Partager la publication "Quelle est la durée de vie de mes articles sur mon site ? R – I"
Dans cet article nous allons nous intéresser à la « durée de vie » de nos articles sur un site Web.
Autrement dit, la durée où, en moyenne, mes articles « apportent » du trafic sur mon site. Nous l’exprimerons ici en nombre de mois.
Cette problématique peut être intéressante, par exemple, si l’on veut comparer l’efficacité de différents rédacteurs, de différentes thématiques ou encore de différents sites …
Cet article étant un peu long il sera divisé en deux parties.
Comment allons nous procéder ?
Logiciel R :
Dans cet article nous allons utiliser R. Dans un prochain article nous procéderons avec Python.
Si vous ne l’avez pas encore fait, téléchargez le Logiciel R sur le site du CRAN https://cran.r-project.org/, ainsi que l’environnement de développement RStudio ici : https://www.rstudio.com/products/rstudio/download/.
Jeu de données
Comme précédemment, nous utiliserons les données du site de Networking Morbihan. On partira des données de trafic récupérées de Google Analytics et nettoyées et de la liste des « articles marketing »*.
Si vous souhaitez utiliser vos données, suivez les étapes décrites dans les articles précédents suivants, pour bien comprendre la démarche et créer vos propres fichiers :
- googleanalyticsR : importation de vos données Google Analytics dans R
- Nettoyage du Spam dans Google Analytics avec R – Partie I
- Nettoyage du Spam dans Google Analytics avec R – Partie II
- Détection du trafic Web significatif avec R et AnomalyDetection
- Le Marketing de contenu amène-t-il du trafic sur mon site Web ? Logiciel R
* Pour le trafic « articles marketing » on considèrera 3 types de pages vues liées aux articles marketing, de plus en plus restrictives :
- AM (Articles Marketing) : il s’agit les pages vues liées aux articles comme les pages vues des articles eux-mêmes et les pages vues des autres pages dont la page d’entrée serait une page « d’article marketing ». ». Rem : Le « trafic de base » correspond au reste des pages vues.
- DM (Direct Marketing) : il s’agit du trafic des pages (Articles Marketing ou non) dont l’entrée s’est faite via une page article marketing.
- UM (Unique Marketing) : il s’agit du trafic des pages articles marketing dont l’entrée s’est faite par la même page article marketing.
Code Source :
Vous pouvez récupérer les différents bouts de code ci-dessous ou récupérer tout le code gratuitement dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-r-duree-de-vie-des-articles/
Chargement des bibliothèques et récupération des données :
##########################################################################
# Auteur : Pierre Rouarch 2019 - Licence GPL 3
# ArticleLifetimeR
# Duree de vie des articles "Marketing"
# Pour illustrer notre propos nous utiliserons le jeu de données de
# l'association Networking-Morbihan
.
##########################################################################
#Packages et bibliothèques utiles (décommenter au besoin)
##########################################################################
#install.packages("lubridate") #si vous ne l'avez pas
#install.packages("tseries")
#install.packages("devtools")
#devtools::install_github("twitter/AnomalyDetection") #pour anomalyDetection de Twitter
#install.packages("XML")
#install.packages("stringi")
#install.packages("BSDA")
#install.packages("BBmisc")
#install.packages("stringi")
#install.packages("FactoMineR")
#install.packages("factoextra")
#install.packages("rcorr")
#install.packages("lubridate") #si vous ne l'avez pas
library (lubridate) #pour yday
#library(tseries) #pour ts
library(AnomalyDetection) #pour anomalydetectionVec
#library(XML) # pour xmlParse
#library(stringi) #pour stri_replace_all_fixed(x, " ", "")
library(BSDA) #pour SIGN.test
library(BBmisc) #pour which.first
#install.packages("stringi")
library(stringi) #pour stri_detect
#library(ggfortify) #pour ploter autoplot type ggplot
#install.packages("tidyverse") #si vous ne l'avez pas #pour gggplot2, dplyr, tidyr, readr, purr, tibble, stringr, forcats
#install.packages("forecast") #pour ma
#Chargement des bibliothèques utiles
library(tidyverse) #pour gggplot2, dplyr, tidyr, readr, purr, tibble, stringr, forcats
library(forecast) #pour arima, ma, tsclean
##########################################################################
# Récupération du Jeu de données nettoyé des pages et des articles
##########################################################################
dfPageViews <- read.csv("dfPageViews.csv", header=TRUE, sep=";")
#str(dfPageViews) #verif
#transformation de la date en date 🙂
dfPageViews$date <- as.Date(dfPageViews$date,format="%Y-%m-%d")
#str(dfPageViews) #verif
str(dfPageViews) #72821 obs
dfPageViews$index <- 1:nrow(dfPageViews) #création d'un pour retrouver les "articles marketing"
#ensuite
#pour les articles
myArticles <- read.csv("myArticles.csv", header=TRUE, sep=";")
#transformation de la date en date 🙂
myArticles$date <- as.Date(myArticles$date,format="%Y-%m-%d")
#str(myArticles) #verif
Calcul du « trafic de base »
Il peut être intéressant de déterminer au préalable le « trafic de base » : dfBasePageViews. On crée aussi un jeu de données du trafic de base par jour : BaseDaily_data
########################################################################## # Calcul du "trafic de base" ie hors "articles marketing" # On va supprimer toutes les pages vues correspondantes aux articles # "Marketing" ainsi que toutes les pages vues dont l'entrée s'est faite # par un article "Marketing". on comparera ensuite au traffic # Articles Marketing. ########################################################################## #récupere les chemins des pages pour les comparer dans dfPageViews myArticles$pagePath <- str_split_fixed(myArticles$link, "https://www.networking-morbihan.com", 2)[,2] patternArticlesToRemove <- unique(myArticles$pagePath) #Pour les pages de base on enleve les pagePath de nos articles indexPagePathToRemove <- -grep(pattern = paste(patternArticlesToRemove, collapse="|"), dfPageViews$pagePath) dfBasePageViews <- dfPageViews[indexPagePathToRemove,] #puis on enleve les landingPagePath de nos articles indexLandingPagePathToRemove <- -grep(pattern = paste(patternArticlesToRemove, collapse="|"), dfBasePageViews$landingPagePath) dfBasePageViews <- dfBasePageViews[indexLandingPagePathToRemove,] str(dfBasePageViews) #37614 obs. #pour la visualisation des pages "de base" (voir plus bas) dfBaseDatePV <- as.data.frame(dfBasePageViews$date) colnames(dfBaseDatePV)[1] <- "date" BaseDaily_data <- dfBaseDatePV %>% group_by(date) %>% #groupement par date mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date as.data.frame() %>% #sur d'avoir une data.frame unique() %>% #ligne unique par jour. mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours) mutate(year = format(date,"%Y")) %>% #creation de la variable year mutate(dayOfYear = yday(date)) #creation de la variable dayOfYear
Trafic « articles marketing »
Il suffit de soustraire le trafic de base au trafic global. Créons aussi un jeu de données pour le trafic par jour.
########################################################### # Détermination du trafic des pages articles marketing ########################################################### #le trafic des pages vues des pages articles est le reste dfAMPageViews <- anti_join(x = dfPageViews, y = dfBasePageViews, by = "index") str(dfAMPageViews) #Calcul des pages vues "articles marketing" par jour dfAMDatePV <- as.data.frame(dfAMPageViews$date) colnames(dfAMDatePV)[1] <- "date" AMDaily_data <- dfAMDatePV %>% group_by(date) %>% #groupement par date mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date as.data.frame() %>% #sur d'avoir une data.frame unique() %>% #ligne unique par jour. mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours) mutate(year = format(date,"%Y")) %>% #creation de la variable year mutate(dayOfYear = yday(date)) #creation de la variable dayOfYear
Remarque : il reste 35207 observations pour les pages « Articles Marketing »
Comparatif trafic de base vs trafic articles marketing
Par curiosité, l’idée est ici de voir si les deux trafics sont corrélés. On pourra essayer de le voir graphiquement ou bien de calculer le Tau de Kendall (car ici la distribution n’est pas normale – je vous passe le détail 🙂 ).
Le Tau de Kendall se situe entre -1 et 1. Une valeur proche de 0 indique qu’il n’y a pas de corrélation. Une valeur positive indique une corrélation positive, une valeur négative une corrélation négative. Plus on s’approche de -1 ou 1, plus les variables sont corrélées.
##########################################################################
# Comparons le trafic "de base" par rapport au trafic "articles marketing"
############################################################################
#Qui est le plus grand ?
nrow(AMDaily_data) #2478
nrow(BaseDaily_data) #2502
#merge pour être sur la même taille. (le plus grand)
BaseDaily_AMDaily_data <- merge(x = BaseDaily_data, y = AMDaily_data, by = "date", all.x = TRUE)
str(BaseDaily_AMDaily_data)
#Est-ce que l'on a des na ?
sum(is.na(BaseDaily_AMDaily_data$Pageviews.x)) #0 na
sum(is.na(BaseDaily_AMDaily_data$Pageviews.y)) #180 na
#NA en 0
BaseDaily_AMDaily_data[is.na(BaseDaily_AMDaily_data$Pageviews.y),"Pageviews.y"] <- 0
#recalculate cnt_ma30.y avec les 0
BaseDaily_AMDaily_data$cnt_ma30.y = ma(BaseDaily_AMDaily_data$Pageviews.y, order=30)
#Comparons le traffic de base vs "Articles MArketing" - Pas très lisible sur toute la période
ggplot() +
geom_line(data=BaseDaily_AMDaily_data, aes(date, Pageviews.x), color="blue") +
geom_line(data = BaseDaily_AMDaily_data, aes(date, Pageviews.y), color="red") +
scale_x_date('year') +
ylab("pages vues") +
ggtitle(label = "PV depuis 2011 - bleu : pages articles marketing - Rouge : pages de base")
#Pas très lisible
ggsave(filename = "PV-s2011-base-vs-mkt.jpg", dpi="print") #sauvegarde du dernier ggplot.
#Corrélation de Kendall #tau 0.3814596 pas terrible
cor.test(BaseDaily_AMDaily_data$Pageviews.x, BaseDaily_AMDaily_data$Pageviews.y,
method="kendall", use = "complete.obs")
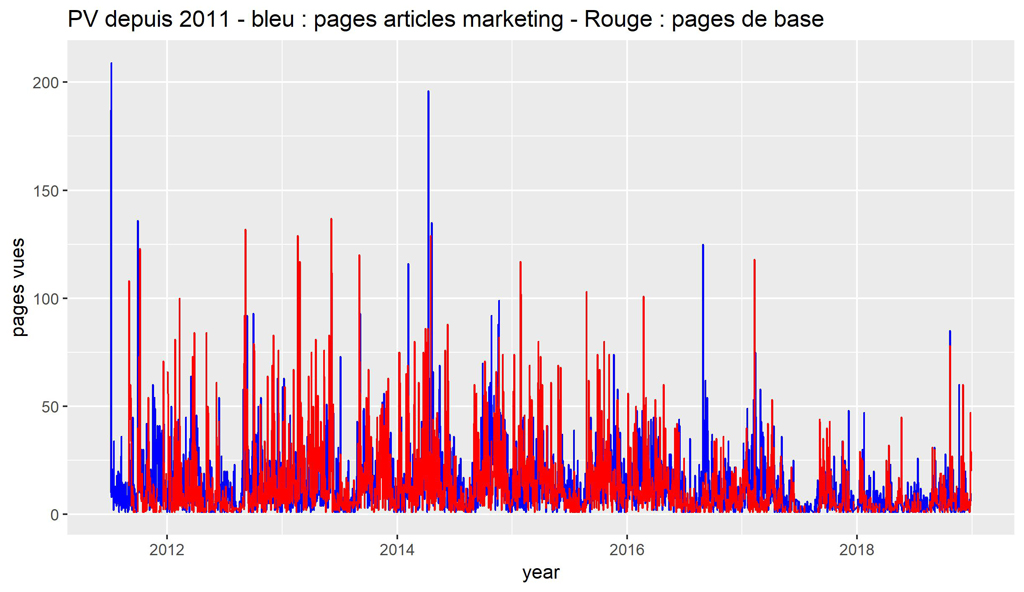
Le graphique n’est pas très lisible. On peut juste voir que le trafic de base semble plus régulier. Il pourrait être intéressant de diviser le graphique en année, mais ce n’est pas le propos de cet article. Si vous êtes curieux allez-y !
Le Tau de Kendall donne une valeur de 0,39 ce qui indique une corrélation positive, ce à quoi on pouvait s’attendre, mais cette valeur n’est pas non plus énorme. Essayons en moyenne mobile :
Comparatif en moyenne mobile
#################################################################################
#Et en moyenne mobile sur 30 jours.
ggplot() +
geom_line(data=BaseDaily_AMDaily_data, aes(date, cnt_ma30.x), color="blue") +
geom_line(data=BaseDaily_AMDaily_data, aes(date, cnt_ma30.y), color="red") +
scale_x_date('year') +
ylab("moyenne mobile 30 j - pages vues") +
ggtitle(label = "Moy.Mob. 30 j. - PV depuis 2011 - bleu : pages articles marketing \n Rouge : pages de base")
ggsave(filename = "PV-s2011-base-vs-mkt-mm30.jpg", dpi="print") #sauvegarde du dernier ggplot.
#Corrélation de Kendall #tau : 0.5426576
cor.test(BaseDaily_AMDaily_data$cnt_ma30.x, BaseDaily_AMDaily_data$cnt_ma30.y,
method="kendall", use = "complete.obs")
#Sauvegarde éventuelle
write.csv2(BaseDaily_AMDaily_data, file = "BaseDaily_AMDaily_data.csv", row.names=FALSE)
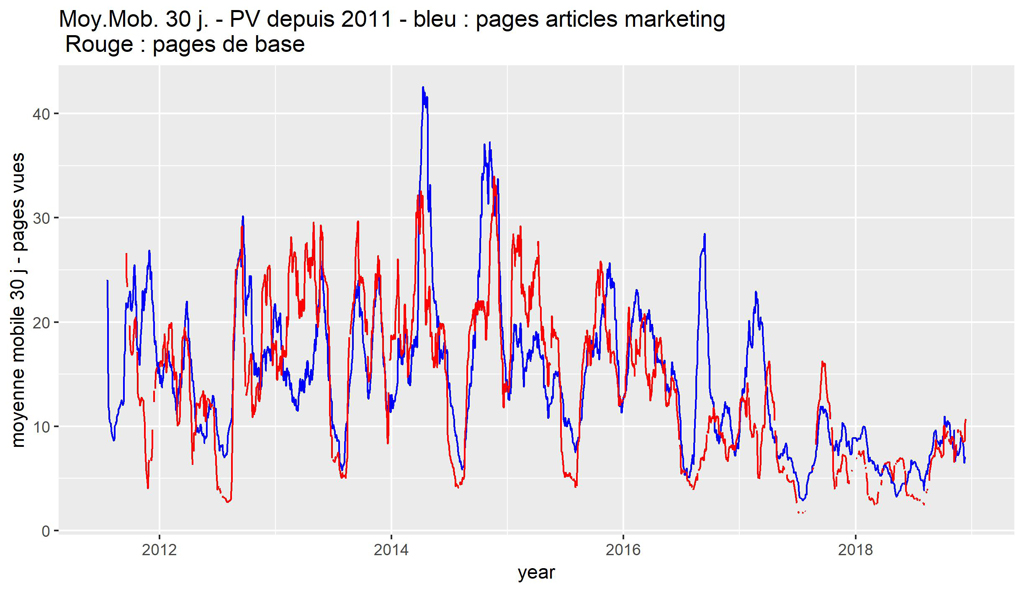
C’est légèrement plus lisible, il y a des moments ou les courbes se suivent de près. Le Tau de Kendall est de 0,54 ce qui indique une corrélation positive un peu meilleure que précédemment.
A ce stade on constate qu’il y a une corrélation positive du trafic de base et du trafic articles marketing, ce qui parait somme toute logique, mais c’est mieux de le démontrer :-). Revenons à nos moutons …
Distribution du trafic des articles marketing à x mois
L’idée est ici de voir, au bout d’une période donnée (1,2 ,10 mois…), quels sont les trafics mensuels de mes différentes pages articles . Statistiquement, il s’agit d’afficher la distribution du trafic pour mes articles.
Pour faire cela nous avons créé une fonction que l’on pourra appeler pour chaque mois (cette fonction sera aussi utilisée pour le trafic Direct Marketing et pour le trafic Unique Marketing ) :
############################################################################
# Fonction pour récupérer une période sur un numéro de période et
# un nombre de jour
############################################################################
getMyDistribution <- function(myPageViews, myArticles, myNumPeriode, myNbrOfDays=30, myLastDate, myTestType="AM") {
#'myPageViews = une dataframe de Pages vues à tester avec les variables au minimum
#' date : date YYYY-MM-DD - date de la visite sur la page
#' landinfPagePath : chr path de la page d'entrée sur le site ex "/rentree-2011"
# PagePath : chr path de la page visitée sur le site site ex "/rentree-2011"
#'myArticles = une dataframe de Pages vues que l'on souhaite investiguer et qui sont
#'parmi les précédentes avec les variables au minimum
#' date : date YYYY-MM-DD - date de la visite sur la page
#' PagePath : chr - path de la page visitée sur le site site ex "/rentree-2011"
#'myNumPeriode : integer Numéro de période par exemple 1 si c'est la première période
#'myNbrOfDays : int - nombre de jours pour la période 30 par défaut
#'myLastDate : date YYYY-MM-DD - date limite à investiguer.
#'myTestType="AM" : chr - "AM" test du landingPagePath ou pagePath sinon test du pagePath seul.
dfThisPeriodPV <- data.frame(ThisPeriodPV=double()) #pour sauvegarder la distribution
for (i in (1:nrow(myArticles))) {
Link <- myArticles[i,"pagePath"] #lien i /
#cat(paste(myArticles[i,"date"],"\n"))
Date1 <- myArticles[i,"date"]+((myNumPeriode-1)*myNbrOfDays)
Date2 <- Date1+myNbrOfDays
if (myTestType == "AM") {
myPV <- myPageViews[which( myPageViews$pagePath == Link | myPageViews$landingPagePath == Link ), ]
} else {
myPV <- dfDMPageViews[which( myPageViews$pagePath == Link ), ]
}
#MArketing
myPVPeriode <- myPV[myPV$date %in% Date1:Date2,]
myPVPeriode <- nrow(myPVPeriode)
if (Date1 > myLastDate) {
myPVPeriode <- NA #pour éviter d'avoir des 0
}
dfThisPeriodPV[i, "ThisPeriodPV"] <- myPVPeriode
}
return(dfThisPeriodPV)
}
#/getMyDistribution
Pour le Mois 1
############################################################################
# Pour le mois 1
############################################################################
myMonthNumber <- 1
dfAMThisMonthPV <- getMyDistribution(myPageViews=dfAMPageViews,
myArticles=myArticles,
myNumPeriode=myMonthNumber,
myNbrOfDays=30,
myLastDate=dfAMPageViews[nrow(dfAMPageViews),"date"],
myTestType="AM")
#test de normalité
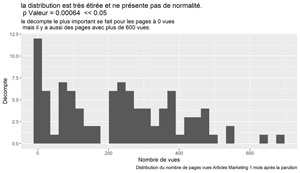
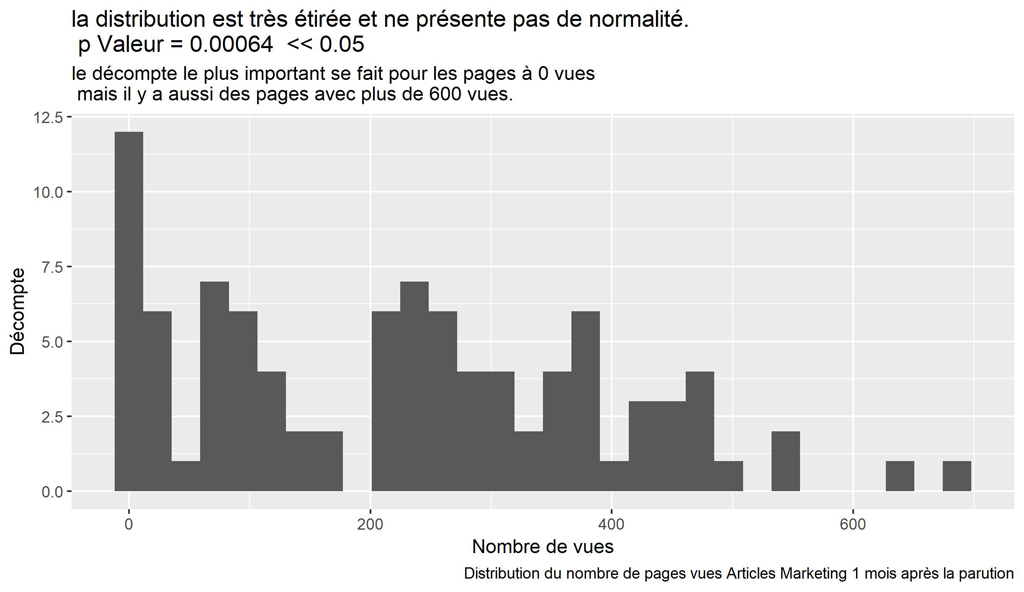
resST <- shapiro.test(dfAMThisMonthPV$ThisPeriodPV)
resST$p.value #0.0006370982 normalité rejetée
ggplot(data=dfAMThisMonthPV, aes(x=ThisPeriodPV)) +
geom_histogram() +
xlab("Nombre de vues") +
ylab("Décompte") +
labs(title = paste("la distribution est très étirée et ne présente pas de normalité.\n p Valeur =", format(round(resST$p.value, 5), scientific = FALSE)," << 0.05"),
subtitle = "le décompte le plus important se fait pour les pages à 0 vues \n mais il y a aussi des pages avec plus de 600 vues.",
caption = paste("Distribution du nombre de pages vues Articles Marketing", myMonthNumber, "mois après la parution"))
##################################################################
# which.max(dfAMThisMonthPV$ThisPeriodPV) #page la plus vues
ggsave(filename = stri_replace_all_fixed(paste("Dist-PV-AM-Mois-",myMonthNumber,".jpg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot en fonction du mois
Pour le mois 2
############################################################################
# Pour le mois 2
############################################################################
myMonthNumber <- 2
dfAMThisMonthPV <- getMyDistribution(myPageViews=dfAMPageViews,
myArticles=myArticles,
myNumPeriode=myMonthNumber,
myNbrOfDays=30,
myLastDate=dfAMPageViews[nrow(dfAMPageViews),"date"],
myTestType="AM")
#test de normalité
resST <- shapiro.test(dfAMThisMonthPV$ThisPeriodPV)
resST$p.value
ggplot(data=dfAMThisMonthPV, aes(x=ThisPeriodPV)) +
geom_histogram() +
xlab("Nombre de vues") +
ylab("Décompte") +
#labs standard
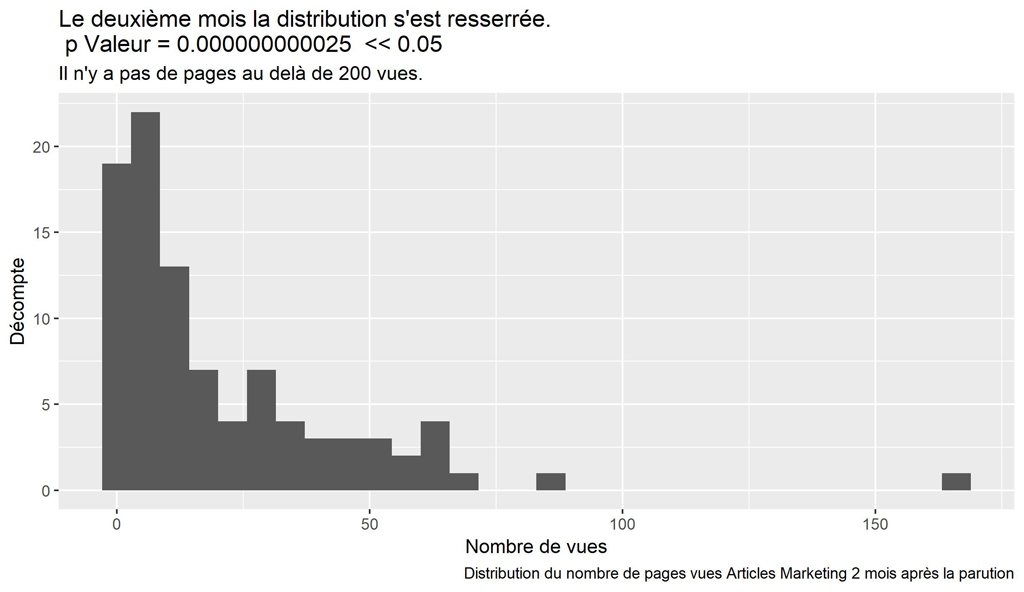
labs(title = paste("Le deuxième mois la distribution s'est resserrée.\n p Valeur =", format(round(resST$p.value, 12), scientific = FALSE)," << 0.05"),
subtitle = "Il n'y a pas de pages au delà de 200 vues.",
caption = paste("Distribution du nombre de pages vues Articles Marketing", myMonthNumber, "mois après la parution"))
##################################################################
# which.max(dfAMThisMonthPV$ThisPeriodPV)
ggsave(filename = stri_replace_all_fixed(paste("Dist-PV-AM-Mois-",myMonthNumber,".jpg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot en fonction du mois
Pour le mois 10
############################################################################
# Pour le mois 10
############################################################################
myMonthNumber <- 10
dfAMThisMonthPV <- getMyDistribution(myPageViews=dfAMPageViews,
myArticles=myArticles,
myNumPeriode=myMonthNumber,
myNbrOfDays=30,
myLastDate=dfAMPageViews[nrow(dfAMPageViews),"date"],
myTestType="AM")
#test de normalité
resST <- shapiro.test(dfAMThisMonthPV$ThisPeriodPV)
resST$p.value
ggplot(data=dfAMThisMonthPV, aes(x=ThisPeriodPV)) +
geom_histogram() +
xlab("Nombre de vues") +
ylab("Décompte") +
#labs standard
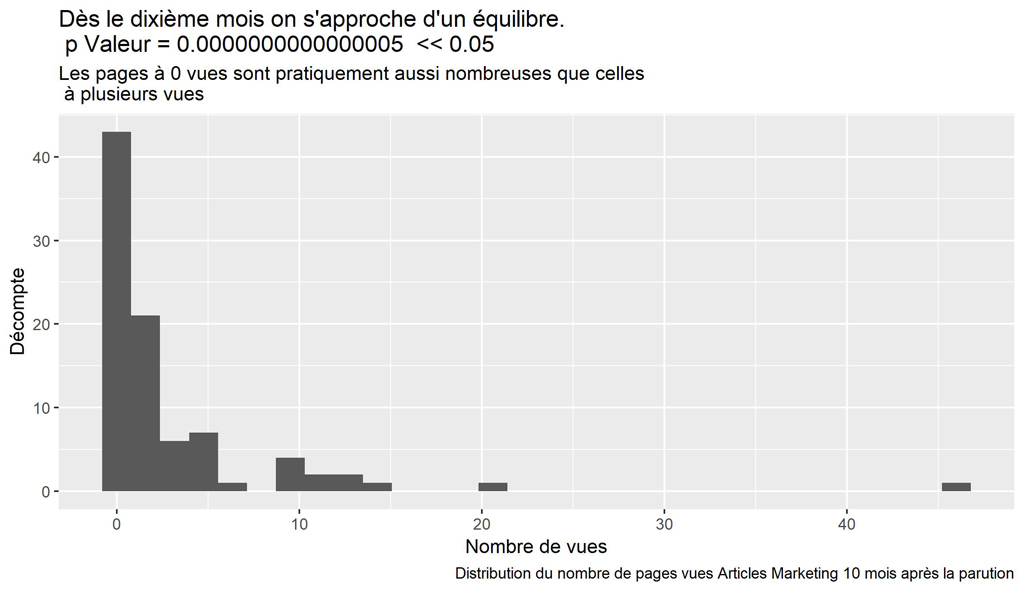
labs(title = paste("Dès le dixième mois on s'approche d'un équilibre.\n p Valeur =", format(round(resST$p.value, 16), scientific = FALSE)," << 0.05"),
subtitle = "Les pages à 0 vues sont pratiquement aussi nombreuses que celles \n à plusieurs vues",
caption = paste("Distribution du nombre de pages vues Articles Marketing", myMonthNumber, "mois après la parution"))
##################################################################
# which.max(dfAMThisMonthPV$ThisPeriodPV)
ggsave(filename = stri_replace_all_fixed(paste("Dist-PV-AM-Mois-",myMonthNumber,".jpg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot en fonction du mois
Pour le mois 40
############################################################################
# Pour le mois 40
############################################################################
myMonthNumber <- 40
dfAMThisMonthPV <- getMyDistribution(myPageViews=dfAMPageViews,
myArticles=myArticles,
myNumPeriode=myMonthNumber,
myNbrOfDays=30,
myLastDate=dfAMPageViews[nrow(dfAMPageViews),"date"],
myTestType="AM")
#test de normalité
resST <- shapiro.test(dfAMThisMonthPV$ThisPeriodPV)
resST$p.value
ggplot(data=dfAMThisMonthPV, aes(x=ThisPeriodPV)) +
geom_histogram() +
xlab("Nombre de vues") +
ylab("Décompte") +
#labs standard
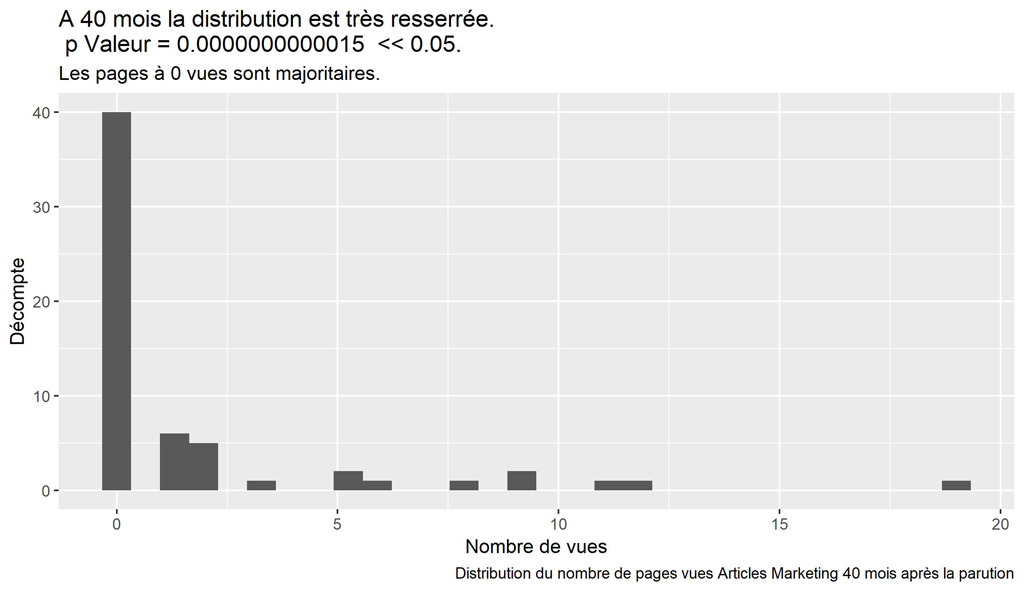
labs(title = paste("A 40 mois la distribution est très resserrée.\n p Valeur =", format(round(resST$p.value, 13), scientific = FALSE)," << 0.05."),
subtitle = "Les pages à 0 vues sont majoritaires.",
caption = paste("Distribution du nombre de pages vues Articles Marketing", myMonthNumber, "mois après la parution"))
##################################################################
#sauvegarde du dernier ggplot en fonction du mois
ggsave(filename = stri_replace_all_fixed(paste("Dist-PV-AM-Mois-",myMonthNumber,".jpg"), " ", ""), dpi="print")
Dans notre cas, on constate que, assez rapidement, vers le mois 10, les pages articles marketing semblent ne plus apporter de trafic.
On vérifiera cela statistiquement dans la suite de l’article.