

Partager la publication "Analyse du trafic selon les canaux avec R"
Dans cet article nous allons investiguer la typologie des sources de trafic ou canaux et nous allons aussi comparer ces sources selon le type de pages : « pages de base » et « pages marketing ».
Pour notre étude, il serait intéressant de dissocier les
différents canaux de trafic :
- le trafic suite à un email : email,
- le trafic via un site quelconque : referral,
- le trafic via les réseaux sociaux : social,
- le trafic via des moteurs de recherche : search.
Pour voir leurs différentes contributions dans le temps.
Malheureusement, comme on le verra plus loin, ces informations sont difficiles à obtenir. Nous verrons comment faire pour avoir une information, à peu près pertinente.
Comment procéder ?
Logiciel R :
Téléchargez le Logiciel R sur le site du CRAN https://cran.r-project.org/, ainsi que l’environnement de développement RStudio ici : https://www.rstudio.com/products/rstudio/download/.
Jeu de données
Comme dans les précédents articles, nous utiliserons le jeu de données de Networking Morbihan pour illustrer notre propos : Soit : les données de trafic récupérées de Google Analytics et nettoyées et la liste des « articles marketing » .
Vous pouvez aussi construire votre jeu de données à partir de vos propres données Google Analytics. Auquel cas, vous devrez suivre les procédures que nous avions décrites dans des articles précédents :
- googleanalyticsR : importation de vos données Google Analytics dans R
- Nettoyage du Spam dans Google Analytics avec R – Partie I
- Nettoyage du Spam dans Google Analytics avec R – Partie II
- Détection du trafic Web significatif avec R et AnomalyDetection
- Le Marketing de contenu amène-t-il du trafic sur mon site Web ? Logiciel R
Reportez-vous aussi à cet article sur la durée de vie des articles sur un site Web pour voir les concepts d’Articles Marketing, Direct Marketing et Unique Marketing.
Code Source :
Vous pouvez récupérer les différents bouts de code ci-dessous ou récupérer gratuitement tout le code dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-r-trafic-par-canaux/ .
Chargement des bibliothèques et récupération des données :
On procède comme précédemment :
##########################################################################
# Auteur : Pierre Rouarch 2019 - Licence GPL 3
# TrafficChannelsR
# Typologie du trafic - Canaux.
# Pour illustrer notre propos nous utiliserons le jeu de données de
# l'association Networking-Morbihan
##########################################################################
#Packages et bibliothèques utiles (décommenter au besoin)
##########################################################################
#install.packages("lubridate") #si vous ne l'avez pas
#install.packages("tseries")
#install.packages("devtools")
#devtools::install_github("twitter/AnomalyDetection") #pour anomalyDetection de Twitter
#install.packages("XML")
#install.packages("stringi")
#install.packages("BSDA")
#install.packages("BBmisc")
#install.packages("stringi")
#install.packages("FactoMineR")
#install.packages("factoextra")
#install.packages("rcorr")
#install.packages("lubridate") #si vous ne l'avez pas
library (lubridate) #pour yday
#library(tseries) #pour ts
library(AnomalyDetection) #pour anomalydetectionVec
#library(XML) # pour xmlParse
#library(stringi) #pour stri_replace_all_fixed(x, " ", "")
library(BSDA) #pour SIGN.test
library(BBmisc) #pour which.first
#install.packages("stringi")
library(stringi) #pour stri_detect
#library(ggfortify) #pour ploter autoplot type ggplot
#install.packages("tidyverse") #si vous ne l'avez pas #pour gggplot2, dplyr, tidyr, readr, purr, tibble, stringr, forcats
#install.packages("forecast") #pour ma
#Chargement des bibliothèques utiles
library(tidyverse) #pour gggplot2, dplyr, tidyr, readr, purr, tibble, stringr, forcats
library(forecast) #pour arima, ma, tsclean
##########################################################################
# Récupération du Jeu de données nettoyé des pages et des articles
##########################################################################
dfPageViews <- read.csv("dfPageViews.csv", header=TRUE, sep=";")
#str(dfPageViews) #verif
#transformation de la date en date 🙂
dfPageViews$date <- as.Date(dfPageViews$date,format="%Y-%m-%d")
#str(dfPageViews) #verif
str(dfPageViews) #72821 obs
dfPageViews$index <- 1:nrow(dfPageViews) #création d'un pour retrouver les "articles marketing"
#ensuite
#pour les articles
myArticles <- read.csv("myArticles.csv", header=TRUE, sep=";")
#transformation de la date en date 🙂
myArticles$date <- as.Date(myArticles$date,format="%Y-%m-%d")
str(myArticles) #verif
Identification des canaux via la variable Medium
Celle-ci devrait permettre de différencier le trafic en provenance des moteurs de recherche, des réseaux sociaux, des webmails et d’autres sites référents.
############################################################ # Typologie du trafic entrant avec la variable medium ############################################################ #Revenons au Dataframe des pages vues dfPageViews str(dfPageViews) #regardons ce que l'on a dans la variable medium. plyr::count(as.factor(dfPageViews$medium)) #La variable medium ne nous donne pas une information fiable.
On obtient mes résultats suivants
x freq 1 (none) 21913 2 (not set) 2 3 facebook 15 4 organic 29678 5 referral 19994 6 sortir-en-bretagne 4 7 twitter 1215
Les données ne sont pas très fiables, on a un gros paquet (none) qui correspond au trafic « direct » :
Google Analytics ne sait pas classer de nombreuses sources qu’il considère comme directes – c’est-à-dire que l’internaute a tapé directement l’URL du site dans la barre d’adresse – mais qui peuvent en fait provenir d’autres sources comme par exemple :
- les favoris ou bookmarks choisis par l’internaute,
- les favoris ou bookmarks automatiques, par exemple les « sites les plus couramment visités » lors de l’ouverture d’un nouvel onglet dans les navigateurs récents,
- les liens dans des e-mails ouverts dans un logiciel d’emails classique comme OutLook ou Thunderbird (pas un webmail),
- les liens depuis une campagne de liens sponsorisés mal traquée,
- les liens dans un document (.doc, .xls, .pdf, etc.),
- les liens dans un SMS,
- les liens dans un outil de messagerie instantanée (Skype, Google Hangouts,..),
- les liens passant de page en https vers une page en http ou inversement ou en navigation privée via son navigateur,
- les liens depuis une application pour smartphones et tablettes,
- …
On devra donc se contenter de cette imprécision à ce niveau.
Identification des canaux via la variable Source
Investiguons la variable « source » :
############################################################ # Typologie du trafic entrant avec la variable source #regardons les différentes sources (mySources <- plyr::count(as.factor(dfPageViews$source))) names(mySources)[1]<- "source" str(mySources) head(mySources[order(-mySources$freq),], n=20) #Affichage des 20 prelières sources
Il y a 311 sources différentes. Voici les plus fréquentes
source freq 115 google 28089 1 (direct) 21913 90 facebook.com 3315 264 viadeo.com 2507 123 google.fr 1714 258 twitterfeed 1232 210 quaidesreseaux56.fr 882 136 images.google.fr 853 148 l.facebook.com 786 164 m.facebook.com 712 33 bing 690 245 t.co 652 69 designsgenius.com 517 159 linkis.com 511 162 localhost 505 158 linkedin.com 482 134 images.google 452 16 aleos2i.fr 443 111 fr.viadeo.com 374 303 yahoo 279
On retrouve nos « (none) » en « (direct) ».
On va regrouper les canaux « à la main » et les récupérer dans le fichier mySourcesChannel.csv.
#Sauvegarde pour travailler à la main le type de sources.
write.csv2(mySources, file = "mySources.csv", row.names=FALSE)
#.... traitement manuel externe ....
#recuperer le fichier avec les channels
mySourcesChannel <- read.csv2("mySourcesChannel.csv", header=TRUE)
str(mySourcesChannel) #voyons ce que l'on récupère
#pour effectuer le left join besoin d'une chaine de caractère.
mySourcesChannel$source <- as.character(mySourcesChannel$source)
Analyse du trafic Global
On va traiter les données concernant le trafic Global :
##########################################################################
# Pour le traffic Global
##########################################################################
#recuperation de la variable channel dans le dataframe
#principal par un left join.
dfPVChannel <- left_join(dfPageViews, mySourcesChannel, by="source")
#verifs
str(dfPVChannel)
head(dfPVChannel)
(myChannels <- plyr::count(as.factor(dfPVChannel$channel)))
plot(myChannels) #plot rapide
#creation de la dataframe dateChannel_data par jour et canal
dateChannel_data <- dfPVChannel[,c("date", "channel")] %>% #dateChannel_data à partir de dfPVChannel
group_by(date, channel) %>% #groupement par date et channel
mutate(pageViews = n()) %>% #total des pageviews = nombre d'observations / date /channel
as.data.frame() %>% #sur d'avoir une data.frame
mutate(year = format(date,"%Y")) #creation de la variable year
str(dateChannel_data)
head(dateChannel_data)
#View(dateChannel_data)
Graphique en Barre sur toute la PEriode
##########################################################################
# Graphique en barre général Répartition du trafic selon les canaux.
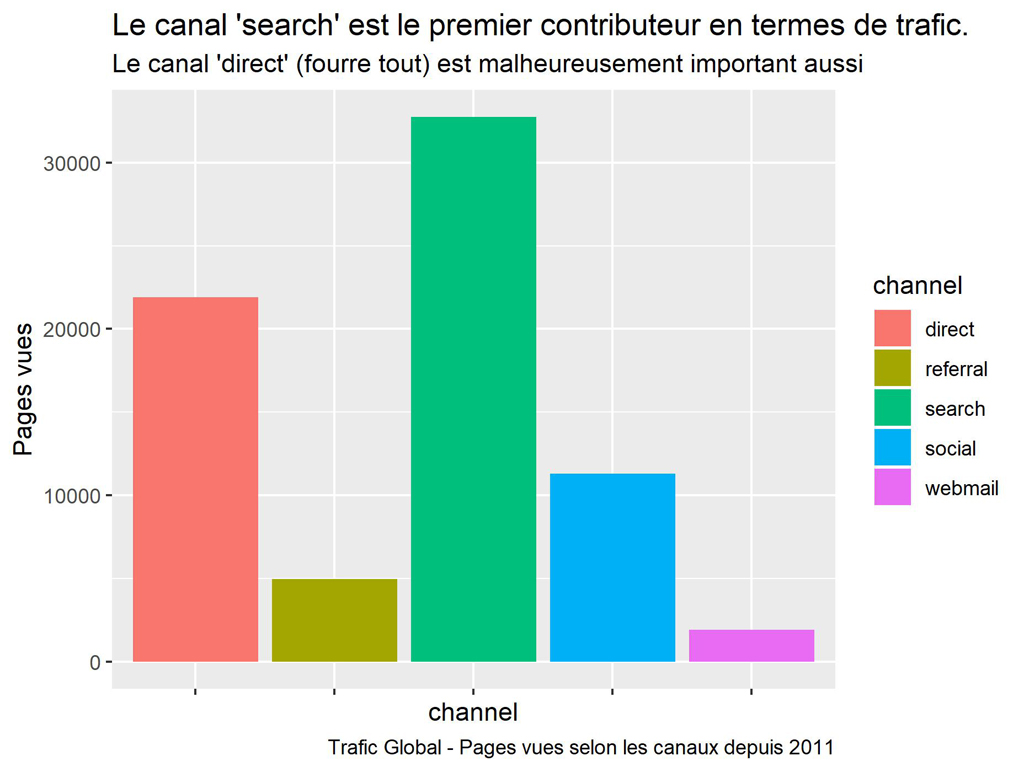
ggplot() +
geom_bar(data=dateChannel_data, aes(x=channel, fill=channel)) +
theme(axis.text.x = element_blank()) +
ylab("Pages vues") +
labs(title = "Le canal 'search' est le premier contributeur en termes de trafic.",
subtitle = "Le canal 'direct' (fourre tout) est malheureusement important aussi",
caption = "Trafic Global - Pages vues selon les canaux depuis 2011")
ggsave(filename = "PV-Channel-bar.jpg", dpi="print")
Graphique en barre par ANNEES
#Graphique en barre par années
#Répartition du trafic selon les sources.
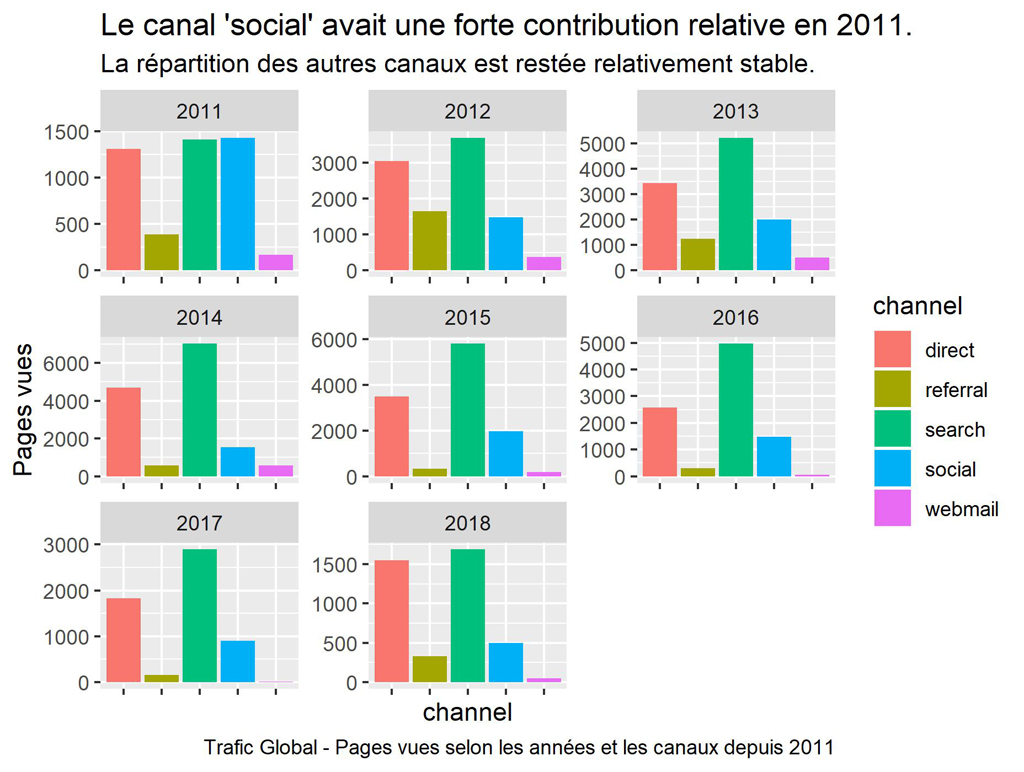
ggplot() +
geom_bar(data=dateChannel_data, aes(x=channel, fill=channel)) +
facet_wrap(~year, scales="free") +
theme(axis.text.x = element_blank()) +
ylab("Pages vues") +
labs(title = "Le canal 'social' avait une forte contribution relative en 2011.",
subtitle = "La répartition des autres canaux est restée relativement stable.",
caption = "Trafic Global - Pages vues selon les années et les canaux depuis 2011")
ggsave(filename = "PV-Channel-bar-an.jpg", dpi="print")
EVOLUTION DES PAGES VUES SELON LES CANAUX
#evolution des pages vues selon les canaux
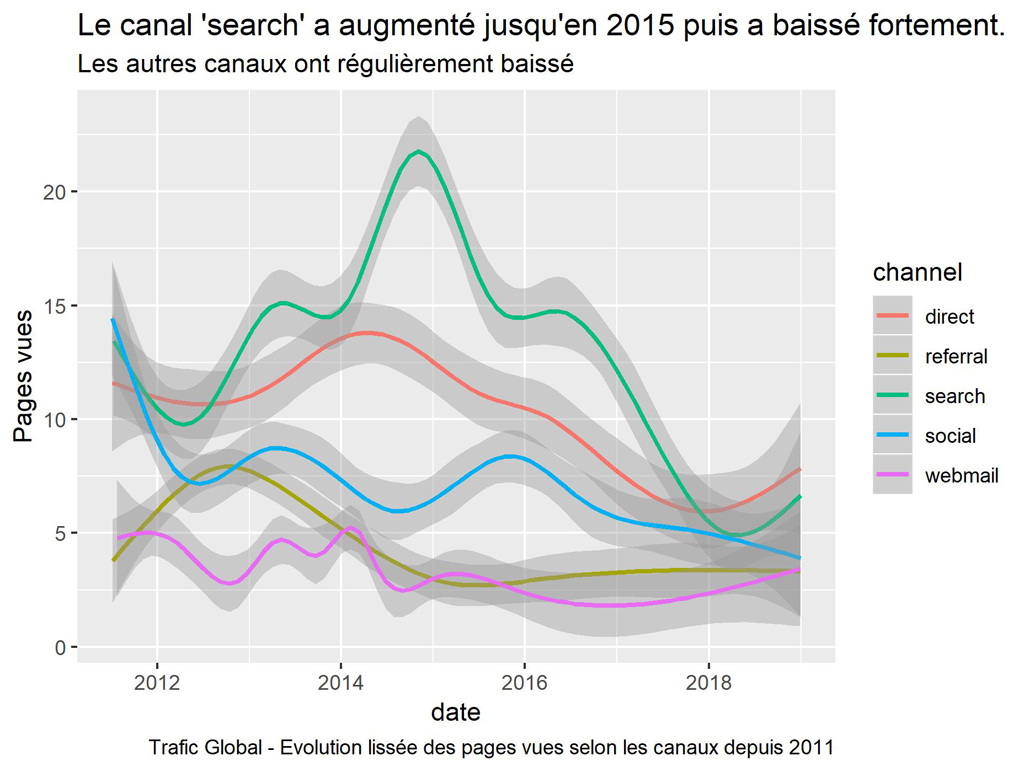
ggplot() +
geom_smooth(data=unique(dateChannel_data), aes(x=date, y=pageViews, col = channel)) +
ylab("Pages vues") +
labs(title = "Le canal 'search' a augmenté jusqu'en 2015 puis a baissé fortement.",
subtitle = "Les autres canaux ont régulièrement baissé",
caption = "Trafic Global - Evolution lissée des pages vues selon les canaux depuis 2011")
ggsave(filename = "PV-Channel-smooth.jpg", dpi="print")
#sauvegarde éventuelle
write.csv2(dateChannel_data, file = "dateChannel_data.csv", row.names=FALSE)
Analyse du trafic de base
Comme on l’a vu dans des précédents articles, le trafic de « base » est le trafic pour les pages hors trafic créé grâce aux « articles marketing »
##########################################################################
# Pour le traffic de base
##########################################################################
#Recréation du trafic de base
#récupere les chemins des pages pour les comparer dans dfPageViews
myArticles$pagePath <- str_split_fixed(myArticles$link, "https://www.networking-morbihan.com", 2)[,2]
patternArticlesToRemove <- unique(myArticles$pagePath)
#Pour les pages de base on enleve les pagePath de nos articles
indexPagePathToRemove <- -grep(pattern = paste(patternArticlesToRemove, collapse="|"), dfPageViews$pagePath)
dfBasePageViews <- dfPageViews[indexPagePathToRemove,]
#puis on enleve les landingPagePath de nos articles
indexLandingPagePathToRemove <- -grep(pattern = paste(patternArticlesToRemove, collapse="|"), dfBasePageViews$landingPagePath)
dfBasePageViews <- dfBasePageViews[indexLandingPagePathToRemove,]
str(dfBasePageViews) #37614 obs.
#recuperation de la variable channel dans la dataframe principale par un left join.
dfBasePVChannel <- left_join(dfBasePageViews, mySourcesChannel, by="source")
#verifs
str(dfBasePVChannel)
head(dfBasePVChannel)
plyr::count(as.factor(dfBasePVChannel$channel))
#creation de la dataframe dateChannel_data par jour et canal pour le
# trafic de base
dateChannel_baseData <- dfBasePVChannel[,c("date", "channel")] %>% #dateChannel_basedata à partir de dfPVChannel
group_by(date, channel) %>% #groupement par date et channel
mutate(pageViews = n()) %>% #total des pageviews = nombre d'observations / date /channel
as.data.frame() %>% #sur d'avoir une data.frame
mutate(year = format(date,"%Y")) #creation de la variable year
#verifs
str(dateChannel_baseData)
head(dateChannel_baseData)
GRAPHIQUE TRAFIC DE BASE DEPUIS 2011
##########################################################################
# Graphique en barre général Répartition du trafic selon
#les canaux pour le trafic de base
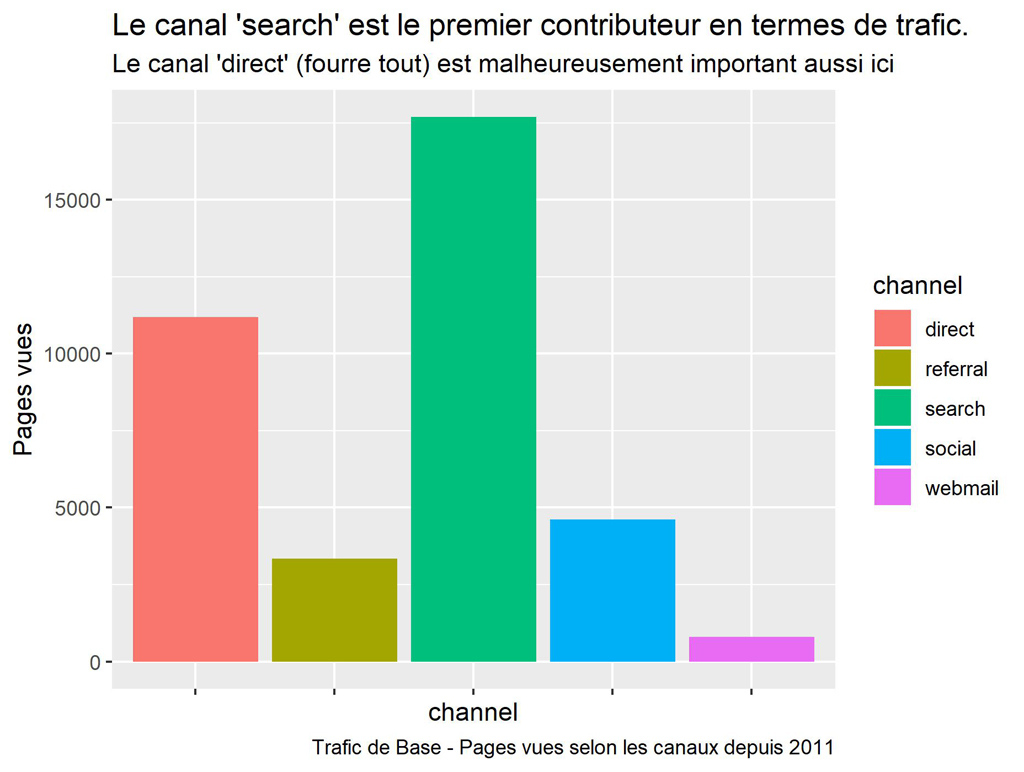
ggplot() +
geom_bar(data=dateChannel_baseData, aes(x=channel, fill=channel)) +
theme(axis.text.x = element_blank()) +
ylab("Pages vues") +
labs(title = "Le canal 'search' est le premier contributeur en termes de trafic.",
subtitle = "Le canal 'direct' (fourre tout) est malheureusement important aussi ici",
caption = "Trafic de Base - Pages vues selon les canaux depuis 2011")
ggsave(filename = "Base-PV-Channel-bar.jpg", dpi="print")
trafic de base par annees
#Graphique en barre par année
#Répartition du trafic de base selon les sources.
ggplot() +
geom_bar(data=dateChannel_baseData, aes(x=channel, fill=channel)) +
facet_wrap(~year, scales="free") +
theme(axis.text.x = element_blank()) +
ylab("Pages vues") +
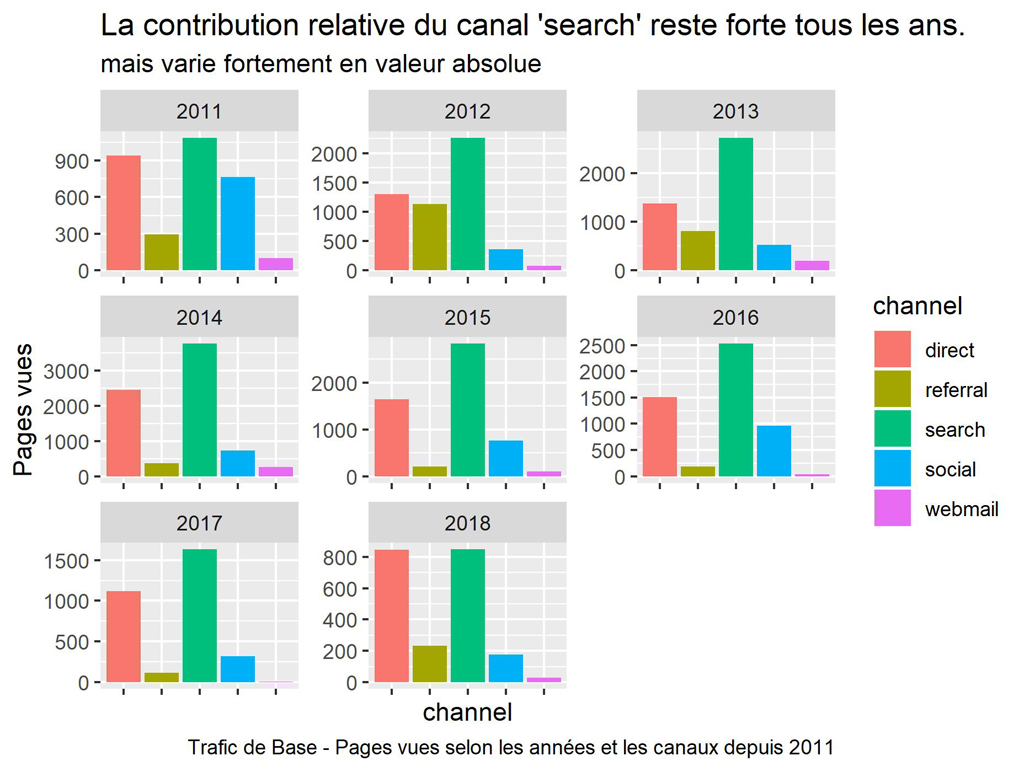
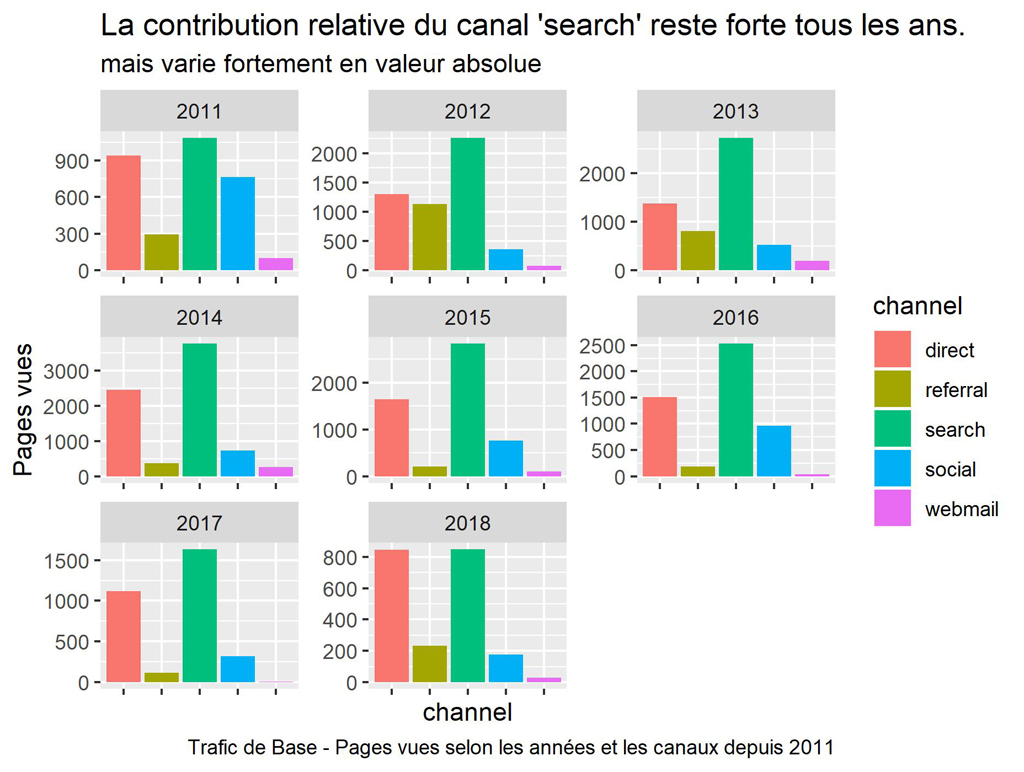
labs(title = "La contribution relative du canal 'search' reste forte tous les ans.",
subtitle = "mais varie fortement en valeur absolue",
caption = "Trafic de Base - Pages vues selon les années et les canaux depuis 2011")
ggsave(filename = "Base-PV-Channel-bar-an.jpg", dpi="print")
EVOLUTION DU TRAFIC DE BASE SELON LES CANAUX
#evolution des pages vues selon les canaux pour le trafic de base.
ggplot() +
geom_smooth(data=unique(dateChannel_baseData), aes(x=date, y=pageViews, col = channel)) +
ylab("Pages vues") +
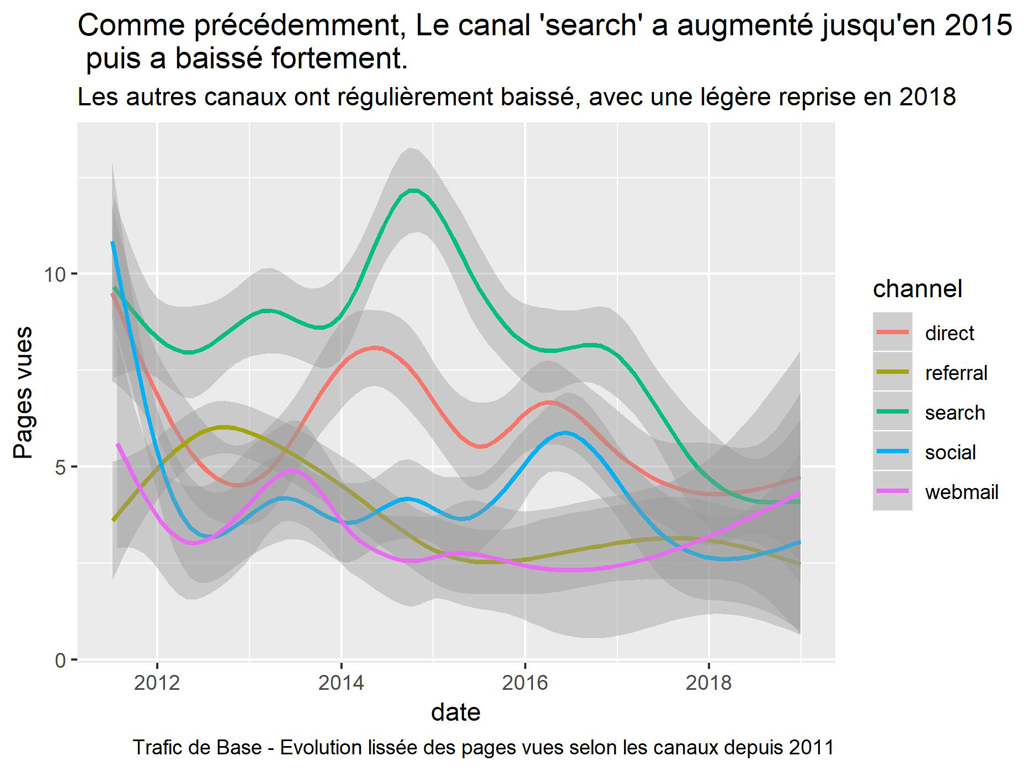
labs(title = "Comme précédemment, Le canal 'search' a augmenté jusqu'en 2015 \n puis a baissé fortement.",
subtitle = "Les autres canaux ont régulièrement baissé, avec une légère reprise en 2018",
caption = "Trafic de Base - Evolution lissée des pages vues selon les canaux depuis 2011")
ggsave(filename = "Base-PV-Channel-smooth.jpg", dpi="print")
#sauvegarde éventuelle pour SAS.
write.csv2(dateChannel_baseData, file = "dateChannel_baseData.csv", row.names=FALSE)
Analyse du trafic Direct Marketing
Nous nous concentrons sur le trafic « Direct
Marketing » i.e. le trafic dont le
point d’entrée est un page « Articles Marketing » qui nous semble le
plus pertinent ici.
##########################################################################
#regardons pour le trafic Direct Marketing uniquement i.e le traffic dont
# la source a dirigé vers une page Articles Marketing
##########################################################################
#Construtcion du trafic Direct Marketing
#on garde uniquement les landingPagePath de nos articles :
#DM = Direct Marketing
patternArticlesToKeep <- unique(myArticles$pagePath)
indexLandingPagePathToKeep <- grep(pattern = paste(patternArticlesToKeep, collapse="|"), dfPageViews$landingPagePath)
dfDMPageViews <- dfPageViews[indexLandingPagePathToKeep,]
str(dfDMPageViews) #28553 obs.
dfDMPVChannel <- left_join(dfDMPageViews, mySourcesChannel, by="source")
str(dfDMPVChannel)
#creation de la dataframe dateChannel_AMdata par jour
dateChannel_DMData <- dfDMPVChannel[,c("date", "channel")] %>% #dateChannel_DMdata à partir de dfPVChannel
group_by(date, channel) %>% #on groupe par date et channel
mutate(pageViews = n()) %>% #total des pageviews = nombre d'observations / date /channel
as.data.frame() %>% #sur d'avoir une data.frame
mutate(year = format(date,"%Y")) #creation de la variable year
Graphique ARTICLES DIRECT MARKETING dePUIS 2011
##########################################################################
# Graphique en barre général Répartition du trafic selon
#les canaux pour le trafic Direct Marketing
ggplot() +
geom_bar(data=dateChannel_DMData, aes(x=channel, fill=channel)) +
theme(axis.text.x = element_blank()) +
ylab("Pages vues") +
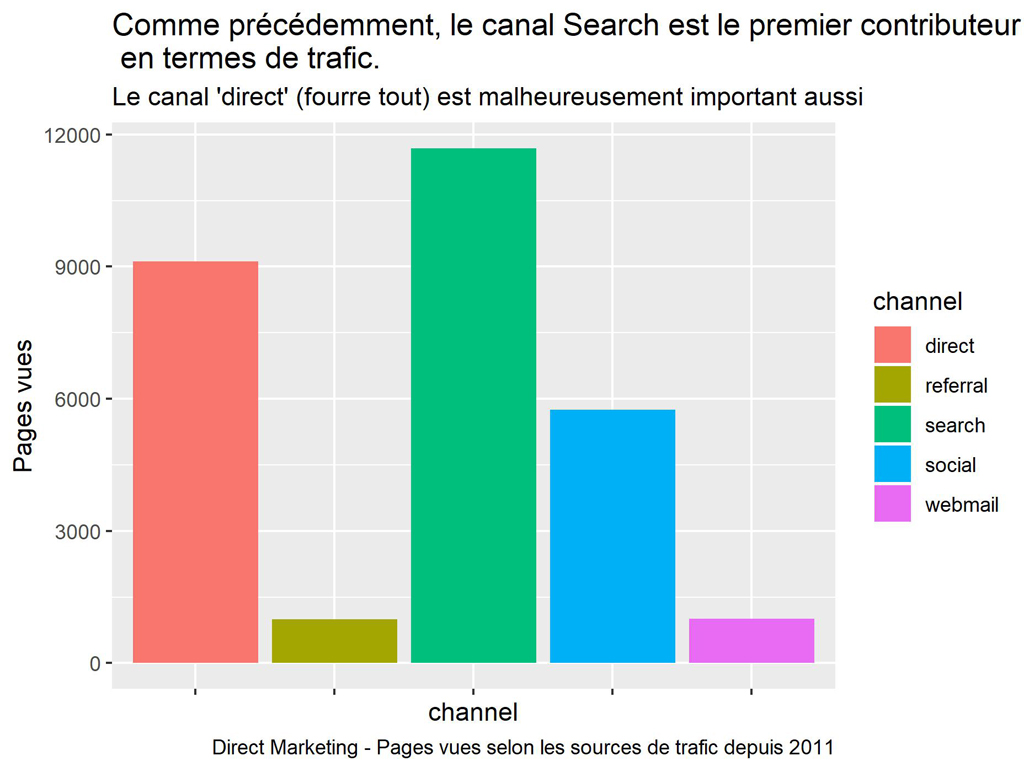
labs(title = "Comme précédemment, le canal Search est le premier contributeur \n en termes de trafic.",
subtitle = "Le canal 'direct' (fourre tout) est malheureusement important aussi",
caption = "Direct Marketing - Pages vues selon les sources de trafic depuis 2011")
ggsave(filename = "DM-PV-Channel-bar.jpg", dpi="print")
Graphique ARTICLES DIRECT MARKETING PAR ANS
#Graphique en barre par année
#Répartition du trafic direct marketing selon les sources.
ggplot() +
geom_bar(data=dateChannel_DMData, aes(x=channel, fill=channel)) +
facet_wrap(~year, scales="free") +
theme(axis.text.x = element_blank()) +
ylab("Pages vues") +
labs(title = "La contribution relative du canal 'search' a augmenté de 2011 à 2013.",
subtitle = "puis s'est stabilisée",
caption = "Direct Marketing - Pages vues selon les années et les canaux depuis 2011")
ggsave(filename = "DM-PV-Channel-bar-an.jpg", dpi="print")
GRAPHIQUE EVOLUTION DU TRAFIC DIRECT MARKETING SELON LES CANAUX DEPUIS 2011
#evolution des pages vues selon les canaux pour le trafic direct marketing
ggplot() +
geom_smooth(data=unique(dateChannel_DMData), aes(x=date, y=pageViews, col = channel)) +
ylab("Pages vues") +
labs(title = "Ici les canaux 'direct' et 'social' étaient plus important que le 'search' \n dans les premières années.",
subtitle = "La forme de la courbe du canal search' ne semble pas avoir beaucoup varié \n par rapport au trafic de base ou global.",
caption = "Direct Marketing - Evolution lissée des pages vues selon les canaux depuis 2011")
ggsave(filename = "DM-PV-Channel-smooth.jpg", dpi="print")
#sauvegarde éventuelle
write.csv2(dateChannel_DMData, file = "dateChannel_DMData.csv", row.names=FALSE)
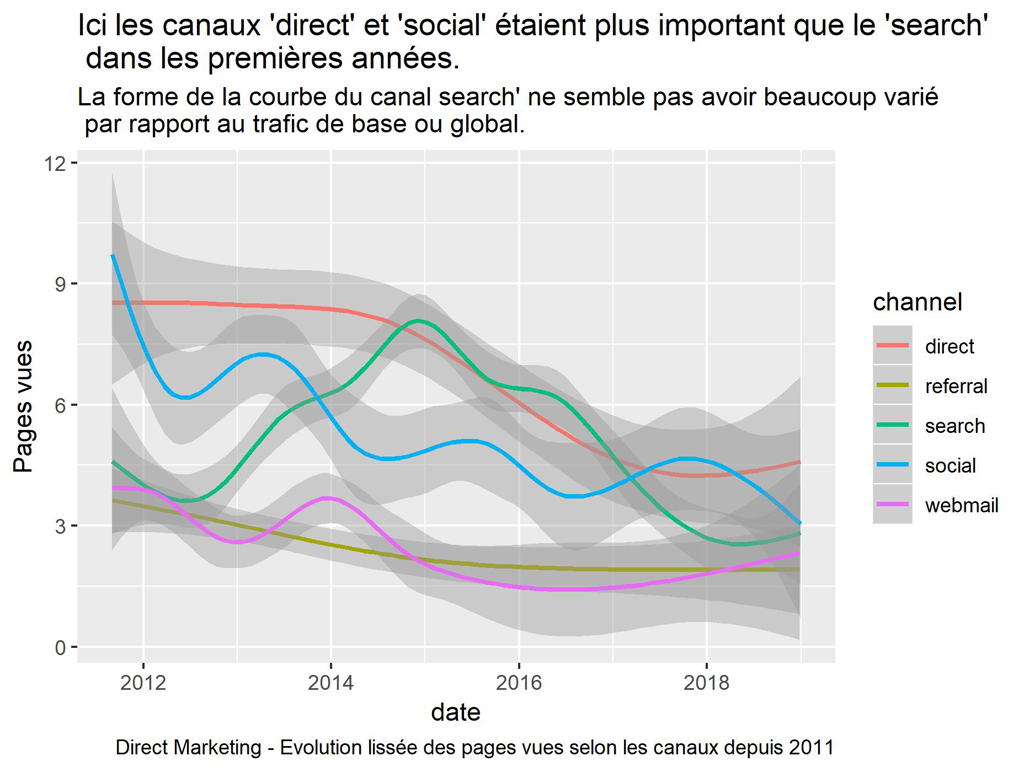
L’importance du trafic « direct » et « social » montre un trafic du à une forte activité Marketing.
Comparatif trafic de base vs trafic Direct Marketing
EVOLUTION DANS LE TEMPS
##########################################################################
# Comparatif DM vs BAse
#evolution des pages vues selon les canaux pour le trafic direct marketing
ggplot() +
geom_smooth(data=unique(dateChannel_baseData), aes(x=date, y=pageViews, col = channel), se = FALSE) +
geom_smooth(data=unique(dateChannel_DMData), aes(x=date, y=pageViews, col = channel), linetype="dashed", se = FALSE) +
ylab("Pages vues") +
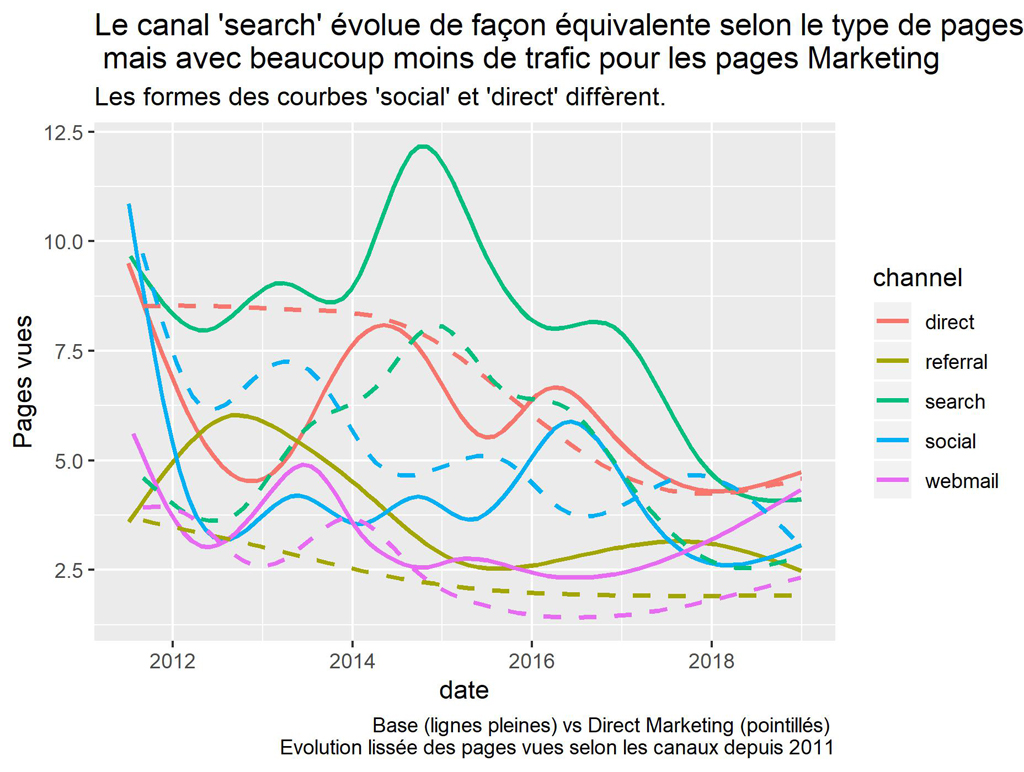
labs(title = "Le canal 'search' évolue de façon équivalente selon le type de pages \n mais avec beaucoup moins de trafic pour les pages Marketing",
subtitle = "Les formes des courbes 'social' et 'direct' diffèrent.",
caption = "Base (lignes pleines) vs Direct Marketing (pointillés) \n Evolution lissée des pages vues selon les canaux depuis 2011")
ggsave(filename = "Base-DM-PV-Channel-smooth.jpg", dpi="print")
Graphique des CANAUX EN PROPOrTION Direct MArketing / Base
#Comparatif des proportions
#proportions des différents trafic
propDMBase <- nrow(dfDMPVChannel) / nrow(dfBasePVChannel) #0.76
myPropDMBase<- data.frame(channel = c("direct", "referral", "search", "social", "webmail" ),
proportion = c(0,0,0,0,0))
nrow(dfBasePVChannel) / nrow(dfDMPVChannel)
myPropDMBase[1, "proportion"] <- sum(dfDMPVChannel$channel=="direct") / sum(dfBasePVChannel$channel=="direct") #0.81
myPropDMBase[2, "proportion"] <- sum(dfDMPVChannel$channel=="referral") / sum(dfBasePVChannel$channel=="referral") #0.29
myPropDMBase[3, "proportion"] <- sum(dfDMPVChannel$channel=="search") / sum(dfBasePVChannel$channel=="search") #0.66
myPropDMBase[4, "proportion"] <-sum(dfDMPVChannel$channel=="social") / sum(dfBasePVChannel$channel=="social") #1.25
sum(dfBasePVChannel$channel=="social") / sum(dfDMPVChannel$channel=="social") #0,80
myPropDMBase[5, "proportion"] <- sum(dfDMPVChannel$channel=="webmail") / sum(dfBasePVChannel$channel=="webmail") #1.26
sum(dfBasePVChannel$channel=="webmail") / sum(dfDMPVChannel$channel=="webmail") #0.79
ggplot() +
geom_point(data=myPropDMBase, aes(x=channel, y=proportion, col = channel), size=5) +
geom_hline(yintercept = propDMBase, color= "red" ) +
ylab("Proportion Direct Marketing / Base") +
labs(title = "Le traffic Direct Marketing est composé en proportion plus importante \n de trafic direct, social et webmail",
subtitle = "Le trafic de base de referral et de search.",
caption = "Proportions Direct Marketing / Base selon les canaux - Total depuis 2011")
ggsave(filename = "Base-DM-PV-Channel-Prop.jpg", dpi="print")
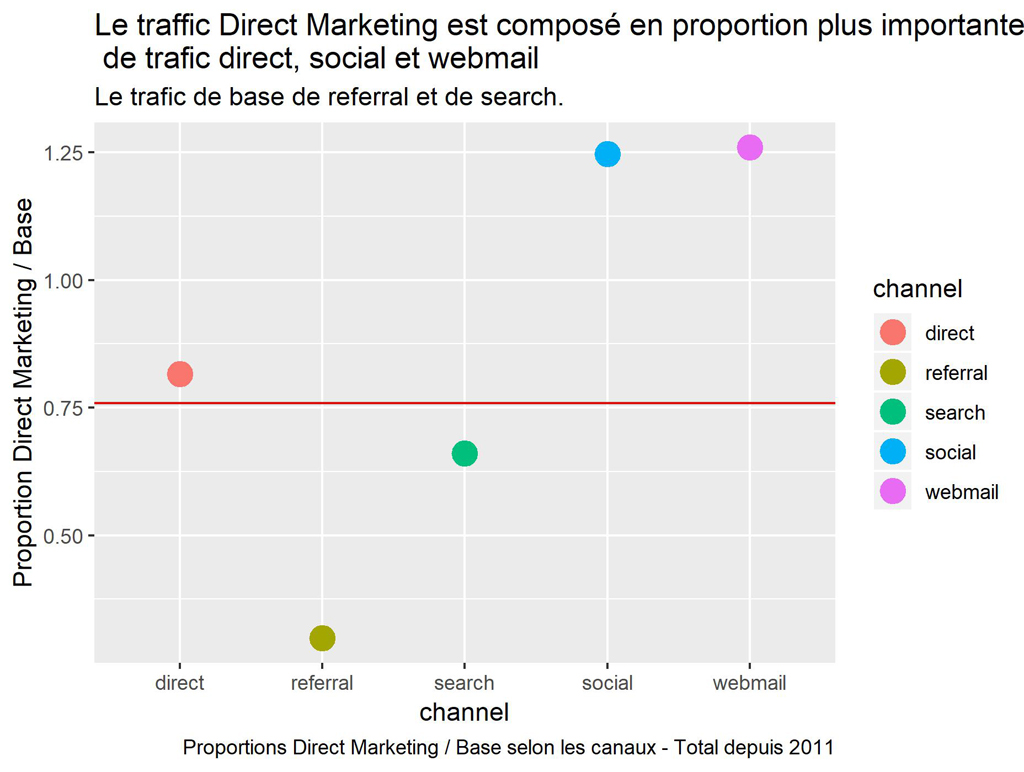
Le trafic « Referral « est plutôt un trafic pour les pages de base, et plus spécifiquement pour la page d’accueil du site qui génère généralement le plus de liens externes.
Rem : la significativité des proportions a été testé avec la fonction prop.test de R :
#verification que les proportions sont statistiquement valides.
#trafic direct
#H0 prop DM/base direct <= DM/base Total ,
#H1 : prop DM/base direct > DM/base Total (p.value << 0.05)
(resPropTestDirect <- prop.test(x= sum(dfDMPVChannel$channel=="direct"),
n = sum(dfBasePVChannel$channel=="direct"),
p=propDMBase,
alternative = "greater"))
resPropTestDirect$p.value #1.678199e-44 << 0.05 : H1
#trafic referral
#H0 prop DM/base referral >= DM/base Total ,
#H1 : prop DM/base referral < DM/base Total (p.value << 0.05)
(resPropTestDirect <- prop.test(x= sum(dfDMPVChannel$channel=="referral"),
n = sum(dfBasePVChannel$channel=="referral"),
p=propDMBase,
alternative = "less"))
resPropTestReferral$p.value #0 << 0.05 #H1
#trafic search
#H0 prop DM/base search >= DM/base Total ,
#H1 : prop DM/base search < DM/base Total (p.value << 0.05)
(resPropTestSearch <- prop.test(x= sum(dfDMPVChannel$channel=="referral"),
n = sum(dfBasePVChannel$channel=="referral"),
p=propDMBase,
alternative = "less"))
resPropTestSearch$p.value #0 << 0.05#H1
##########################################################################
#trafic social #! le test est inversé car
#sum(dfDMPVChannel$channel=="social") >
#sum(dfBasePVChannel$channel=="social")
#Par ailleurs nrow(dfBasePVChannel) / nrow(dfDMPVChannel) = 1,31 > 1
#donc on teste avec p=0.99
#H0 proportion base/DM social >= 0.99 , H1 : prop base/DM social < 0.99
#(p.value << 0.05)
(resPropTestSocial <- prop.test(x= sum(dfBasePVChannel$channel=="social"),
n = sum(dfDMPVChannel$channel=="social"),
p=0.99,
alternative = "less"))
resPropTestSocial$p.value #0 << 0.05 : H1 <0.99 donc à fortiori < 1,31
#trafic webmail, comme précédemment le test est inversé car
#sum(dfDMPVChannel$channel=="webmail") >
#sum(dfBasePVChannel$channel=="webmail")
#Par ailleurs nrow(dfBasePVChannel) / nrow(dfDMPVChannel) = 1,31 > 1
#donc on teste avec p=0.99
#H0 proportion base/DM webmail >= 0.99 , H1 : prop base/DM webmail < 0.99
#(p.value << 0.05)
(resPropTestWebmail <- prop.test(x= sum(dfBasePVChannel$channel=="webmail"),
n = sum(dfDMPVChannel$channel=="webmail"),
p=0.99,
alternative = "less"))
resPropTestWebmail$p.value #0 << 0.05 : H1 <0.99 donc à fortiori < 1,31
##########################################################################
# MERCI pour votre attention !
##########################################################################
On s’en doutait un peu, mais les Articles Marketing on un trafic qui comporte plus de trafic de Webmail et de réseaux sociaux. Cela semblait évident mais c’est mieux en le démontrant :-).
Pour aller plus loin dans l’analyse des canaux, nous ferons une Analyse en Composantes Principales dans un prochain article.
A Bientôt,
Pierre