

Partager la publication "Publication d’articles vs événements significatifs en Python"
Je ne sais pas si vous l’avez remarqué, mais depuis quelques temps je vous propose 2 versions de mes articles, l’une avec le code source R, l’autre avec le code source Python.
Cet article reprend en fait l’article « Le Marketing de contenu amène-t-il du trafic sur mon site Web ? » que j’avais traité en R, le voici cette fois en Python.
Comme je ne reproduis pas toutes les explications ici, reportez vous à la version en R.
Question
La question reste la même :
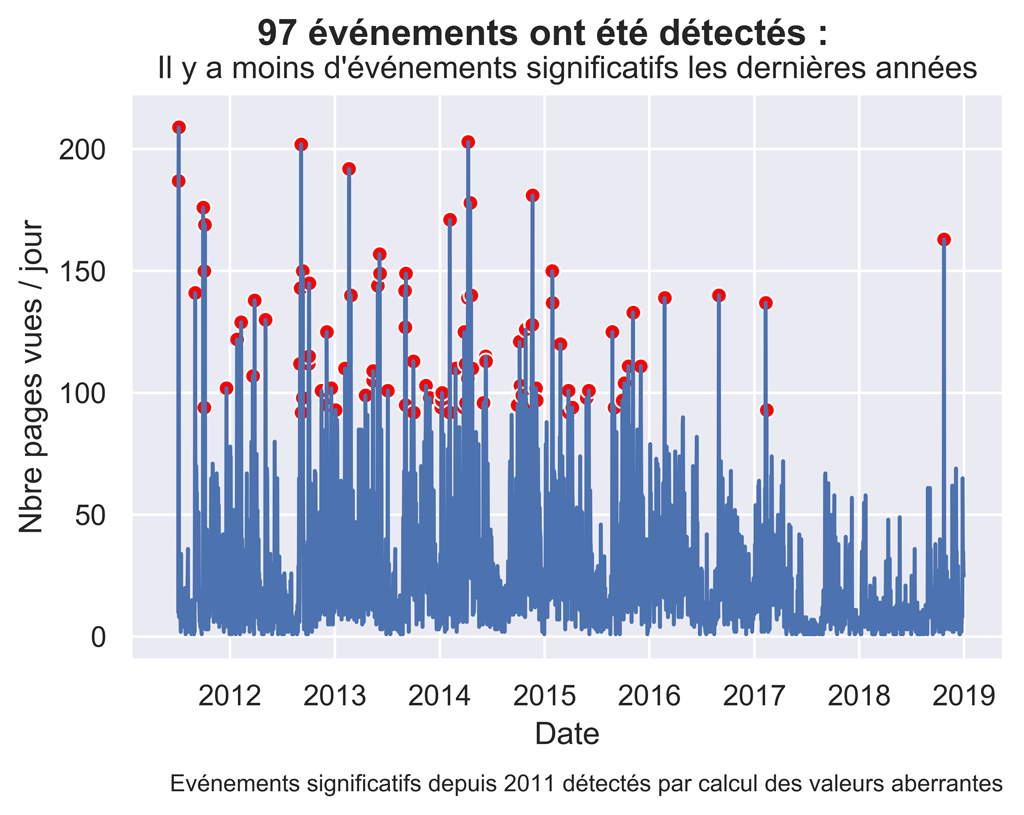
Supposons que j’ai préalablement identifié des événements significatifs sur mon site Web.
C’est à dire, ici, les jours ou mon nombre de pages vues est beaucoup plus important que d’habitude.
« Est-ce que ces pics de trafic correspondent aux efforts de création de contenu et d’actions marketing connexes que j’ai menés juste avant ? »
Pour avoir une idée de cela, nous allons simplement ajouter les dates de publications des articles à la courbe des événements significatifs que nous avions réalisée précédemment :
De quoi aurons nous besoin ?
Python Anaconda
Comme précédemment, nous vous invitons à utiliser la version de Python Anaconda qui contient tous les outils et les bibliothèques statistiques nécessaires.
Anaconda est compatible Windows, Mac et Linux. Rendez vous sur la page de téléchargement d’Anaconda Distribution pour télécharger la version qui vous convient.
Jeu de données
2 options :
Soit récupérer nos données exemples sur notre Github :
- Données de trafic (pages vues) issues de Google Analytics et nettoyées.
- Données (notamment les dates de publication) des articles sur notre site Web.
(dézippez les archives dans le même répertoire que votre code source Python)
Soit suivre toute la procédure pour vous créer votre propre jeu de données :
- Importer les données de Google Analytics API avec Python Anaconda.
- Nettoyage du Spam dans Google Analytics avec Python.
- Détection du trafic Web significatif avec Python.
Code Source
Vous pouvez soit copier/coller les morceaux de source ci-dessous, soit récupérer gratuitement le source en entier dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-python-apport-de-trafic-par-marketing-de-contenu/.
Chargement des bibliothèques utiles
On charge les bibliothèques utiles et on vérifie que l’on est bien dans le bon répertoire.
# -*- coding: utf-8 -*- """ Created on Tue May 28 10:50:38 2019 @author: Pierre """ ######################################################################### # ArticlesPubDateVSSignTrafficPython # Comparatifs Date de publication des articles vs événelents significatifs # Auteur : Pierre Rouarch 2019 # Données : Issues de l'API de Google Analytics - # Comme illustration Nous allons travailler sur les données du site # https://www.networking-morbihan.com ############################################################# # On démarre ici pour récupérer les bibliothèques utiles !! ############################################################# #def main(): #on ne va pas utiliser le main car on reste dans Spyder #Chargement des bibliothèques utiles (décommebter au besoin) #import numpy as np #pour les vecteurs et tableaux notamment import matplotlib.pyplot as plt #pour les graphiques #import scipy as sp #pour l'analyse statistique import pandas as pd #pour les Dataframes ou tableaux de données import seaborn as sns #graphiques étendues import math #notamment pour sqrt() #from datetime import timedelta #from scipy import stats #pip install scikit-misc #pas d'install conda ??? #from skmisc import loess #pour methode Loess compatible avec stat_smooth #conda install -c conda-forge plotnine #from plotnine import * #pour ggplot like #conda install -c conda-forge mizani #from mizani.breaks import date_breaks #pour personnaliser les dates affichées #Si besoin Changement du répertoire par défaut pour mettre les fichiers de sauvegarde #dans le même répertoire que le script. import os print(os.getcwd()) #verif #mon répertoire sur ma machine - nécessaire quand on fait tourner le programme #par morceaux dans Spyder. #myPath = "C:/Users/Pierre/CHEMIN" #os.chdir(myPath) #modification du path #print(os.getcwd()) #verif
Récupération des données de pages vues
On récupère les données de pages vues dans le fichier dfPageViews.csv et on crée un jeu de donnée par jour.
###############################################################################
#Récupération du fichier de données des pages vues
###############################################################################
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
dfPageViews = pd.read_csv("dfPageViews.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
dfPageViews.dtypes
dfPageViews.count() #72821 enregistrements
dfPageViews.head(20)
##############################################################################
#creation de la dataframe daily_data par jour
dfDatePV = dfPageViews[['date', 'pageviews']].copy() #nouveau dataframe avec que la date et le nombre de pages vues
daily_data = dfDatePV.groupby(dfDatePV['date']).count() #
#dans l'opération précédente la date est partie dans l'index
daily_data['date'] = daily_data.index #recrée la colonne date.
daily_data['cnt_ma30'] = daily_data['pageviews'].rolling(window=30).mean()
daily_data['Année'] = daily_data['date'].astype(str).str[:4]
daily_data['DayOfYear'] = daily_data['date'].dt.dayofyear #récupère la date du jour
daily_data.reset_index(inplace=True, drop=True) #on reindexe
Détection des événements significatifs
On détecte les événements significatifs par la méthode de Tau de Thomson Modifié vu précédemment. On récupère les données dans « myOutliers ».
########################################################################## # Détection des événements significatifs - Données_aberrantes # on va utiliser la méthode du Test de Tau de Thomson Modifié # Voir ici https://fr.wikipedia.org/wiki/Donn%C3%A9e_aberrante ########################################################################## #Etape 1 Calcul du Seuil n=daily_data.shape[0] #taille de l'échantilon 2658 #Récupérons la valeur de Tau sur la table comme nous avons n = 2658 #notre valeur de tau est 1,96 tau=1.96 #calculons le seuil de base threshold = (tau*(n-1))/( math.sqrt(n) * math.sqrt(n-2+(math.pow(tau,2))) ) #threshold=1.9585842166773806 #Etape 2 Evaluation du zcore par rapport au seuil # ici z_score = (daily_data['pageviews'] - mean)/std donné # par zcore de scipy.stats mais que l'on aurait pu calculer. à la main from scipy.stats import zscore daily_data['pageviews_zscore'] = zscore(daily_data['pageviews']) myOutliersBase = daily_data[daily_data['pageviews_zscore'] > threshold] len(myOutliersBase) #136 valeurs aberrantes #Finalement on va augmenter le seuil de façon empirique pour réduire le #nombre de valeurs aberrantes à un même niveau de ce que l'on avait avec R threshold = 2.29 myOutliers = daily_data[daily_data['pageviews_zscore'] > threshold] len(myOutliers) #97 valeurs
Récupération des articles
On récupère la date des articles à partir des fichiers XML de sauvegarde de WordPress. On récupère l’info dans le jeu de données « myArticles ».
################################################################################
# Plus spécifiquement
# Récupération des Articles par categories. Les catégories qui nous intéressent
# sont celles pour lesquelles les administrateurs ont créé des articles qu'ils
# souhaitaient mettre en avant :
# "A la une",
# "Actualités",
# "Les Autres Rendez-vous",
# "Networking Apéro",
# "Networking Conseil"
# "Networking Cotravail",
# L'export de WordPress ne permet pas d'exporter un choix de catégories, on est
# obligé de faire catégorie par catégorie
################################################################################
#bibliothèque pour fichier xml #conda install -c anaconda lxml
from lxml import etree
#Categorie A La une
xmlNW56Articles = etree.parse("NW56.WP.ALaUne.xml")
links = [node.text.strip() for node in xmlNW56Articles.xpath("//item//link")]
pubDates = [node.text.strip() for node in xmlNW56Articles.xpath("//item//pubDate")]
dfNW56AlaUne = pd.DataFrame({'links':links,'pubDates':pubDates})
#Categorie "Actualités",
xmlNW56Articles = etree.parse("NW56.WP.Actualites.xml")
links = [node.text.strip() for node in xmlNW56Articles.xpath("//item//link")]
pubDates = [node.text.strip() for node in xmlNW56Articles.xpath("//item//pubDate")]
dfNW56Actualites = pd.DataFrame({'links':links,'pubDates':pubDates})
#Categorie ""Les Autres Rendez-vous",
xmlNW56Articles = etree.parse("NW56.WP.LesAutresRDV.xml")
links = [node.text.strip() for node in xmlNW56Articles.xpath("//item//link")]
pubDates = [node.text.strip() for node in xmlNW56Articles.xpath("//item//pubDate")]
dfNW56LesAutresRDV = pd.DataFrame({'links':links,'pubDates':pubDates})
#Categorie "Networking Apéro",
xmlNW56Articles = etree.parse("NW56.WP.NetworkingApero.xml")
links = [node.text.strip() for node in xmlNW56Articles.xpath("//item//link")]
pubDates = [node.text.strip() for node in xmlNW56Articles.xpath("//item//pubDate")]
dfNW56NetworkingApero = pd.DataFrame({'links':links,'pubDates':pubDates})
#Categorie "Networking Conseil",
xmlNW56Articles = etree.parse("NW56.WP.NetworkingConseil.xml")
links = [node.text.strip() for node in xmlNW56Articles.xpath("//item//link")]
pubDates = [node.text.strip() for node in xmlNW56Articles.xpath("//item//pubDate")]
dfNW56NetworkingConseil = pd.DataFrame({'links':links,'pubDates':pubDates})
#Categorie "Networking Cotravail",
xmlNW56Articles = etree.parse("NW56.WP.NetworkingCotravail.xml")
links = [node.text.strip() for node in xmlNW56Articles.xpath("//item//link")]
pubDates = [node.text.strip() for node in xmlNW56Articles.xpath("//item//pubDate")]
dfNW56NetworkingCotravail = pd.DataFrame({'links':links,'pubDates':pubDates})
dfNW56Articles = pd.concat([dfNW56AlaUne, dfNW56Actualites, dfNW56LesAutresRDV,
dfNW56NetworkingApero, dfNW56NetworkingConseil,
dfNW56NetworkingCotravail])
dfNW56Articles.count() #152
dfNW56Articles = dfNW56Articles.drop_duplicates(subset=['links'])
dfNW56Articles.count() #verif - 104 Articles
dfNW56Articles.dtypes
#création d'une date équivalente à celle dans daily data
dfNW56Articles['date'] = dfNW56Articles.pubDates.str[:16].astype('datetime64[ns]')
dfNW56Articles.dtypes
dfNW56Articles.sort_values(by='date')
daily_data.dtypes
dfNW56Articles.reset_index(inplace=True, drop=True) #reset index
#merge
myArticles = pd.merge(dfNW56Articles, daily_data, on='date', sort=True)
myArticles.describe() #95 articles au final.
# Sauvegarde de myArticles en csv pourrait servir dans d'autres articles.
myArticles.to_csv("myArticles.csv", sep=";", index=False) #séparateur ;
Graphique depuis 2011
Graphique des événements
##########################################################################
# Graphiques des événements et des publications des articles
# sur toute la période
##########################################################################
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='pageviews', data= daily_data, color='grey', alpha=0.2)
sns.scatterplot(x='date', y='pageviews', data= myOutliers, color='red', alpha=0.5)
sns.scatterplot(x='date', y='pageviews', data= myArticles, color='blue', marker="+")
fig.suptitle( str(len(myOutliers)) + " événements (ronds rouges) pour " + str(len(myArticles)) + " articles (croix bleues) : ", fontsize=14, fontweight='bold')
ax.set(xlabel="Date", ylabel='Nbre pages vues / jour',
title="Les articles des dernières années ne semblent pas suivis d'effets.")
fig.text(.9,-.05,"Evénements significatifs et publications des articles depuis 2011",
fontsize=9, ha="right")
#plt.show()
fig.savefig("Events-Articles-s2011.png", bbox_inches="tight", dpi=600)
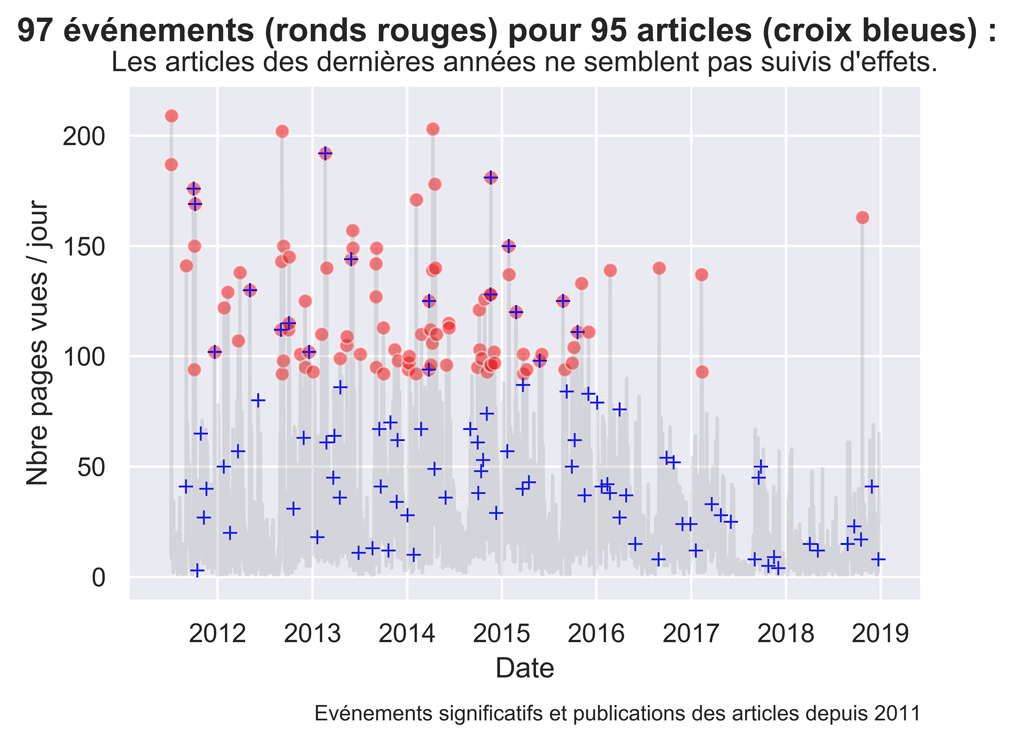
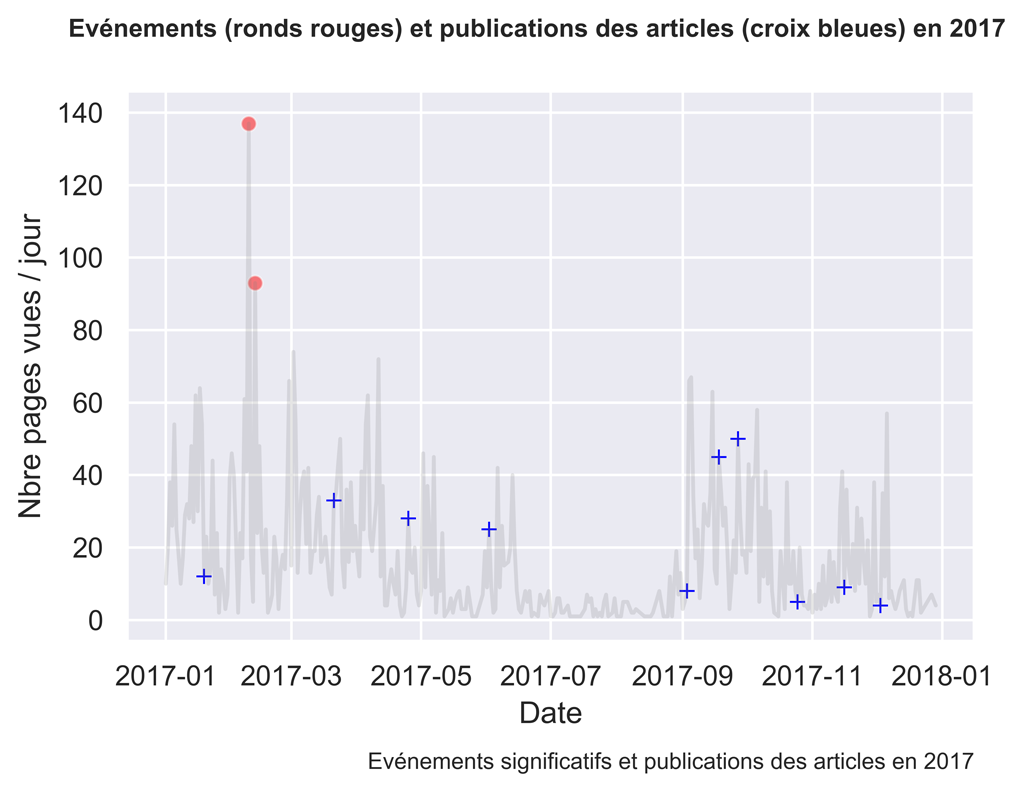
Les actions de 2017 Et 2018 ne semblent pas beaucoup suivis d’effets. Pour les autres années ce n’est pas très lisible. Nous allons faire des graphiques par années.
Graphiques par années
Pour faire moins de code on a créé une fonction.
#############################################################################
#Plots par années
def plotEventsByYear(myYear="2011") :
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='pageviews', data= daily_data[daily_data.Année==myYear], color='grey', alpha=0.2)
sns.scatterplot(x='date', y='pageviews', data= myOutliers[myOutliers.Année==myYear], color='red', alpha=0.5)
sns.scatterplot(x='date', y='pageviews', data= myArticles[myArticles.Année==myYear], color='blue', marker="+")
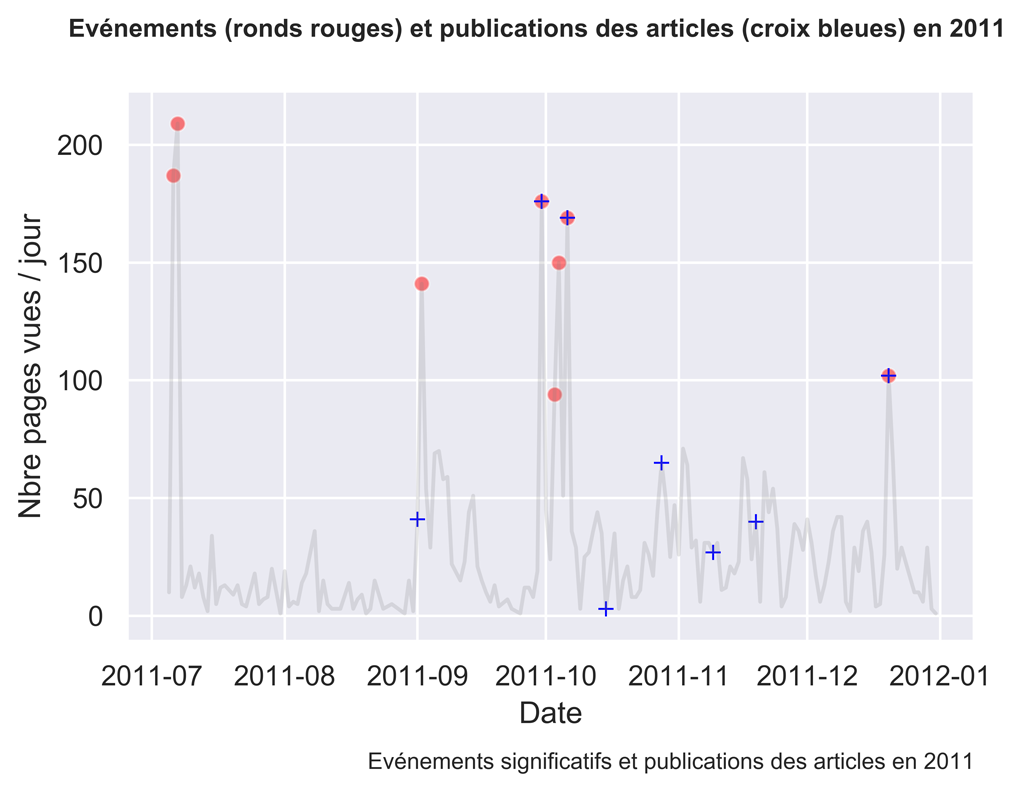
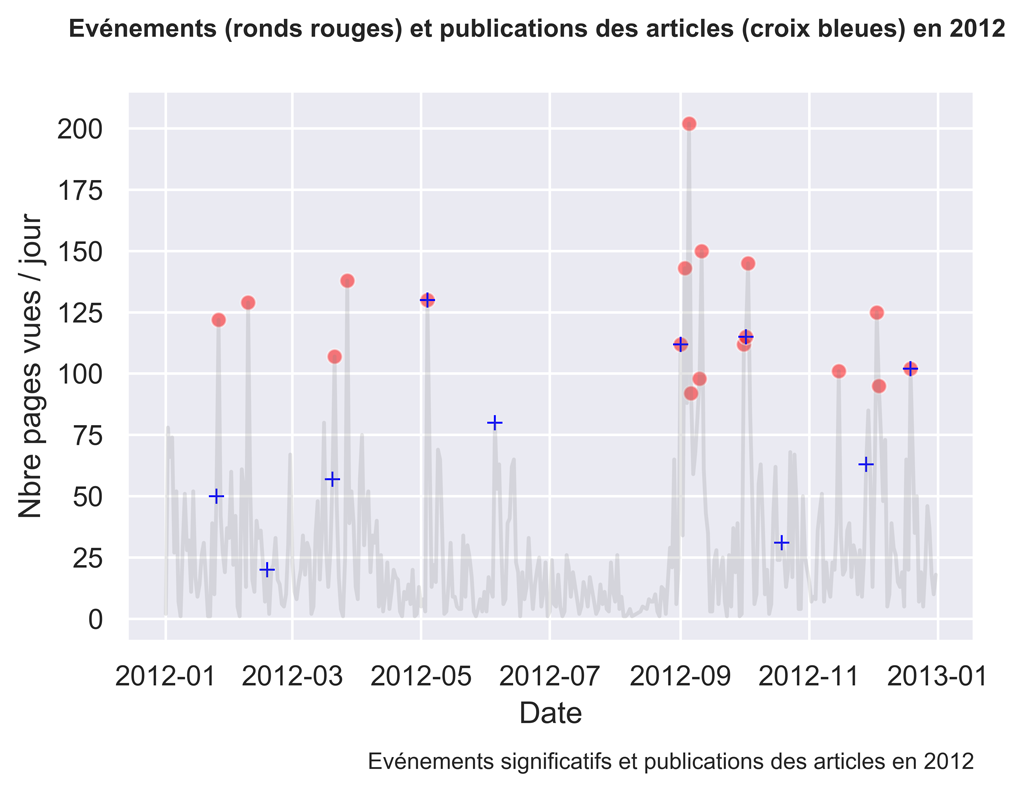
fig.suptitle( "Evénements (ronds rouges) et publications des articles (croix bleues) en " + myYear , fontsize=10, fontweight='bold')
ax.set(xlabel="Date", ylabel='Nbre pages vues / jour')
fig.text(.9,-.05,"Evénements significatifs et publications des articles en " + myYear,
fontsize=9, ha="right")
#plt.show()
fig.savefig("Events-Articles-"+myYear+".png", bbox_inches="tight", dpi=600)
for myYear in ("2011", "2012", "2013", "2014", "2015", "2016", "2017", "2018") :
plotEventsByYear(myYear=myYear)
2011
2012
2013
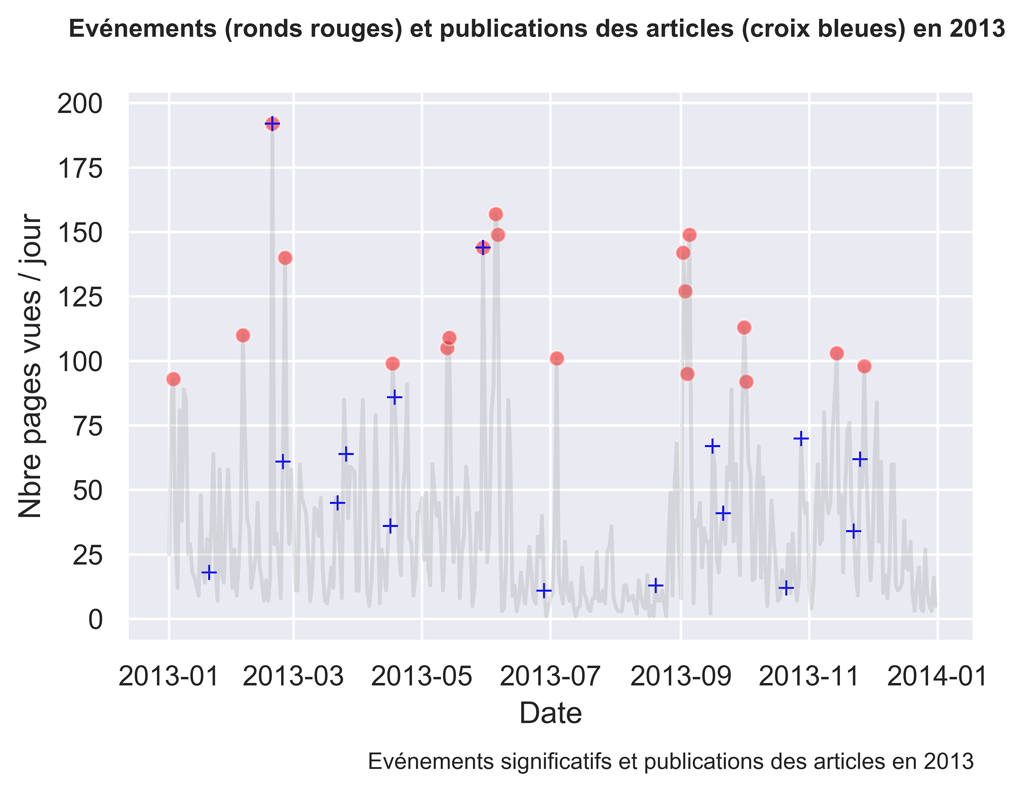
2014
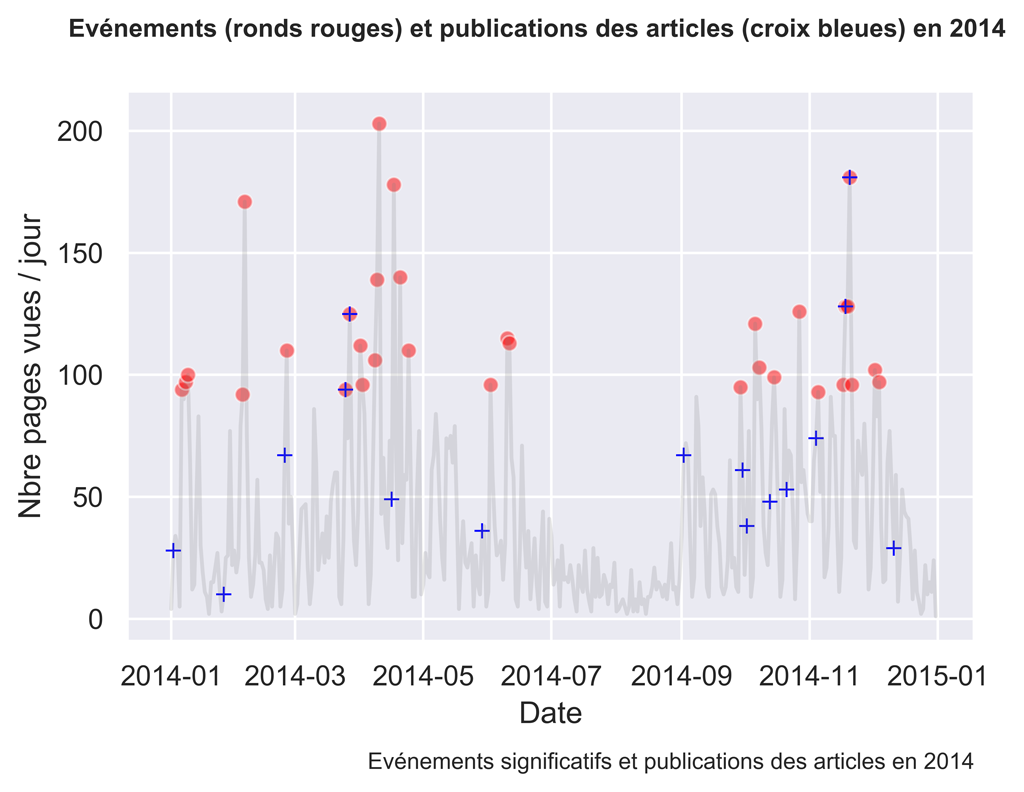
2015
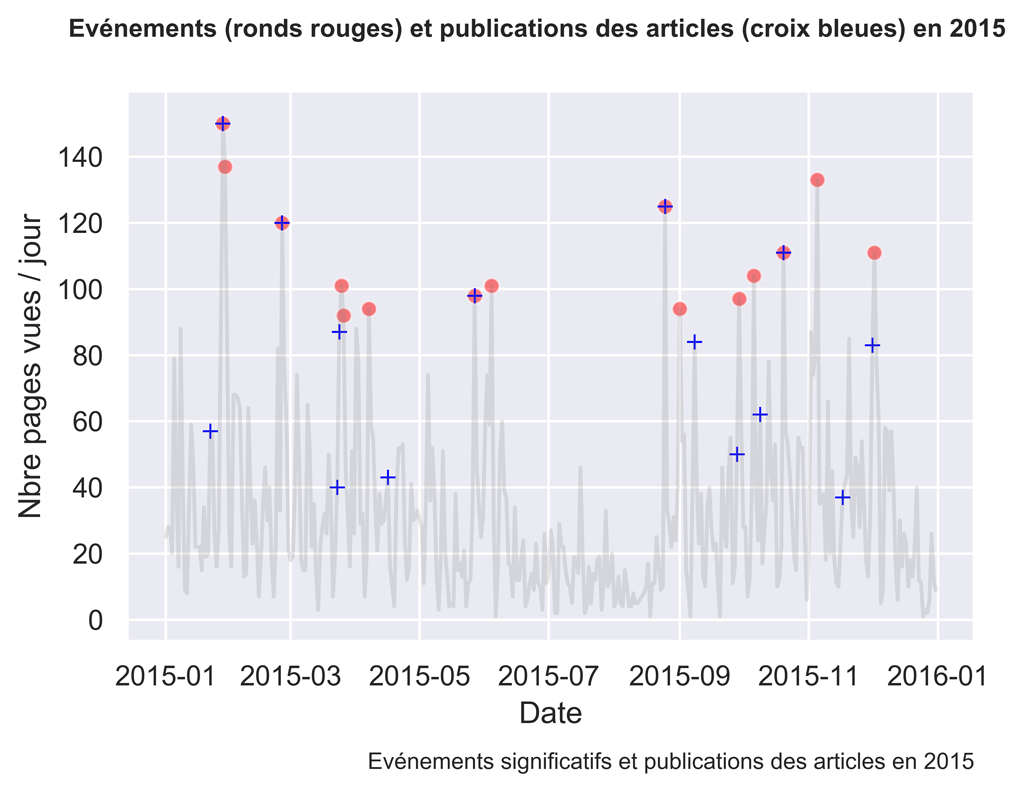
2016
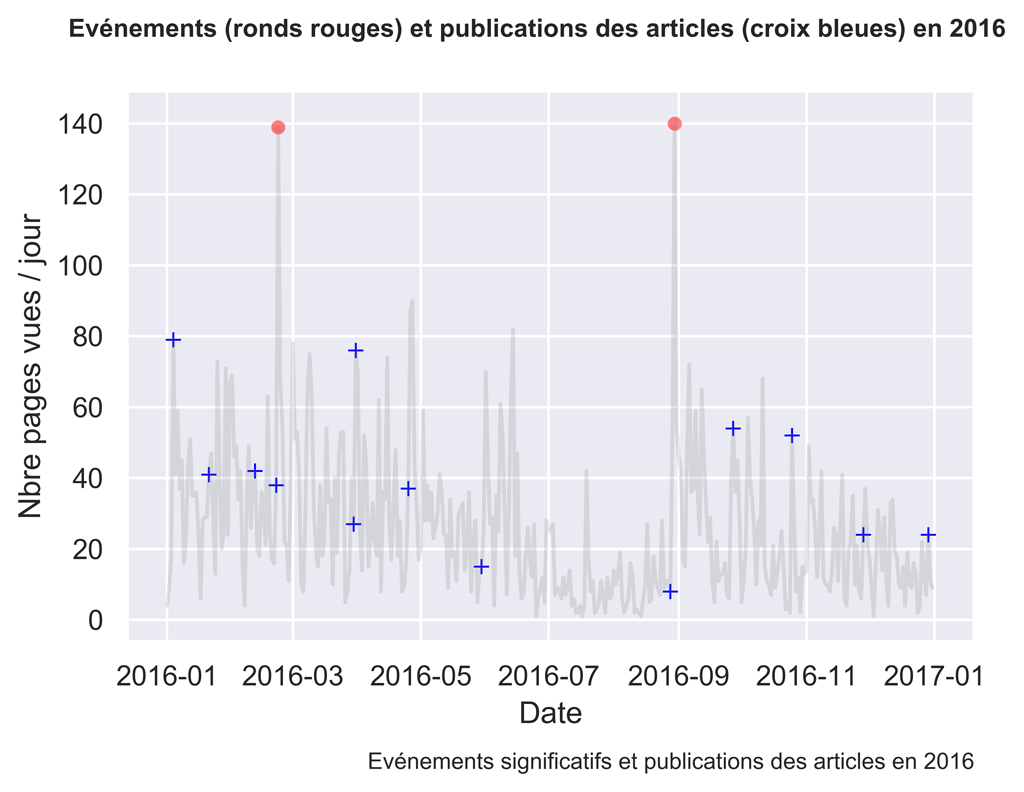
2017
2018
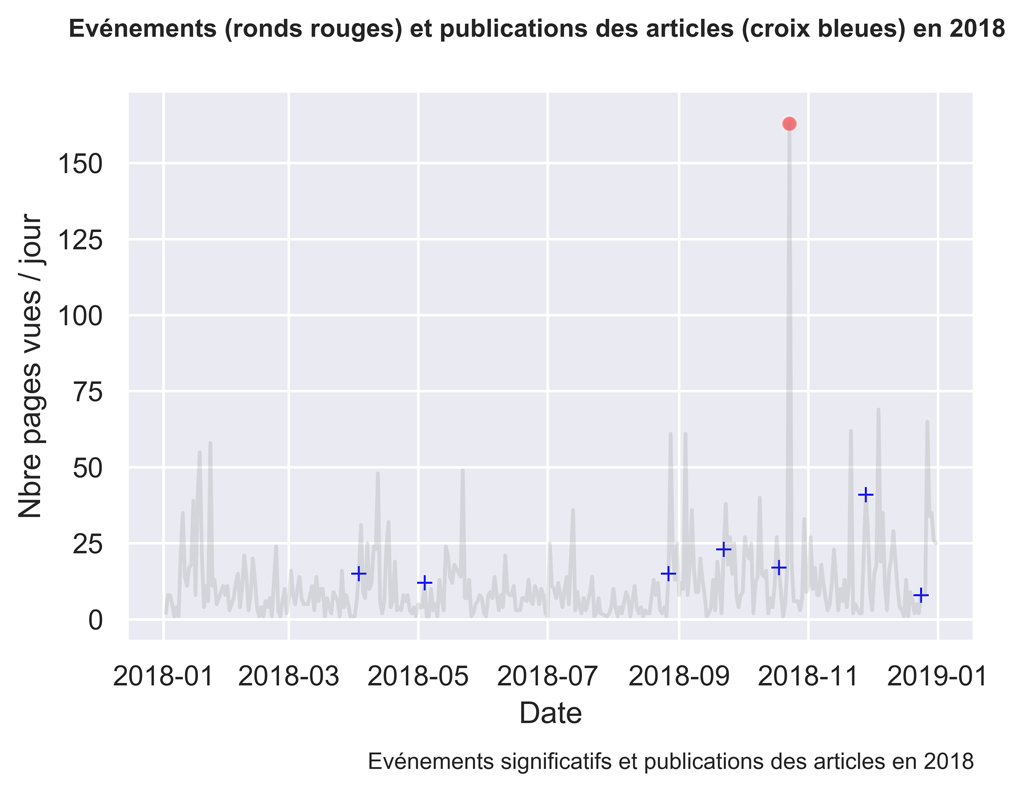
Comme vous pouvez le constater, parfois les actions sont suivies d’effets, parfois non.
Il serait intéressant d’investiguer ce qui fonctionne et ce qui ne fonctionne pas en analysant plus finement le trafic aux dates voulues.
Toutefois, de notre côté, nous allons nous intéresser à un autre sujet dans un prochain article : Quel est la « durée de vie » moyenne de mes articles.
Avis et suggestions bienvenues en commentaires.
A Bientôt,
Pierre