merci de votre attention,
Questions, remarques, bienvenues en commentaires,
A bientôt,
Pierre