


Partager la publication "Analyse en Composantes Principales sur les canaux de trafic Web avec R"
Cet article est le dernier d’une série sur l’analyse des données Google Analytics de l’association Networking Morbihan avec R.
Dans cet article, nous allons réaliser une Analyse en Composantes Principales sur la variable canal de trafic.
A quoi sert une Analyse en Composantes Principales ?
Une Analyse en Composantes Principale – ACP – ou en Anglais PCA (Principal Component Analysis) est une méthode d’analyse de données qui permet d’explorer les liaisons entre les variables (pour nous ici les canaux : direct, referral, search, social, webmail) et les ressemblances entre individus (pour nous les pages Web : nous en avons 1262 différentes) .
L’ACP nous donne les informations suivantes que l’on va pouvoir visualiser :
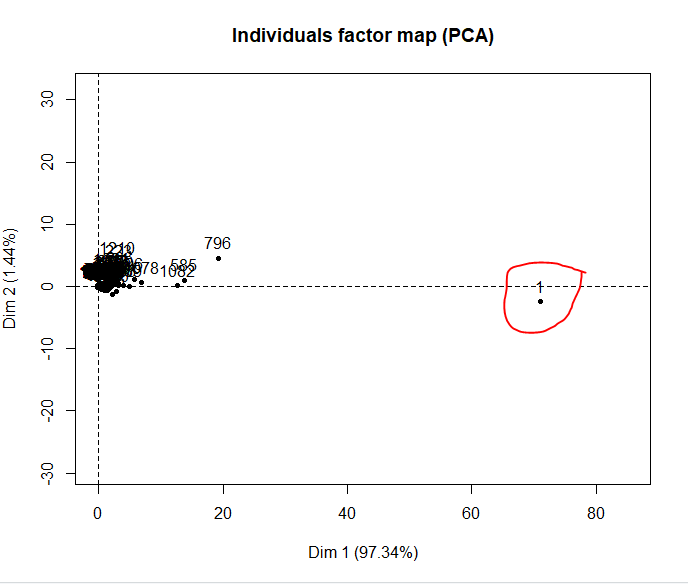
- Visualisation des individus : notion de distances entre individus, identification de groupes.
- Visualisation des variables : en fonction de leurs corrélations. (ici notre cas)


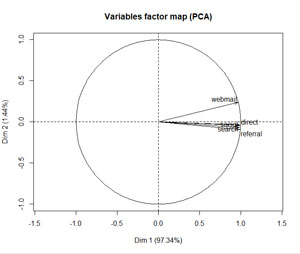
Mathématiquement cela consiste à transformer des variables liées entre elles (dites « corrélées ») en nouvelles variables décorrélées les unes des autres.
Ces nouvelles variables sont nommées « composantes principales », ou axes principaux.
Cela permet notamment de réduire le nombre de variables et de rendre l’information plus lisible si l’on a un jeu de données important avec de nombreuses variables.
l’ACP peut servir aussi à la vérification d’un jeu de données en identifiant les valeurs aberrantes (voir graphique ci-dessous) ou d’étape préalable à d’autres traitements statistiques que nous n’aborderons pas ici.
Procédure à suivre :
Logiciel R :
Téléchargez le Logiciel R sur le site du CRAN https://cran.r-project.org/, ainsi que l’environnement de développement RStudio ici : https://www.rstudio.com/products/rstudio/download/.
Jeu de données
Comme dans les précédents articles, nous utiliserons le jeu de données de Networking Morbihan pour illustrer notre propos. Vous aurez besoin de 3 fichiers à dézipper dans le même répertoire que le code R :
Vous pouvez aussi construire votre jeu de données à partir de vos propres données Google Analytics. Auquel cas, suivez les procédures que nous avions décrites dans des articles précédents :
- googleanalyticsR : importation de vos données Google Analytics dans R
- Nettoyage du Spam dans Google Analytics avec R – Partie I
- Nettoyage du Spam dans Google Analytics avec R – Partie II
- Détection du trafic Web significatif avec R et AnomalyDetection
- Le Marketing de contenu amène-t-il du trafic sur mon site Web ? Logiciel R
- Quelle est la durée de vie de mes articles sur mon site ?
- Analyse du trafic selon les canaux avec R
Code Source :
Vous pouvez récupérer les différents morceaux de code ci-dessous ou récupérer tout le code gratuitement dans notre boutique : https://www.anakeyn.com/boutique/produit/scipt-r-acp-canaux-web/
Chargement des bibliothèques utiles
##########################################################################
# Auteur : Pierre Rouarch 2019 - Licence GPL 3
# PCATrafficChannelsR
# Analyse en Composantes principales canaux trafic Web.
# Pour illustrer notre propos nous utiliserons le jeu de données de
# l'association Networking-Morbihan
##########################################################################
#Packages et bibliothèques utiles (décommenter au besoin)
##########################################################################
#install.packages("lubridate") #si vous ne l'avez pas
#install.packages("tseries")
#install.packages("devtools")
#devtools::install_github("twitter/AnomalyDetection") #pour anomalyDetection de Twitter
#devtools::install_github('sinhrks/ggfortify') #pour ggfortify
#install.packages("XML")
#install.packages("stringi")
#install.packages("BSDA")
#install.packages("BBmisc")
#install.packages("stringi")
#install.packages("FactoMineR")
#install.packages("factoextra")
#install.packages("rcorr")
#install.packages("lubridate") #si vous ne l'avez pas
library (lubridate) #pour yday
#library(tseries) #pour ts
library(AnomalyDetection) #pour anomalydetectionVec
#library(XML) # pour xmlParse
#library(stringi) #pour stri_replace_all_fixed(x, " ", "")
library(BSDA) #pour SIGN.test
library(BBmisc) #pour which.first
#install.packages("stringi")
library(stringi) #pour stri_detect
library(ggfortify) #pour ploter autoplot type ggplot
#install.packages("tidyverse") #si vous ne l'avez pas #pour gggplot2, dplyr, tidyr, readr, purr, tibble, stringr, forcats
#install.packages("forecast") #pour ma
#Chargement des bibliothèques utiles
library(tidyverse) #pour gggplot2, dplyr, tidyr, readr, purr, tibble, stringr, forcats
library(forecast) #pour arima, ma, tsclean
library(FactoMineR) #pour ACP
library(factoextra) #compléments ACP FactoMineR
Récupération des fichiers dfPageViews.csv, myArticles.csv et mySourcesChannel.csv
##########################################################################
# Récupération des fichiers
##########################################################################
dfPageViews <- read.csv("dfPageViews.csv", header=TRUE, sep=";")
#str(dfPageViews) #verif
#transformation de la date en date 🙂
dfPageViews$date <- as.Date(dfPageViews$date,format="%Y-%m-%d")
#str(dfPageViews) #verif
str(dfPageViews) #72821 obs
dfPageViews$index <- 1:nrow(dfPageViews) #création d'un pour retrouver les "articles marketing"
#ensuite
#pour les articles
myArticles <- read.csv("myArticles.csv", header=TRUE, sep=";")
#transformation de la date en date 🙂
myArticles$date <- as.Date(myArticles$date,format="%Y-%m-%d")
str(myArticles) #verif
#recuperer le fichier avec les channels
mySourcesChannel <- read.csv2("mySourcesChannel.csv", header=TRUE)
str(mySourcesChannel) #voyons ce que l'on récupère
#pour effectuer le left join besoin d'une chaine de caractère.
mySourcesChannel$source <- as.character(mySourcesChannel$source)
Données Globales :
Préparation des données et calcul de l’ACP.
##########################################################################
# Pour le traffic Global on ajoute les canaux
##########################################################################
#recuperation de la variable channel dans le dataframe
#principal par un left join.
dfPVChannel <- left_join(dfPageViews, mySourcesChannel, by="source")
#verifs
str(dfPVChannel) #72821
head(dfPVChannel)
plyr::count(as.factor(dfPVChannel$channel)) #5 canaux
plyr::count(as.factor(dfPVChannel$pagePath)) #1262 types de pages
#Préparationd des données pour l'ACP
PVDataForACP <- dfPVChannel[, c("pagePath", "channel")] %>% #on ne garde que PagePath et channel
group_by(pagePath, channel) %>% #groupement par cleanLandingPagePath et channel
mutate(pageviews = n()) %>% #on décompte les pages vues
unique() %>% #découblonnement
spread(key=channel, value=pageviews, fill = 0, convert = FALSE, drop = TRUE,
sep = NULL) #eclatement du facteur channel en variables
#Calcul de l'ACP avec FactoMineR
res.pca = PCA(PVDataForACP[, -1], scale.unit=TRUE, ncp=5, graph=F)
summary(res.pca) #resumé des données
#############################Plots Simples individus et variables.
#plot(res.pca, choix = "ind") #individus
#plot(res.pca, choix = "var") #variables
Screeplot pour toutes les pages.
Il s’agit du graphique permettant de visualiser le pourcentage de variance expliquée en fonction des dimensions.
######################### ScreePlot ################################################
ScreePlot <- fviz_eig(res.pca, addlabels = TRUE, ylim = c(0, 100))
ggpubr::ggpar(ScreePlot,
title = "ScreePlot - Toutes les Pages vues",
subtitle = "Pratiquement toute l'information est contenue dans la première composante",
xlab = "Dimensions",
ylab = "Pourcentage de variance expliquée",
caption = "ScreePlot pour toutes les Pages Vues")
ggsave(filename = "PV-ScreePlot.jpg", dpi="print") #sauvegarde du graphique
######################### ScreePlot ################################################
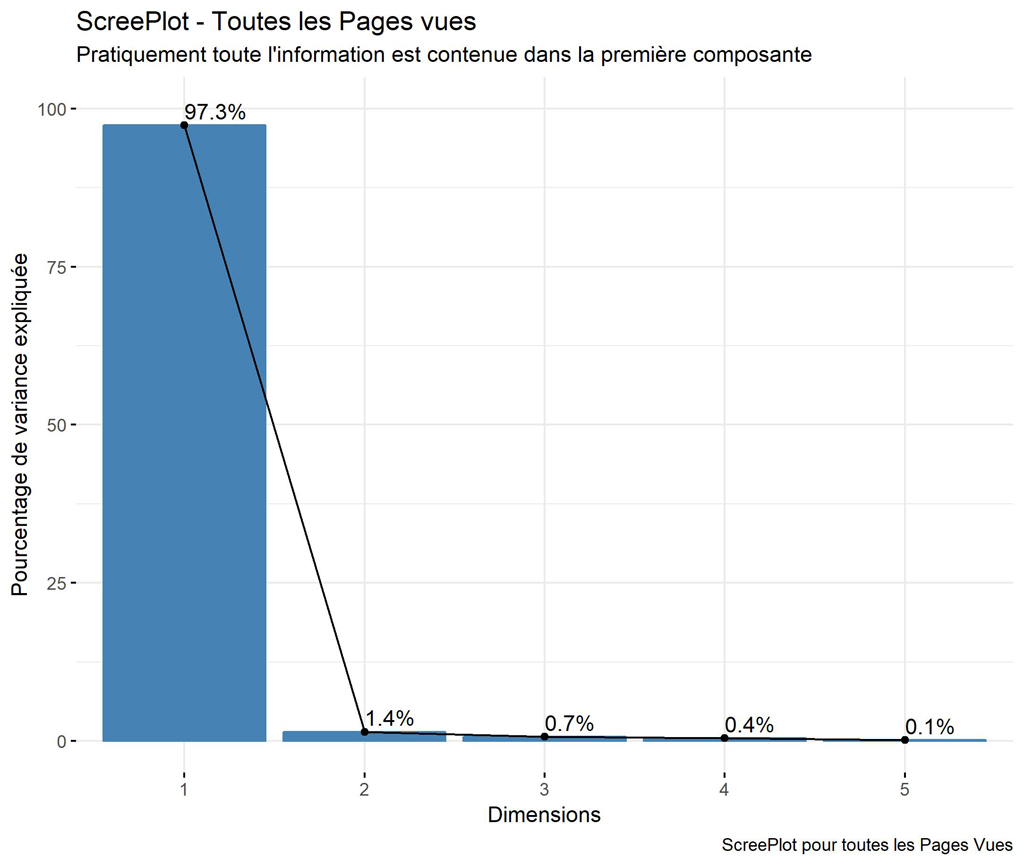
Diagramme des variables pour toutes les pages :
######################### Diagramme des variables ################################################
# Colorer en fonction du cos2: qualité de représentation
VarPlot <- fviz_pca_var(res.pca, col.var = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE # Évite le chevauchement de texte
)
ggpubr::ggpar(VarPlot,
title = "ACP - VarPlot - Toutes les Pages vues",
subtitle = "Les variables sont quasiment toutes sur la première dimension \n webmail diffère légèrement",
caption = "Diagramme des variables pour toutes les pages vues")
ggsave(filename = "PV-VarPlot.jpg", dpi="print") #sauvegarde du graphique
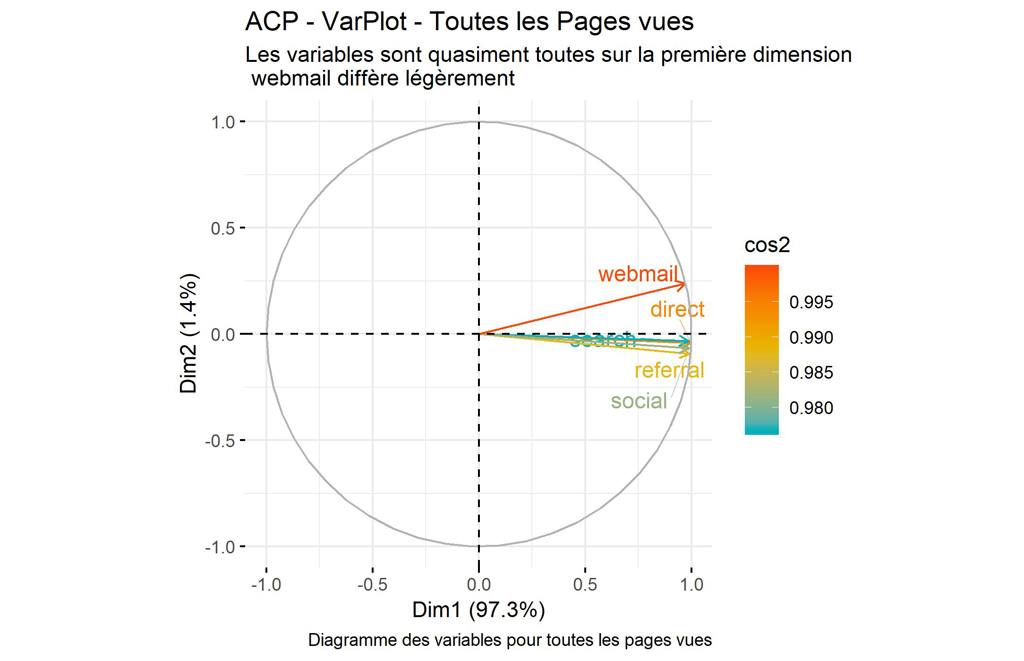
Mis à part Webmail qui diffère légèrement, tous les autres canaux sont pratiquement tous sur l’axe de la composante 1. Cela montre qu’ils sont fortement et positivement corrélés.
Le fait que Webmail diffère pourrait indiquer que certaines pages bénéficient de plus de trafic via email que d’autres. Ce qui est la réalité.
Le cos² indique la qualité de représentation des variables sur le graphique de l’ACP. Il est calculé comme étant les coordonnées au carré: var.cos2 = var.coord * var.coord. Ici toutes les variables sont très bien représentées : > 0,99.
Trafic de base
Création du jeu de données pour le Trafic de BAse et calcul de l’ACP
##########################################################################
# Pour le traffic de base
##########################################################################
#Recréation du trafic de base
#récupere les chemins des pages pour les comparer dans dfPageViews
myArticles$pagePath <- str_split_fixed(myArticles$link, "https://www.networking-morbihan.com", 2)[,2]
patternArticlesToRemove <- unique(myArticles$pagePath)
#Pour les pages de base on enleve les pagePath de nos articles
indexPagePathToRemove <- -grep(pattern = paste(patternArticlesToRemove, collapse="|"), dfPageViews$pagePath)
dfBasePageViews <- dfPageViews[indexPagePathToRemove,]
#puis on enleve les landingPagePath de nos articles
indexLandingPagePathToRemove <- -grep(pattern = paste(patternArticlesToRemove, collapse="|"), dfBasePageViews$landingPagePath)
dfBasePageViews <- dfBasePageViews[indexLandingPagePathToRemove,]
str(dfBasePageViews) #37614 obs.
#recuperation de la variable channel dans la dataframe principale par un left join.
dfBasePVChannel <- left_join(dfBasePageViews, mySourcesChannel, by="source")
#verifs
str(dfBasePVChannel)
head(dfBasePVChannel)
plyr::count(as.factor(dfBasePVChannel$channel))
#préparation des données pour l'ACP
BasePVDataForACP <- dfBasePVChannel[, c("pagePath", "channel")] %>% #on ne garde que PagePath et channel
group_by(pagePath, channel) %>% #groupement par cleanLandingPagePath et channel
mutate(pageviews = n()) %>% #on décompte les pages vues
unique() %>% #découblonnement
spread(key=channel, value=pageviews, fill = 0, convert = FALSE, drop = TRUE,
sep = NULL) #eclatement du facteur channel en variables
#Calcul de la
res.pca = PCA(BasePVDataForACP[, -1], scale.unit=TRUE, ncp=5, graph=F)
summary(res.pca) #resumé des données
Graphique de pourcentage de variance expliquee pour le trafic de base
######################### ScreePlot ################################################
ScreePlot <- fviz_eig(res.pca, addlabels = TRUE, ylim = c(0, 100))
ggpubr::ggpar(ScreePlot,
title = "ScreePlot - Pages de Base",
subtitle = "L'information est encore plus concentrée dans la première composante",
xlab = "Dimensions",
ylab = "Pourcentage de variance expliquée",
caption = "ScreePlot pour Les pages de Base")
ggsave(filename = "Base-PV-ScreePlot.jpg", dpi="print") #sauvegarde du graphique
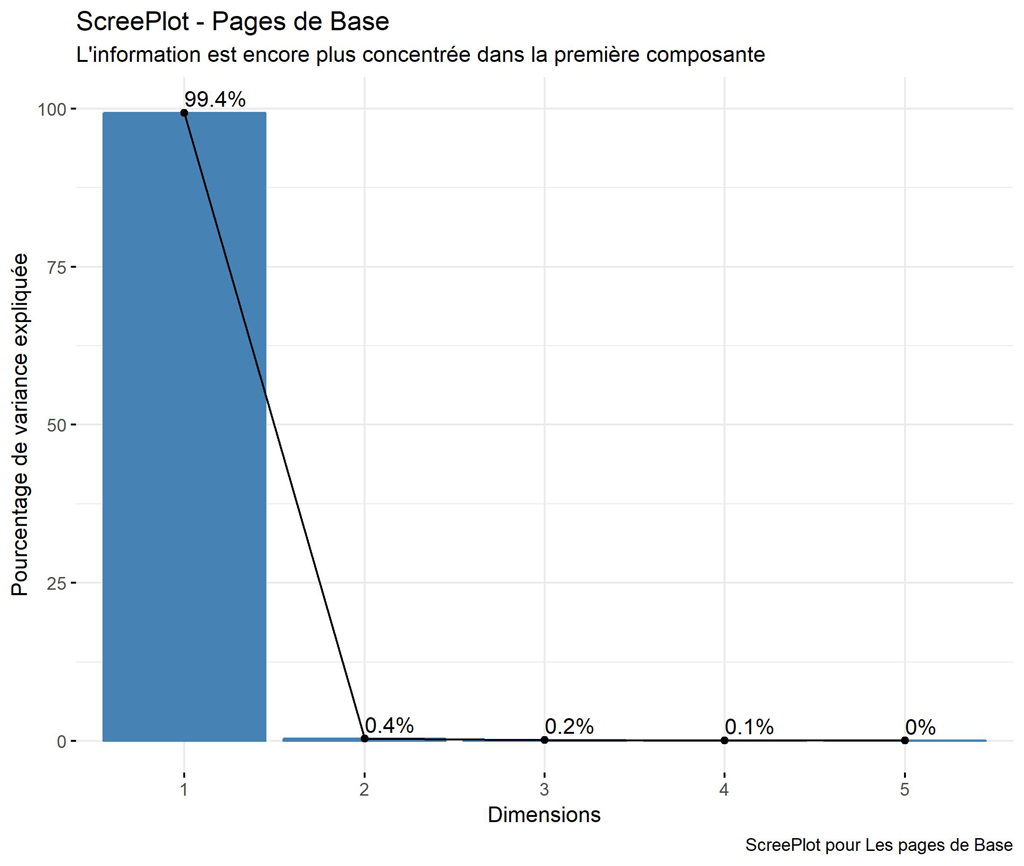
Diagramme des variables pour les pages de base
######################### Diagramme des variables ################################################
# Colorer en fonction du cos2: qualité de représentation
VarPlot <- fviz_pca_var(res.pca, col.var = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE # Évite le chevauchement de texte
)
ggpubr::ggpar(VarPlot,
title = "ACP - VarPlot - Pages de Base",
subtitle = "Les variables sont quasiment toutes sur la première dimension \n webmail s'est même rapprochée de l'axe.",
caption = "Diagramme des variables pour les pages de bases")
ggsave(filename = "Base-PV-VarPlot.jpg", dpi="print") #sauvegarde du graphique
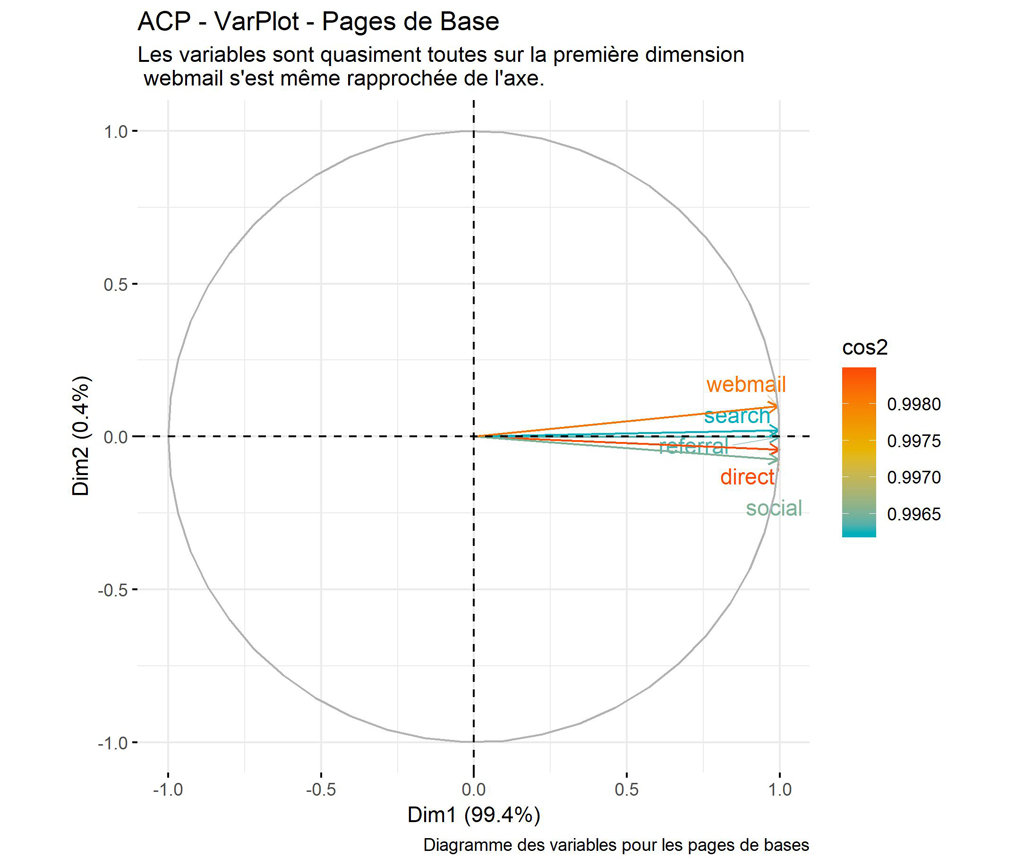
Toutes les sources de trafic sont fortement liées pour les pages de base.
Pages Direct Marketing
Preparation des donnees pour les pages direct marketing et calcul de l’aCP
##########################################################################
#regardons pour le trafic Direct Marketing uniquement i.e le traffic dont
# la source a dirigé vers une page Articles Marketing
##########################################################################
#Construction du trafic Direct Marketing
#on garde uniquement les landingPagePath de nos articles :
#DM = Direct Marketing
patternArticlesToKeep <- unique(myArticles$pagePath)
indexLandingPagePathToKeep <- grep(pattern = paste(patternArticlesToKeep, collapse="|"), dfPageViews$landingPagePath)
dfDMPageViews <- dfPageViews[indexLandingPagePathToKeep,]
str(dfDMPageViews) #28553 obs.
dfDMPVChannel <- left_join(dfDMPageViews, mySourcesChannel, by="source")
str(dfDMPVChannel)
#recuperation de la variable channel dans la dataframe principale par un left join.
dfDMPVChannel <- left_join(dfDMPageViews, mySourcesChannel, by="source")
#verifs
str(dfDMPVChannel)
head(dfDMPVChannel)
plyr::count(as.factor(dfDMPVChannel$channel))
DMPVPVDataForACP <- dfDMPVChannel[, c("pagePath", "channel")] %>% #on ne garde que PagePath et channel
group_by(pagePath, channel) %>% #groupement par cleanLandingPagePath et channel
mutate(pageviews = n()) %>% #on décompte les pages vues
unique() %>% #découblonnement
spread(key=channel, value=pageviews, fill = 0, convert = FALSE, drop = TRUE,
sep = NULL) #eclatement du facteur channel en variables
res.pca = PCA(DMPVPVDataForACP[, -1], scale.unit=TRUE, ncp=5, graph=F)
summary(res.pca) #resumé des données
Graphique de pourcentage de variance expliquee pour le trafic DIRECT MARKETING
######################### ScreePlot ################################################
ScreePlot <- fviz_eig(res.pca, addlabels = TRUE, ylim = c(0, 100))
ggpubr::ggpar(ScreePlot,
title = "ScreePlot - Pages Direct Marketing",
subtitle = "Cette fois l'information est moins concentrée dans la première composante \n mais cela reste important",
xlab = "Dimensions",
ylab = "Pourcentage de variance expliquée",
caption = "ScreePlot pour Les pages Direct Marketing")
ggsave(filename = "DM-PV-ScreePlot.jpg", dpi="print") #sauvegarde du graphique
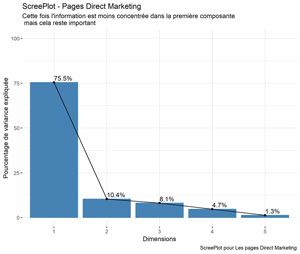
Diagramme des variables pour les pages DIRECT MARKETING
######################## Diagramme des variables ################################################
# Colorer en fonction du cos2: qualité de représentation
VarPlot <- fviz_pca_var(res.pca, col.var = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE # Évite le chevauchement de texte
)
ggpubr::ggpar(VarPlot,
title = "ACP - VarPlot - Pages Direct MArketing",
subtitle = "Cette fois le search se détache des autres variables. Ces dernières \ncorrespondent plus aux actions Marketing ponctuelles.",
caption = "Diagramme des variables pour les pages Direct Marketing")
ggsave(filename = "DM-PV-VarPlot.jpg", dpi="print") #sauvegarde du graphique
##########################################################################
# MERCI pour votre attention !
##########################################################################
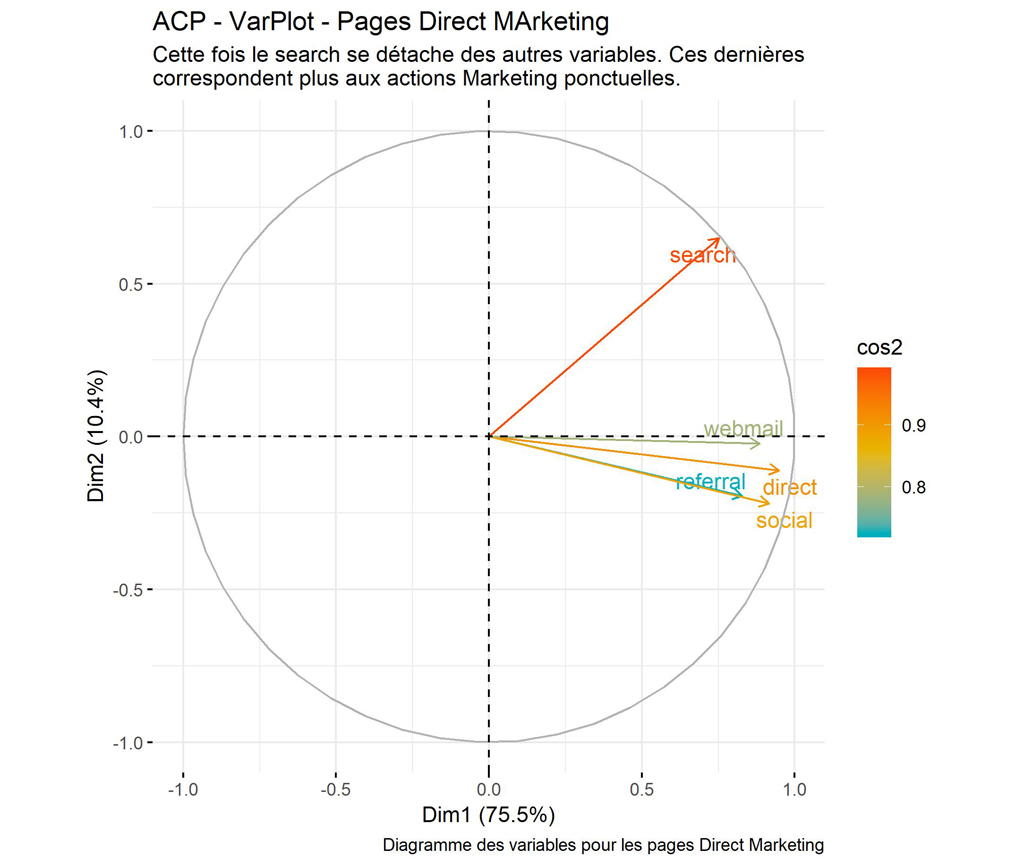
Le fait que search se détache pourrait indiquer que certaines pages on un trafic search différencié par rapport aux autres.
Et vous, qu’obtenez-vous avec les données de votre site ?
A bientôt,
Pierre