

Partager la publication "Classification de pages via le Machine Learning sur un univers de concurrence avec Python – I."
Cet article fait suite aux 3 articles précédents :
- Classification de pages Web pour le SEO via le Machine Learning avec Python
- Récupérez des données de positionnement de vos pages via Google Search Console API
- Modèle Interne : test de classification de pages via le Machine Learning pour un seul site
Dans ce nouvel article nous allons répéter ce que nous avons fait dans l’article précédent, mais cette fois, dans l’univers de concurrence du site de Networking-Morbihan.
Pour déterminer cet univers de concurrence, il nous faut trouver les compétiteurs qui se positionnent sur les mêmes mots clés que ceux de Networking Morbihan dans les résultats de recherche.
Pour obtenir cela, nous pourrions passer par l’API de SEMrush ou bien celle de Yooda qui nous permettent de récupérer des couples URLs/Positions pour des expressions données. Mais ceci à un certain coût.
Comme nous avons un nombre assez restreint de mots clés à tester (487 quand même) nous allons utiliser un scraper de SERPs développé en Python et qui devrait pouvoir suffire :
Googlesearch par Mario Vilas
Afin de pouvoir scraper Google nous allons utiliser la bibliothèque googlesearch qui a été développée par Mario Vilas. Le code source se trouve sur Github à l’adresse https://github.com/MarioVilas/googlesearch et la documentation à l’adresse https://python-googlesearch.readthedocs.io/en/latest/.
Cette bibliothèque fonctionne correctement, toutefois elle ne permet pas de paramétrer des proxies, ce qui vous oblige à paramétrer des temps de pauses importants pour éviter de vous faire jeter par Google.
Si vous connaissez un bibliothèque qui permet de paramétrer des proxies, n’hésitez pas à nous en faire part. Sinon, si j’ai un peu de temps je modifierais googlesearch dans le futur, pour la rendre exploitable dans un produit fini.
De quoi aurons nous besoin ?
Python Anaconda
Rendez vous sur la page de téléchargement d’Anaconda Distribution pour télécharger la version de Python Anaconda qui vous convient selon votre ordinateur.
Jeu de données
Nous partons du jeu de données dfGSC1-MAI.json créé lors de la phase précédente. Vous pouvez télécharger l’archive contenant ces données sur notre GitHub. Dézipper le fichier dans le répertoire qui contient votre programme source Python.
Code Source
Vous pouvez soit copier/coller les morceaux de codes ci-dessous, soit récupérer le code source en entier gratuitement dans notre boutique : https://www.anakeyn.com/boutique/produit/script-python-ml-sur-concurrence-i/
Récupération des bibliothèques utiles et définition de la fonction TF*IDF
Ici nous ne présentons que la fonction utilisant la TfidfVectorizer de scikit-learn. Pour plus de détail sur la notion de TF*IDF, reportez vous à notre article précédent : Modèle Interne : test de classification de pages via le Machine Learning pour un seul site .
# -*- coding: utf-8 -*-
"""
Created on Mon Jun 17 18:39:18 2019
@author: Pierre
"""
##########################################################################
# GSCCompetitorsML1 - - modifié le 26/11/2019
# Auteur : Pierre Rouarch - Licence GPL 3
# Machine Learning sur un univers de concurrence Partie 1
# focus sur la précision du set de test plutot que le F1 Score global
#####################################################################################
###################################################################
# On démarre ici
###################################################################
#Chargement des bibliothèques générales utiles
import numpy as np #pour les vecteurs et tableaux notamment
import matplotlib.pyplot as plt #pour les graphiques
#import scipy as sp #pour l'analyse statistique
import pandas as pd #pour les Dataframes ou tableaux de données
import seaborn as sns #graphiques étendues
#import math #notamment pour sqrt()
import os
from urllib.parse import urlparse #pour parser les urls
import nltk # Pour le text mining
# Machine Learning
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
#Matrice de confusion
from sklearn.metrics import confusion_matrix
#pour les scores
from sklearn.metrics import f1_score
#from sklearn.metrics import matthews_corrcoef
from sklearn.metrics import accuracy_score
#pip install google #pour installer la library de Google Search de Mario Vilas
#https://python-googlesearch.readthedocs.io/en/latest/
import googlesearch #Scrap serps
#pour randomize pause
import random
import time #pour calculer le 'temps' de chargement de la page
import gc #pour vider la memoire
print(os.getcwd()) #verif
#mon répertoire sur ma machine - nécessaire quand on fait tourner le programme
#par morceaux dans Spyder.
#myPath = "C:/Users/Pierre/MyPath"
#os.chdir(myPath) #modification du path
#print(os.getcwd()) #verif
############################################
# Calcul de la somme des tf*idf
#somme des TF*IDF pour chaque colonne de tokens calculé avec TfidfVectorizer
def getSumTFIDFfromDFColumn(myDFColumn) :
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = myDFColumn.apply(' '.join)
vectorizer = TfidfVectorizer(norm=None)
X = vectorizer.fit_transform(corpus)
return np.sum(X.toarray(), axis=1)
Récupération du jeu de données et préparation des expressions à scraper dans Google.
On enlève les requêtes en doublon pour éviter du scraping de SERPs inutiles.
#####################################################################################
# MODELE "UNIVERS DE CONCURRENCE" -
# A partir des mots clés récupérés depuis Google Search Consol
# On va récupérer les pages/positions/mots clés grâce à un crawler de SERPs :
# GoogleSearch
# Code source : https://github.com/MarioVilas/googlesearch
# #doc https://python-googlesearch.readthedocs.io/en/latest/
#######################################################################################
#Relecture ############
dfGSC1 = pd.read_json("dfGSC1-MAI.json")
dfGSC1.query
dfGSC1.info() # 514 enregistrements.
len(dfGSC1['query'].unique()) #487 mots clés.
#on sauvegarde les données de base de GSC qu'on ajoutera à la fin
dfGSC1Base = pd.DataFrame(columns=['query', 'page', 'position', 'source'])
dfGSC1Base['query'] = dfGSC1['query']
dfGSC1Base['page'] = dfGSC1['page']
dfGSC1Base['position'] = dfGSC1['position']
dfGSC1Base['source'] = "GSC" #source: Google Search Console
#tous les mots clés à récupérer : pas de doublons
myQueries = dfGSC1['query'].unique()
myQueries.size #487 mots clés
Scrap des SERPs dans Google
Comme nous l’avons indiqué précédemment, cette opération peut durer un certain temps car nous sommes obligés de temporiser la lecture des pages de Google pour ne pas nous faire jeter.
###########################################################################
# Pour scraper les SERPs de Google
# on utilise la bibliothèque GoogleSearch de Mario Vilas :
# https://python-googlesearch.readthedocs.io/en/latest/
# Attention : Systeme sans proxies ! Cela peut durer compte
# tenu des pauses.
############################################################################
#dataFrame Scrap des pages de Google
dfScrap = pd.DataFrame(columns=['query', 'page', 'position', 'source'])
len(myQueries)
###############################
i=0
myNum=10
myStart=0
myStop=30
#myTbs= "qdr:m" #recherche sur le dernier mois. pas utilisé.
#tbs=myTbs,
#pause assez importante pour ne pas bloquer affiner les valeurs si besoin
myLowPause=15
myHighPause=45
#on boucle (peut durer plusieurs heures - faites cela pendant la nuit 🙂 !!!)
while i < len(myQueries) :
myQuery = myQueries[i]
print("PASSAGE NUMERO :"+str(i))
print("Query:"+myQuery)
#on fait varier le user_agent et la pause pour ne pas se faire bloquer
myPause = random.randint(myLowPause,myHighPause) #pause assez importante pour ne pas bloquer.
print("Pause:"+str(myPause))
myUserAgent = googlesearch.get_random_user_agent() #modification du user_agent pour ne pas bloquer
print("UserAgent:"+str(myUserAgent))
df = pd.DataFrame(columns=['query', 'page', 'position', 'source']) #dataframe de travail
try :
urls = googlesearch.search(query=myQuery, tld='fr', lang='fr', safe='off',
num=myNum, start=myStart, stop=myStop, domains=None, pause=myPause,
only_standard=False, extra_params={}, tpe='', user_agent=myUserAgent)
for url in urls :
#print("URL:"+url)
df.loc[df.shape[0],'page'] = url
df['query'] = myQuery #fill avec la query courante
df['position'] = df.index.values + 1 #position = index +1
df['source'] = "Scrap" #fill avec origine de la donnée
dfScrap = pd.concat([dfScrap, df], ignore_index=True) #récupère dans l'ensemble des scaps
time.sleep(myPause) #ajoute une pause
i += 1
except :
print("ERRREUR LECTURE GOOGLE")
time.sleep(1200) #ajoute une grande pause si plantage
##############################
dfScrap.info()
dfScrapUnique=dfScrap.drop_duplicates() #on enlève les evéntuels doublons
dfScrapUnique.info()
#Sauvegarde
dfScrapUnique.to_csv("dfScrapUnique.csv", sep=";", encoding='utf-8', index=False) #séparateur ;
dfScrapUnique.to_json("dfScrapUnique.json")
#Relecture ############
dfScrapUnique = pd.read_json("dfScrapUnique.json")
dfScrapUnique.query
dfScrapUnique.info() #13801
dfQPPS = pd.concat([dfScrapUnique, dfGSC1Base], ignore_index=True)
#Sauvegarde
#dfQPPS.to_csv("dfQPPS.csv", sep=";", encoding='utf-8', index=False) #séparateur ;
dfQPPS.to_json("dfQPPS.json")
Créations de variables explicatives
On va enrichir les données que l’on a pour créer de nouvelles variables explicatives pour créer un modèle de Machine Learning. on va créer les mêmes variables que précédemment dans le « modèle interne ».
################################################################################
# On redémarre ici pour l'exploration ML
################################################################################
#########################################################################
# Détermination de variables techniques et construites à partir des
# autres variables
#########################################################################
#Relecture ############
dfQPPS = pd.read_json("dfQPPS.json")
dfQPPS.query
dfQPPS.info() #14315 lignes
#création de la variable à expliquer
#Creation des Groupes
dfQPPS.loc[dfQPPS['position'] <= 10.5, 'group'] = 1
dfQPPS.loc[dfQPPS['position'] > 10.5, 'group'] = 0
#création variables explicatives
#Creation de variables d'url à partir de page
dfQPPS['webSite'] = dfQPPS['page'].apply(lambda x: '{uri.scheme}://{uri.netloc}/'.format(uri=urlparse(x)))
dfQPPS['uriScheme'] = dfQPPS['page'].apply(lambda x: '{uri.scheme}'.format(uri=urlparse(x)))
dfQPPS['uriNetLoc'] = dfQPPS['page'].apply(lambda x: '{uri.netloc}'.format(uri=urlparse(x)))
dfQPPS['uriPath'] = dfQPPS['page'].apply(lambda x: '{uri.path}'.format(uri=urlparse(x)))
#Est-ce que le site est en https ? ici on a plusieurs sites donc peut être intéressant
dfQPPS.loc[dfQPPS['uriScheme']== 'https', 'isHttps'] = 1
dfQPPS.loc[dfQPPS['uriScheme'] != 'https', 'isHttps'] = 0
dfQPPS.info()
#Pseudo niveau dans l'arborescence calculé au nombre de / -2
dfQPPS['level'] = dfQPPS['page'].str[:-1].str.count('/')-2
############################################
#définition du tokeniser pour séparation des mots
tokenizer = nltk.RegexpTokenizer(r'\w+') #définition du tokeniser pour séparation des mots
#on va décompter les mots de la requête dans le nom du site et l'url complète
#on vire les accents
queryNoAccent= dfQPPS['query'].str.normalize('NFKD').str.encode('ascii', errors='ignore').str.decode('utf-8')
#on tokenize la requete sans accents
dfQPPS['tokensQueryNoAccent'] = queryNoAccent.apply(tokenizer.tokenize) #séparation des mots pour la reqête
#Page
dfQPPS['lenPage']=dfQPPS['page'].apply(len) #taille de l'url complète en charactères
dfQPPS['tokensPage'] = dfQPPS['page'].apply(tokenizer.tokenize) #séparation des mots pour l'url entier
dfQPPS['lenTokensPage']=dfQPPS['tokensPage'].apply(len) #longueur de l'url en mots
#mots de la requete dans Page
dfQPPS['lenTokensQueryInPage'] = dfQPPS.apply(lambda x : len(set(x['tokensQueryNoAccent']).intersection(x['tokensPage'])),axis=1)
#total des fréquences des mots dans Page
dfQPPS['lenTokensQueryInPageFrequency'] = dfQPPS.apply(lambda x : x['lenTokensQueryInPage']/x['lenTokensPage'],axis=1)
#SumTFIDF
dfQPPS['sumTFIDFPage'] = getSumTFIDFfromDFColumn(dfQPPS['tokensPage'])
dfQPPS['sumTFIDFPageFrequency'] = dfQPPS.apply(lambda x : x['sumTFIDFPage']/(x['lenTokensPage']+0.01),axis=1)
#WebSite
dfQPPS['lenWebSite']=dfQPPS['webSite'].apply(len) #taille de l'url complète en charactères
dfQPPS['tokensWebSite'] = dfQPPS['webSite'].apply(tokenizer.tokenize) #séparation des mots pour l'url entier
dfQPPS['lenTokensWebSite']=dfQPPS['tokensWebSite'].apply(len) #longueur de l'url en mots
#mots de la requete dans WebSite
dfQPPS['lenTokensQueryInWebSite'] = dfQPPS.apply(lambda x : len(set(x['tokensQueryNoAccent']).intersection(x['tokensWebSite'])),axis=1)
#total des fréquences des mots dans WebSite
dfQPPS['lenTokensQueryInWebSiteFrequency'] = dfQPPS.apply(lambda x : x['lenTokensQueryInWebSite']/x['lenTokensWebSite'],axis=1)
#SumTFIDF
dfQPPS['sumTFIDFWebSite'] = getSumTFIDFfromDFColumn(dfQPPS['tokensWebSite'])
dfQPPS['sumTFIDFWebSiteFrequency'] = dfQPPS.apply(lambda x : x['sumTFIDFWebSite']/(x['lenTokensWebSite']+0.01),axis=1)
#Path
dfQPPS['lenPath']=dfQPPS['uriPath'].apply(len) #taille de l'url complète en charactères
dfQPPS['tokensPath'] = dfQPPS['uriPath'].apply(tokenizer.tokenize) #séparation des mots pour l'url entier
dfQPPS['lenTokensPath']=dfQPPS['tokensPath'].apply(len) #longueur de l'url en mots
#mots de la requete dans Path
dfQPPS['lenTokensQueryInPath'] = dfQPPS.apply(lambda x : len(set(x['tokensQueryNoAccent']).intersection(x['tokensPath'])),axis=1)
#total des fréquences des mots dans Path
#!Risque de division par zero on fait une boucle avec un if
dfQPPS['lenTokensQueryInPathFrequency']=0
for i in range(0, len(dfQPPS)) :
if dfQPPS.loc[i,'lenTokensPath'] > 0 :
dfQPPS.loc[i,'lenTokensQueryInPathFrequency'] =dfQPPS.loc[i,'lenTokensQueryInPath']/dfQPPS.loc[i,'lenTokensPath']
#SumTFIDF
dfQPPS['sumTFIDFPath'] = getSumTFIDFfromDFColumn(dfQPPS['tokensPath'])
dfQPPS['sumTFIDFPathFrequency'] = dfQPPS.apply(lambda x : x['sumTFIDFPath']/(x['lenTokensPath']+0.01),axis=1)
######################################################################
dfQPPS.info()
####sauvegarde sous un autre nom pour cette étape.
#Sauvegarde
dfQPPS.to_json("dfQPPS1-MAI.json")
#on libere de la mémoire
del dfQPPS
gc.collect()
Préparation des données pour le Machine Learning
Comme précédemment : On va préparer les données : déterminer les variables explicatives et la variable à expliquer et splitter le jeu de données en des données d’entrainement et des données de test.
#############################################################################
# Machine Learning - Univers de Concurrence avec variables construite
# sur l'url et les mots clés
#############################################################################
#Relecture ############
dfQPPS1 = pd.read_json("dfQPPS1-MAI.json")
dfQPPS1.query
dfQPPS1.info() # 14315 enregistrements.
#on choisit nos variables explicatives
X = dfQPPS1[['isHttps', 'level',
'lenWebSite', 'lenTokensWebSite', 'lenTokensQueryInWebSiteFrequency' , 'sumTFIDFWebSiteFrequency',
'lenPath', 'lenTokensPath', 'lenTokensQueryInPathFrequency' , 'sumTFIDFPathFrequency']] #variables explicatives
y = dfQPPS1['group'] #variable à expliquer
#on va scaler
scaler = StandardScaler()
scaler.fit(X)
X_Scaled = pd.DataFrame(scaler.transform(X.values), columns=X.columns, index=X.index)
X_Scaled.info()
#on choisit random_state = 42 en hommage à La grande question sur la vie, l'univers et le reste
#dans "Le Guide du voyageur galactique" par Douglas Adams. Ceci afin d'avoir le même split
#tout au long de notre étude.
X_train, X_test, y_train, y_test = train_test_split(X_Scaled,y, random_state=42)
Méthode des K-NN : k plus proches voisins
Pour plus d’explications sur l’algorithme k-NN reportez-vous à l’article précédent.
#Méthode des kNN, recherche du meilleur k
nMax=20
myTrainScore = np.zeros(shape=nMax)
myTestScore = np.zeros(shape=nMax)
#myF1Score = np.zeros(shape=nMax) #abandonné
for n in range(1,nMax) :
knn = KNeighborsClassifier(n_neighbors=n)
knn.fit(X_train, y_train)
myTrainScore[n]=knn.score(X_train,y_train)
print("Training set score: {:.3f}".format(knn.score(X_train,y_train))) #
myTestScore[n]=knn.score(X_test,y_test)
print("Test set score: {:.4f}".format(knn.score(X_test,y_test))) #
#Graphique train score vs test score
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x=np.arange(1,nMax), y=myTrainScore[1:nMax])
sns.lineplot(x=np.arange(1,nMax), y=myTestScore[1:nMax], color='red')
#fig.suptitle("", fontsize=14, fontweight='bold')
ax.set(xlabel='n neighbors', ylabel='Train (bleu) / Test (rouge)',
title="La précision sur les données de test du modèle avec concurrence \n est moins bonne que celle pour 1 seul site. \nNous l'enrichirons avec d'autres variables par la suite.")
fig.text(.3,-.06,"Classification Knn - Univers de Concurrence - Position dans 2 groupes \n vs variables construites en fonction des n voisins",
fontsize=9)
#plt.show()
fig.savefig("QPPS1-KNN-Classifier-2goups.png", bbox_inches="tight", dpi=600)
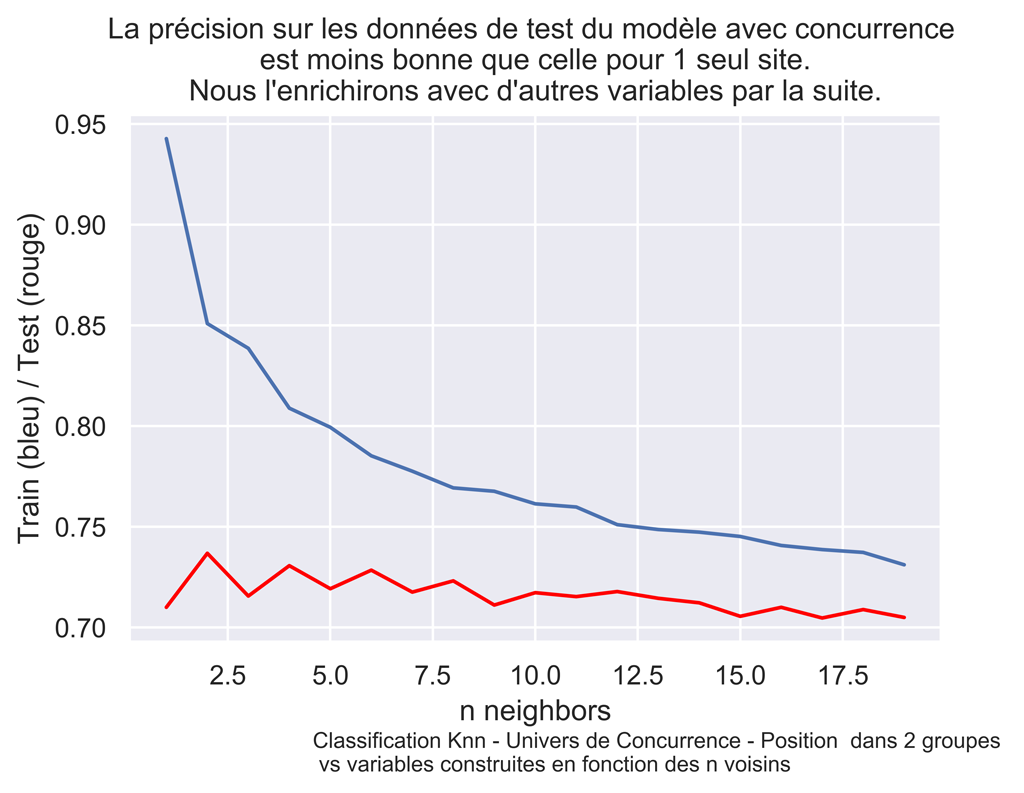
Le meilleur test score (en rouge) est obtenu avec k=2.
#on choist le premier n_neighbor ou myTestScore est le plus grand
#à vérifier toutefois en regardant la courbe.
indices = np.where(myTestScore == np.amax(myTestScore))
n_neighbor = indices[0][0]
n_neighbor
knn = KNeighborsClassifier(n_neighbors=n_neighbor)
knn.fit(X_train, y_train)
print("N neighbor="+str(n_neighbor))
print("Training set score: {:.3f}".format(knn.score(X_train,y_train))) #
print("Test set score: {:.4f}".format(knn.score(X_test,y_test))) #
#myTestScore retenu pour knn - 2 voisins 0.7368 #Précédemment sur le modele interne 0.8837
N neighbor=2
Training set score: 0.851
Test set score: 0.7368
Distribution des pages dans les groupes
#par curiosité regardons la distribution des pages dans les groupes
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.countplot(dfQPPS1['group'] , order=reversed(dfQPPS1['group'].value_counts().index))
fig.suptitle('Les groupes sont plus équilibrés que précédemment.', fontsize=14, fontweight='bold')
ax.set(xlabel='groupe', ylabel='Nombre de Pages',
title="le groupe Top 10 (1) représente la moitié de l'autre groupe.")
fig.text(.2,-.06,"Univers de Concurrence - Distribution des pages/positions dans les 2 groupes.",
fontsize=9)
#plt.show()
fig.savefig("QPPS1-Distribution-2goups.png", bbox_inches="tight", dpi=600)
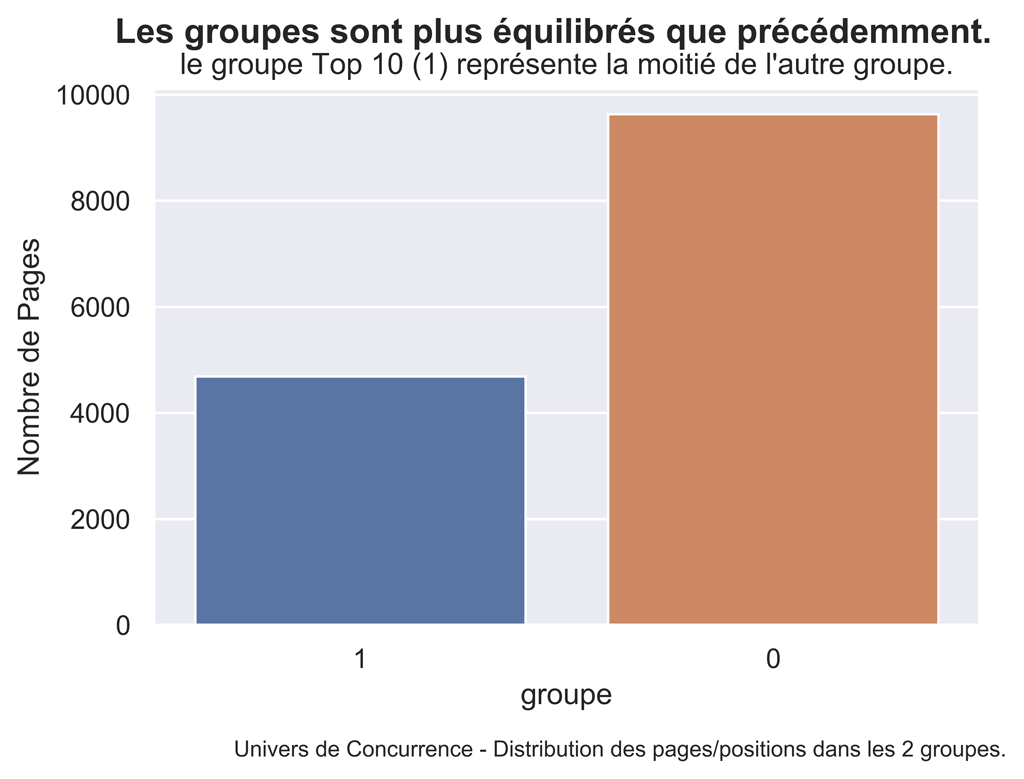
Modèles Linéaires
Comme précédemment, nous allons tester deux modèles linéaires : LogisticRegression et LinearSVC. Pour LogisticRegression nous ferons varier le paramère C.
#Classification linéaire 1 : Régression Logistique
#on faire varier C : nverse of regularization strength; must be a positive float.
#Like in support vector machines, smaller values specify stronger regularization.
#C=1 standard
logreg = LogisticRegression(solver='lbfgs').fit(X_train,y_train)
print("Training set score: {:.3f}".format(logreg.score(X_train,y_train)))
print("Test set score: {:.3f}".format(logreg.score(X_test,y_test)))
#0.693 :le Test Score est moins bon que pour knn (0.7368)
logreg100 = LogisticRegression(C=100, solver='lbfgs').fit(X_train,y_train)
print("Training set score: {:.3f}".format(logreg100.score(X_train,y_train)))
print("Test set score: {:.3f}".format(logreg100.score(X_test,y_test)))
#pareil 0.693< knn (0.7368)
logreg1000 = LogisticRegression(C=1000, solver='lbfgs').fit(X_train,y_train)
print("Training set score: {:.3f}".format(logreg1000.score(X_train,y_train)))
print("Test set score: {:.3f}".format(logreg1000.score(X_test,y_test)))
#pareil 0.693< knn (0.7368)
logreg001 = LogisticRegression(C=0.01, solver='lbfgs').fit(X_train,y_train)
print("Training set score: {:.3f}".format(logreg001.score(X_train,y_train)))
print("Test set score: {:.3f}".format(logreg001.score(X_test,y_test)))
#moins bien 0.692 < knn (0.7368)
#Classification linéaire 2 : machine à vecteurs supports linéaire (linear SVC).
LinSVC = LinearSVC(max_iter=10000).fit(X_train,y_train)
print("Training set score: {:.3f}".format(LinSVC.score(X_train,y_train)))
print("Test set score: {:.3f}".format(LinSVC.score(X_test,y_test)))
#pareil 0.693< knn (0.7368)
Le meilleur test score est de 0.693, ce qui est assez décevant. Il faudra enrichir les données et trouver de nouvelles variables explicatives pour avoir un modèle plus pertinent.
Importance des variables.
Même si le Test Score est faible, regardons l'importance des variables pour la régression logistique avec C=1.
#######################################################################
# Affichage de l'importance des variables pour logreg
#######################################################################
signed_feature_importance = logreg.coef_[0] #pour afficher le sens
feature_importance = abs(logreg.coef_[0]) #pous classer par importance
#feature_importance = 100.0 * (feature_importance / feature_importance.max())
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + .5
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
ax.barh(pos, signed_feature_importance[sorted_idx], align='center')
ax.set_yticks(pos)
ax.set_yticklabels(np.array(X.columns)[sorted_idx], fontsize=8)
fig.suptitle("Le fait que le nom de domaine soit dans la thématique (TFIDF).\n et qu'il comporte des mots clés de la requête semblent être des facteurs importants. \n La longueur en caractères du nom de domaine importe peu ici.", fontsize=10)
ax.set(xlabel='Importance Relative des variables')
fig.text(.3,-.06,"Régression Logistique - Univers de concurrence \n Importance des variables",
fontsize=9)
fig.savefig("QPPS1-Importance-Variables-2goups.png", bbox_inches="tight", dpi=600)
##############################################################
##########################################################################
# MERCI pour votre attention !
##########################################################################
#on reste dans l'IDE
#if __name__ == '__main__':
# main()
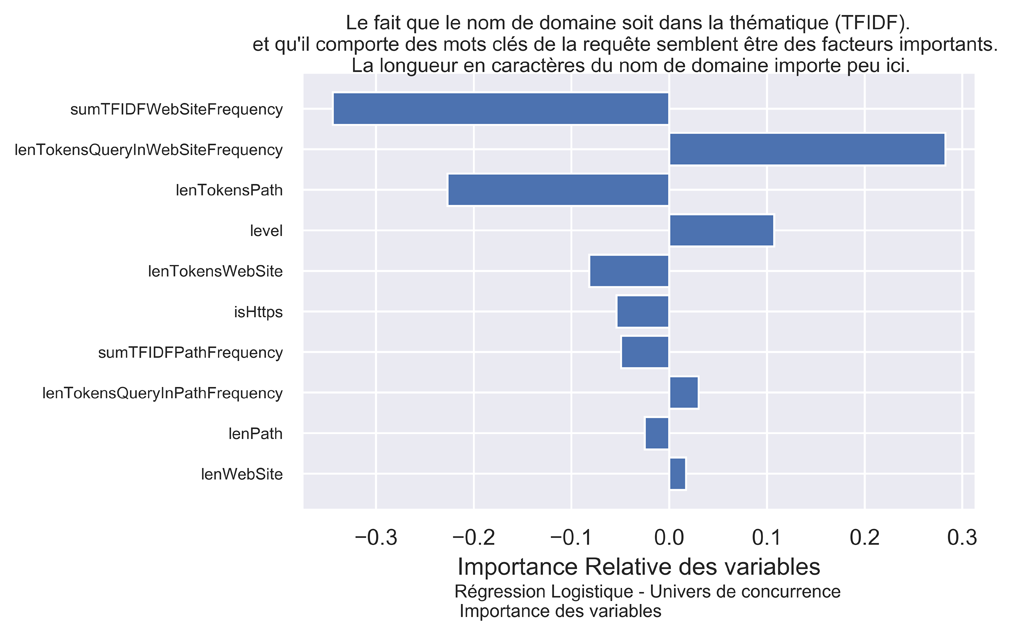
Comme on l'a vu, les modèles linéaires ne sont pas très efficaces ici. Il conviendra dans un prochain article de déterminer de nouvelles variables explicatives.
A bientôt,
Pierre