Partager la publication "Le Marketing de contenu amène-t-il du trafic sur mon site Web ? Logiciel R"
Et voilà la question à 1 MD de $ que tout Web Marketeur et dans ce cas, tout rédacteur Web se pose : Est-ce que mon travail sert à quelque chose ?
Plus particulièrement, nous allons nous intéresser à la contribution au trafic d’un site Web, notamment en SEO, qu’apporte la création d’articles et la mise en œuvre d’actions Web Marketing connexes .
On entend par actions connexes des actions du type :
- distribution du contenu sur les réseaux sociaux
- récupération de liens entrants suite à la publication de l’article
- emailing pour annoncer l’article
- Eventuellement publicité Adwords, FaceBook, Instagram…
- ….
Avec la console Google Analytics
Une première approche pour répondre à notre question sur la contribution d’un article serait de le vérifier dans Google Analytics.
Rem : Comme dans d’autres articles précédents nous illustrerons notre propos avec des données issues du site de l’association Networking Morbihan.
Pour avoir une idée de la contribution d’un article sur une longue période, nous vous conseillons d’étudier un article ancien.
Dans notre cas, l’article « rentrée-2011 » a été publié le 1er septembre 2011. C’est l’un des premiers articles dont la date est certaine. Notre période d’étude va du 1 juillet 2011 au 31 décembre 2018 soit 7 ans 1/2.
Pour avoir une vue du trafic d’une seule page , allez sur Comportement -> Contenus du site -> Toutes les Pages, puis cliquez sur une page ou un article ancien qui vous intéresse.
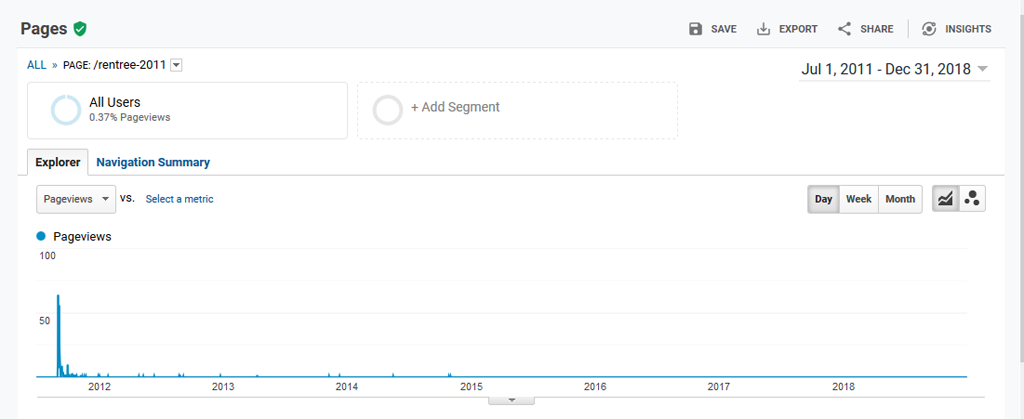
Comme on le voit sur le graphique, cet article a été vu essentiellement
au moment ou il a été publié. Il faut dire qu’il a bénéficié au moment de la
publication :
- D’une mise en évidence sur la page d’accueil du site.
- D’une communication via email.
- De la création d’un événement dans Viadéo.
- De la diffusion sur FaceBook.
- De la diffusion sur Twitter.
- De liens externes créés par les membres
- …
Notons toutefois, que l’on ne peut pas évaluer dans Google Analytics si le trafic supplémentaire constaté est significatif par rapport au trafic « normal ou de base » du site, ou au trafic attendu du site si nous n’avions pas publié l’article et les articles précédents.
Il n’est pas possible non plus de comparer plusieurs articles ou encore d’avoir une information synthétique sur tous les articles.
Avec R :
C’est pourquoi il est intéressant de travailler avec des outils et langages statistiques tiers comme R ou Python. Dans cet article nous traiterons le problème avec R.
La question précise que l’on va se poser ici est : « Est ce que, après avoir publié un article, j’obtiens des pics de trafic significatifs le jour même ou les jours suivants ? »
Pour avoir une idée de cela de façon visuelle, nous allons ajouter les dates de publications de nos articles à la courbe des pages vues et des événements significatifs réalisée précédemment :
De quoi aurons-nous besoin ?
Logiciel R
Bien que je l’ai indiqué partout précédemment je vous redonne l’information : afin de pouvoir tester le code source de cette démonstration nous vous invitons à télécharger Le Logiciel R sur ce site https://cran.r-project.org/, ainsi que l’environnement de développement RStudio ici : https://www.rstudio.com/products/rstudio/download/.
Jeu de données
Vous pouvez soit tester le code source avec nos données que vous pouvez récupérer ici en ce qui concerne les données de trafic récupérées de Google Analytics puis nettoyées. Et ici en ce qui concerne les dates des articles publiés sur notre site.
Soit, si vous souhaitez utiliser vos données, nous vous conseillons de suivre les étapes décrites dans les articles précédents suivants :
- googleanalyticsR : importation de vos données Google Analytics dans R
- Nettoyage du Spam dans Google Analytics avec R – Partie I
- Nettoyage du Spam dans Google Analytics avec R – Partie II
- Détection du trafic Web significatif avec R et AnomalyDetection
Code Source
Vous pouvez copier/coller les bouts de code dans les zones de code ou sinon tout télécharger gratuitement depuis notre boutique : https://www.anakeyn.com/boutique/produit/script-r-apport-de-trafic-par-marketing-de-contenu/
Récupération des données de pages vues :
Les données sont récupérées à partir du fichier dfPageViews.csv et mises en forme pour avoir un enregistrement par jour. Les « anomalies » i.e. les jours avec un trafic significativement important sont aussi repérées.
##########################################################################
# Auteur : Pierre Rouarch 2019
# Vérification que les actions Marketing menées sont en rapport avec le
# trafic significatif détecté.
# Pour illustrer notre propos nous utiliserons les données de
# l'association Networking-Morbihan
##########################################################################
#Packages et bibliothèques utiles (décommenter si besoin)
##########################################################################
#install.packages("lubridate") #si vous ne l'avez pas
#install.packages("tseries")
#install.packages("devtools")
#devtools::install_github("twitter/AnomalyDetection") #pour anomalyDetection de Twitter
#install.packages("XML")
#install.packages("stringi")
#install.packages("BSDA")
#install.packages("BBmisc")
#install.packages("stringi")
#install.packages("FactoMineR")
#install.packages("factoextra")
#install.packages("rcorr")
#install.packages("lubridate") #si vous ne l'avez pas
library (lubridate) #pour yday
#library(tseries) #pour ts
library(AnomalyDetection) #pour anomalydetectionVec
library(XML) # pour xmlParse
#library(stringi) #pour stri_replace_all_fixed(x, " ", "")
#library(BSDA) #pour SIGN.test
#library(BBmisc) #pour which.first
#install.packages("stringi")
library(stringi) #pour stri_detect
#library(ggfortify) #pour ploter autoplot type ggplot
#install.packages("tidyverse") #si vous ne l'avez pas #pour gggplot2, dplyr, tidyr, readr, purr, tibble, stringr, forcats
#install.packages("forecast") #pour ma
#Chargement des bibliothèques utiles
library(tidyverse) #pour gggplot2, dplyr, tidyr, readr, purr, tibble, stringr, forcats
library(forecast) #pour arima, ma, tsclean
##########################################################################
# Récupération du Jeu de données nettoyé
##########################################################################
dfPageViews <- read.csv("dfPageViews.csv", header=TRUE, sep=";")
#str(dfPageViews) #verif
dfPageViews$date <- as.Date(dfPageViews$date,format="%Y-%m-%d")
#str(dfPageViews) #verif
#Données par jour
dfDatePV <- as.data.frame(dfPageViews$date)
colnames(dfDatePV)[1] <- "date"
daily_data <- dfDatePV %>% #daily_data à partir de dfDatePV
group_by(date) %>% #groupement par date
mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date
as.data.frame() %>% #sur d'avoir une data.frame
unique() %>% #ligne unique par jour.
mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours)
mutate(year = format(date,"%Y")) %>% #creation de la variable year
mutate(dayOfYear = yday(date)) #creation de la variable dayOfYear
#Sauvegarde de daily_data au besoin
#str(daily_data) #verif
write.csv2(daily_data, file = "DailyDataClean.csv", row.names=FALSE) #sauvegarde en csv avec ;
##########################################################################
# Détections des événements significatifs - Anomaly Detection
##########################################################################
#help(AnomalyDetectionVec) #pour voir la doc
#recherche des anomalies sur la variable Pageviews
res <- AnomalyDetectionVec(daily_data[,2], max_anoms=0.05,
direction='both', alpha=0.05, plot=FALSE, period=30)
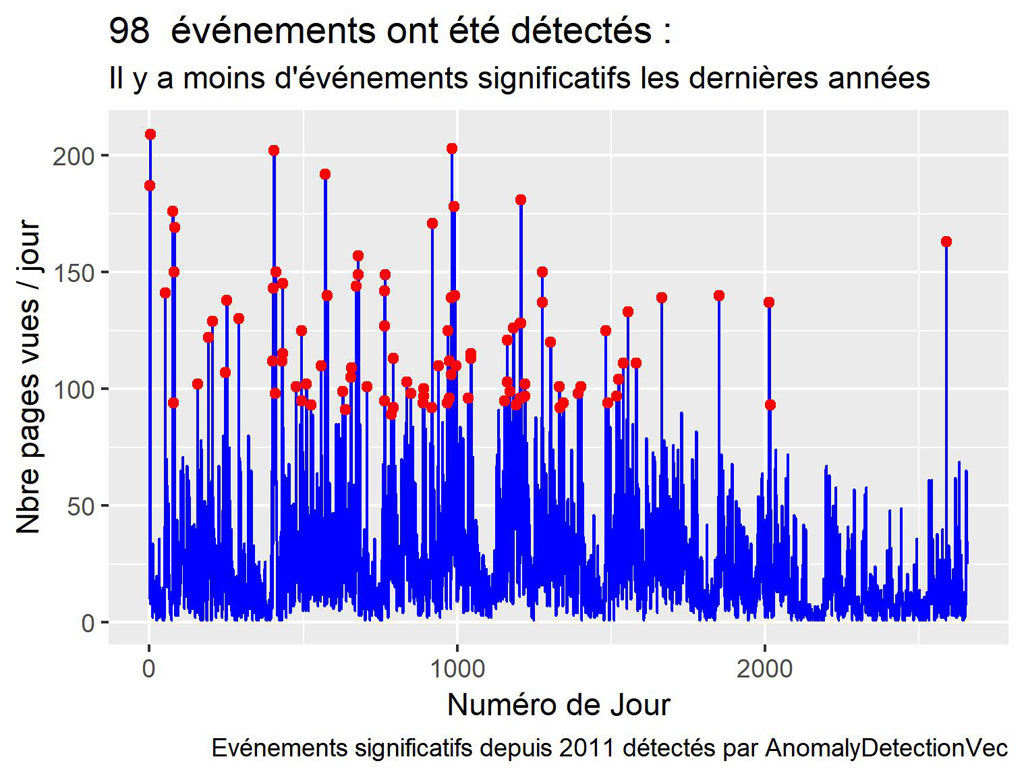
nrow(res$anoms) #98
daily_data$index <- as.integer(as.character(rownames(daily_data))) #pour etre raccord avec res$anoms.
#il faut que l'on récupère cnt_ma30 de daily_data pour afficher les anomalies sur la courbe
myAnoms <- left_join(res$anoms, daily_data, by="index")
#Minimum de pages vues pour un événement significatif depuis 2011.
min(myAnoms$Pageviews)
#89
Récupération des articles :
En fait, ce qui nous intéresse est de récupérer la date de publication de tous les articles publiés qui nous intéressent.
Si vous utilisez un CMS (Content Management System), vous devez pouvoir faire cela assez facilement.
Dans notre cas, nous utilisons WordPress. WordPress dispose d’un outil d’export qui permet de récupérer des fichiers .xml d’articles.
Un petit bémol toutefois : l’outil d’export ne permet pas de sélectionner les catégories d’articles qui nous intéressent en une seule fois. Nous seront donc obligés de faire plusieurs exports et de récupérer des données dans 6 fichiers .xml.
Comme on l’a vu précédemment vous pouvez récupérer les 6 fichiers .xml sur notre github : https://github.com/Anakeyn/ArticlesPubDateVSSignTrafficR/raw/master/WP.articles.zip
Dézipper l’archive et placez les fichiers dans le répertoire de votre programme R.
################################################################################
# Récupération des Articles par categories. Les catégories qui nous intéressent
# sont celles pour lesquelles les administrateurs ont créé des articles qu'ils
# souhaitaient mettre en avant :
# "A la une",
# "Actualités",
# "Les Autres Rendez-vous",
# "Networking Apéro",
# "Networking Conseil"
# "Networking Cotravail",
# L'export de WordPress ne permet pas d'exporter un choix de catégories, on est
# obligé de faire catégorie par catégorie
################################################################################
#Categorie A La une
xmlNW56Articles <- xmlParse("NW56.WP.ALaUne.xml")
links <- setNames(xmlToDataFrame(nodes = getNodeSet(xmlNW56Articles, "//item//link"), stringsAsFactors = FALSE), "link")
pubDates <- setNames(xmlToDataFrame(nodes=getNodeSet(xmlNW56Articles, "//item//pubDate"), stringsAsFactors = FALSE), "pubDate")
dfNW56AlaUne <- cbind(pubDates, links)
#Categorie "Actualités",
xmlNW56Articles <- xmlParse("NW56.WP.Actualites.xml")
links <- setNames(xmlToDataFrame(nodes = getNodeSet(xmlNW56Articles, "//item//link"), stringsAsFactors = FALSE), "link")
pubDates <- setNames(xmlToDataFrame(nodes=getNodeSet(xmlNW56Articles, "//item//pubDate"), stringsAsFactors = FALSE), "pubDate")
dfNW56Actualites <- cbind(pubDates, links)
#Categorie ""Les Autres Rendez-vous",
xmlNW56Articles <- xmlParse("NW56.WP.LesAutresRDV.xml")
links <- setNames(xmlToDataFrame(nodes = getNodeSet(xmlNW56Articles, "//item//link"), stringsAsFactors = FALSE), "link")
pubDates <- setNames(xmlToDataFrame(nodes=getNodeSet(xmlNW56Articles, "//item//pubDate"), stringsAsFactors = FALSE), "pubDate")
dfNW56LesAutresRDV <- cbind(pubDates, links)
#Categorie "Networking Apéro",
xmlNW56Articles <- xmlParse("NW56.WP.NetworkingApero.xml")
links <- setNames(xmlToDataFrame(nodes = getNodeSet(xmlNW56Articles, "//item//link"), stringsAsFactors = FALSE), "link")
pubDates <- setNames(xmlToDataFrame(nodes=getNodeSet(xmlNW56Articles, "//item//pubDate"), stringsAsFactors = FALSE), "pubDate")
dfNW56NetworkingApero <- cbind(pubDates, links)
#Categorie "Networking Conseil",
xmlNW56Articles <- xmlParse("NW56.WP.NetworkingConseil.xml")
links <- setNames(xmlToDataFrame(nodes = getNodeSet(xmlNW56Articles, "//item//link"), stringsAsFactors = FALSE), "link")
pubDates <- setNames(xmlToDataFrame(nodes=getNodeSet(xmlNW56Articles, "//item//pubDate"), stringsAsFactors = FALSE), "pubDate")
dfNW56NetworkingConseil <- cbind(pubDates, links)
#Categorie "Networking Cotravail",
xmlNW56Articles <- xmlParse("NW56.WP.NetworkingCotravail.xml")
links <- setNames(xmlToDataFrame(nodes = getNodeSet(xmlNW56Articles, "//item//link"), stringsAsFactors = FALSE), "link")
pubDates <- setNames(xmlToDataFrame(nodes=getNodeSet(xmlNW56Articles, "//item//pubDate"), stringsAsFactors = FALSE), "pubDate")
dfNW56NetworkingCotravail <- cbind(pubDates, links)
#Groupement de toutes les catégories
dfNW56Articles <- rbind(dfNW56AlaUne, dfNW56Actualites, dfNW56LesAutresRDV,
dfNW56NetworkingApero,dfNW56NetworkingConseil, dfNW56NetworkingCotravail )
#verif
nrow(dfNW56Articles)
dfNW56Articles <- unique(dfNW56Articles) #pour éviter les pages dans plusieurs catégories
nrow(dfNW56Articles) #verif - 104 Articles
str(dfNW56Articles) #pb : les dates sont dans un format anglophone et en chaines de caractères
#et non pas dans un format standard universel du genre "2017-10-19" ou en datetime
Problème de date :
Nous avons besoin de la date pour merger le jeu de données des articles avec les dates et le jeu de données du trafic journalier.
Le problème est que la date dans les articles est sous la forme anglophone « Tue, 04 Nov 2014 12:23:53 +0000 » et en chaîne de caractère, et ne peut pas être décodée si votre ordinateur est en « locale » France.
On va devoir passer en anglais le temps du décodage.
##############################################################################
#transformation de pubDate en une date exploitable
#Attention si vous êtes déjà en anglais commenter cette ligne
Sys.getlocale()
#Attention si vous êtes déjà en anglais commenter cette ligne :
#on passe en anglais
Sys.setlocale("LC_ALL","English") #pour pouvoir traduire les dates
#Mon, 20 Jun 2011 13:18:18 +0000
dfNW56Articles$dateString <- as.character(as.Date(substr(dfNW56Articles$pubDate, 1, 16), format = "%a, %d %b %Y"))
#Attention si vous souhaitez rester en anglais commenter cette ligne :
Sys.setlocale("LC_ALL","French") #pour revenir en français
Merge des articles et des données de trafic dans myArticle
######## mettre aussi une DateString aussi dans daily_data pour faire le join #############
daily_data$dateString <- as.character(daily_data$date)
myArticles <- inner_join(dfNW56Articles, daily_data, by="dateString")
myArticles <- myArticles[order(myArticles$index),]
#Verifs
str(myArticles) #95
#View(myArticles)
#Si besoin
write.csv2(myArticles, file = "myArticles.csv", row.names=FALSE)
#Date et/ou numéro de jour devrait suffire
myArticlesDate <- myArticles[,c("date","index")]
#Eventuellement
colnames(myArticlesDate) <-c("date","NumDay")
write.csv2(myArticlesDate, file = "myArticlesDate.csv", row.names=FALSE)
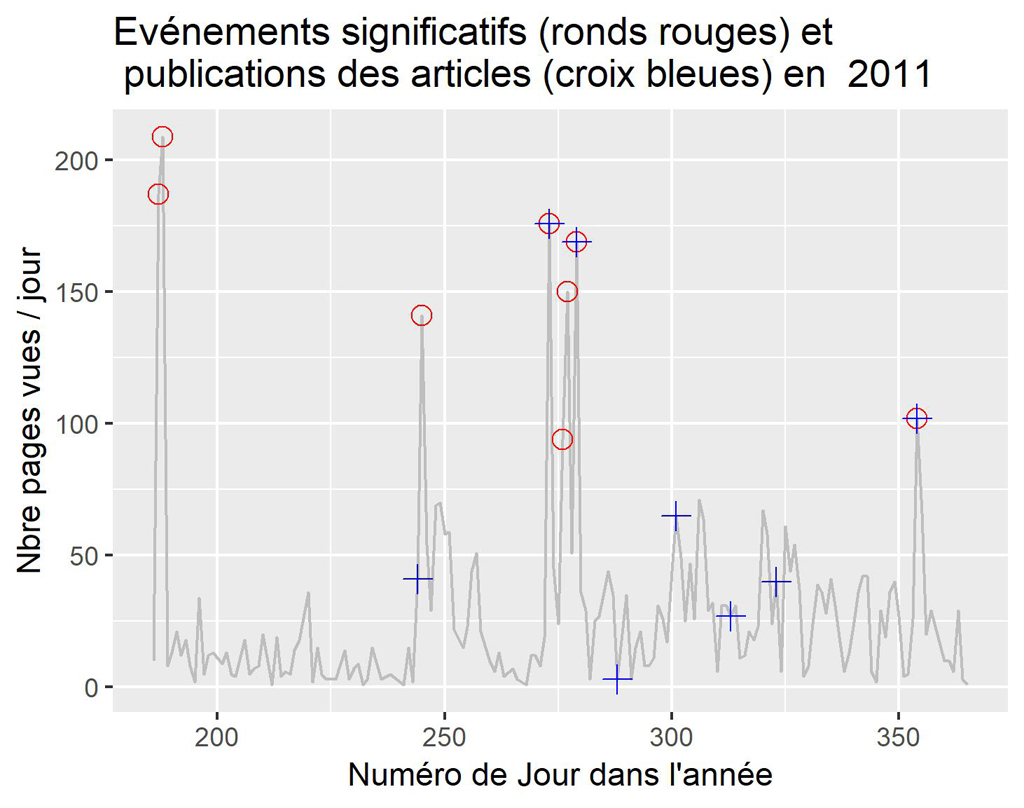
Graphique des événements vs date de publication depuis 2011.
Sur ce graphique on compare les événement significatifs détectés (voir article précédent) aux dates de publications des articles.
##########################################################################
# Graphiques des anomalies (événements) et dates de publication
##########################################################################
#sur toute la période
ggplot() +
geom_line(data=daily_data, aes(index, Pageviews), color='grey') +
geom_point(data=res$anoms , aes(index, anoms), color='red') +
geom_point(data=myArticles , aes(index, Pageviews), color='blue', shape = 3, size=3) +
xlab("Numéro de Jour") +
ylab("Nbre pages vues / jour") +
labs(title = paste(nrow(res$anoms),"événements (ronds rouges) pour", nrow(myArticles),"articles (croix bleues) : "),
subtitle = "Les articles des dernières années ne semblent pas suivis d'effets",
caption = "Evénements significatifs et publications des articles depuis 2011")
#sauvegarde du dernier ggplot :
ggsave(filename = "Events-Articles-s2011.jpeg", dpi="print")
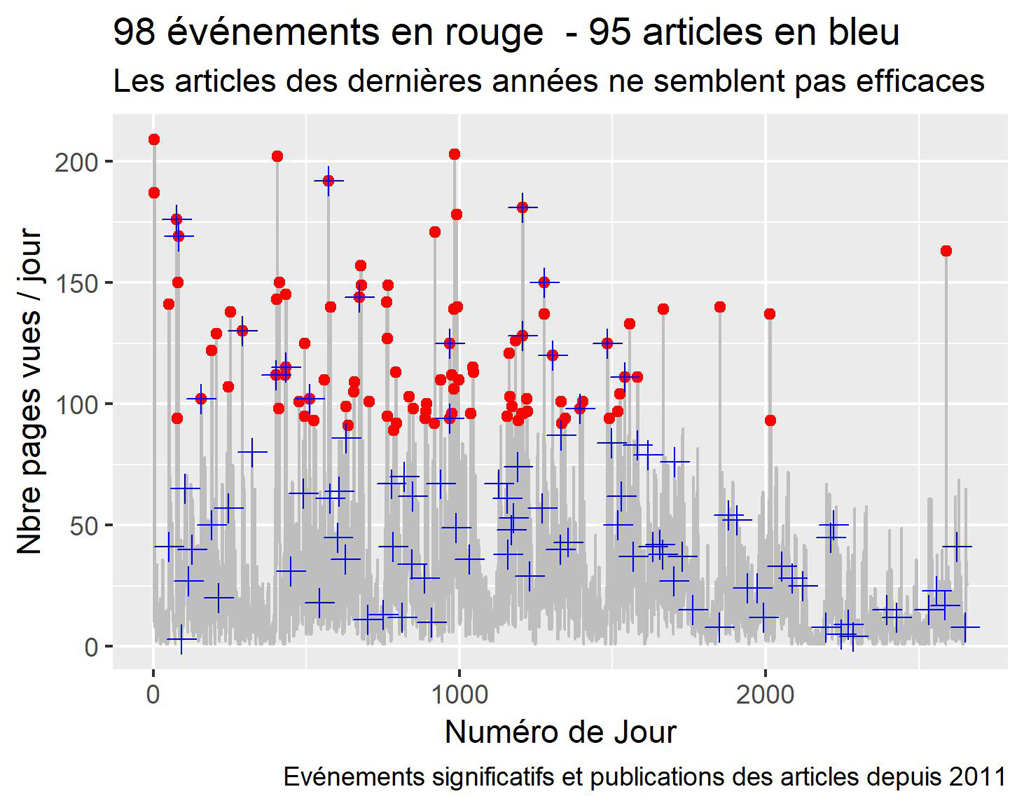
Comme on le voit sur la courbe, vers les années 2017 2018 (numéros de jours importants) les actions ne sont plus très efficaces. Pour les autres périodes, ce n’est pas très lisible. C’est pourquoi nous allons diviser le graphique par années.
Graphiques par années
##########################################################################
# Graphiques des événements et dates de publication par années
##########################################################################
#Affichage pour 2011
myYear = "2011"
ggplot() +
geom_line(data=daily_data[which(daily_data$year == myYear), ] , aes(dayOfYear, Pageviews), color='grey') +
geom_point(data=myAnoms[which(myAnoms$year == myYear), ] , aes(dayOfYear, anoms), color='red', shape=1, size=3 ) +
geom_point(data=myArticles[which(myArticles$year == myYear),] , aes(dayOfYear, Pageviews), color='blue',shape = 3, size=3) +
xlab("Numéro de Jour dans l'année") +
ylab("Nbre pages vues / jour") +
ggtitle(label = paste("Evénements significatifs (ronds rouges) et \n publications des articles (croix bleues) en ", myYear))
ggsave(filename = stri_replace_all_fixed(paste("Events-Articles-",myYear,".jpeg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot.
#Affichage pour 2012
myYear = "2012"
ggplot() +
geom_line(data=daily_data[which(daily_data$year == myYear), ] , aes(dayOfYear, Pageviews), color='grey') +
geom_point(data=myAnoms[which(myAnoms$year == myYear), ] , aes(dayOfYear, anoms), color='red', shape=1, size=3 ) +
geom_point(data=myArticles[which(myArticles$year == myYear),] , aes(dayOfYear, Pageviews), color='blue',shape = 3, size=3) +
xlab("Numéro de Jour dans l'année") +
ylab("Nbre pages vues / jour") +
ggtitle(label = paste("Evénements significatifs (ronds rouges) et \n publications des articles (croix bleues) en ", myYear))
ggsave(filename = stri_replace_all_fixed(paste("Events-Articles-",myYear,".jpeg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot.
#Affichage pour 2013
myYear = "2013"
ggplot() +
geom_line(data=daily_data[which(daily_data$year == myYear), ] , aes(dayOfYear, Pageviews), color='grey') +
geom_point(data=myAnoms[which(myAnoms$year == myYear), ] , aes(dayOfYear, anoms), color='red', shape=1, size=3 ) +
geom_point(data=myArticles[which(myArticles$year == myYear),] , aes(dayOfYear, Pageviews), color='blue',shape = 3, size=3) +
xlab("Numéro de Jour dans l'année") +
ylab("Nbre pages vues / jour") +
ggtitle(label = paste("Evénements significatifs (ronds rouges) et \n publications des articles (croix bleues) en ", myYear))
ggsave(filename = stri_replace_all_fixed(paste("Events-Articles-",myYear,".jpeg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot.
#Affichage pour 2014
myYear = "2014"
ggplot() +
geom_line(data=daily_data[which(daily_data$year == myYear), ] , aes(dayOfYear, Pageviews), color='grey') +
geom_point(data=myAnoms[which(myAnoms$year == myYear), ] , aes(dayOfYear, anoms), color='red', shape=1, size=3 ) +
geom_point(data=myArticles[which(myArticles$year == myYear),] , aes(dayOfYear, Pageviews), color='blue',shape = 3, size=3) +
ggtitle(label = paste("Evénements significatifs et publications des articles en ", myYear))
xlab("Numéro de Jour dans l'année") +
ylab("Nbre pages vues / jour") +
ggtitle(label = paste("Evénements significatifs (ronds rouges) et \n publications des articles (croix bleues) en ", myYear))
#Affichage pour 2015
myYear = "2015"
ggplot() +
geom_line(data=daily_data[which(daily_data$year == myYear), ] , aes(dayOfYear, Pageviews), color='grey') +
geom_point(data=myAnoms[which(myAnoms$year == myYear), ] , aes(dayOfYear, anoms), color='red', shape=1, size=3 ) +
geom_point(data=myArticles[which(myArticles$year == myYear),] , aes(dayOfYear, Pageviews), color='blue',shape = 3, size=3) +
xlab("Numéro de Jour dans l'année") +
ylab("Nbre pages vues / jour") +
ggtitle(label = paste("Evénements significatifs (ronds rouges) et \n publications des articles (croix bleues) en ", myYear))
ggsave(filename = stri_replace_all_fixed(paste("Events-Articles-",myYear,".jpeg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot.
#Affichage pour 2016
myYear = "2016"
ggplot() +
geom_line(data=daily_data[which(daily_data$year == myYear), ] , aes(dayOfYear, Pageviews), color='grey') +
geom_point(data=myAnoms[which(myAnoms$year == myYear), ] , aes(dayOfYear, anoms), color='red', shape=1, size=3 ) +
geom_point(data=myArticles[which(myArticles$year == myYear),] , aes(dayOfYear, Pageviews), color='blue',shape = 3, size=3) +
xlab("Numéro de Jour dans l'année") +
ylab("Nbre pages vues / jour") +
ggtitle(label = paste("Evénements significatifs (ronds rouges) et \n publications des articles (croix bleues) en ", myYear))
ggsave(filename = stri_replace_all_fixed(paste("Events-Articles-",myYear,".jpeg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot.
#Affichage pour 2017
myYear = "2017"
ggplot() +
geom_line(data=daily_data[which(daily_data$year == myYear), ] , aes(dayOfYear, Pageviews), color='grey') +
geom_point(data=myAnoms[which(myAnoms$year == myYear), ] , aes(dayOfYear, anoms), color='red', shape=1, size=3 ) +
geom_point(data=myArticles[which(myArticles$year == myYear),] , aes(dayOfYear, Pageviews), color='blue',shape = 3, size=3) +
xlab("Numéro de Jour dans l'année") +
ylab("Nbre pages vues / jour") +
ggtitle(label = paste("Evénements significatifs (ronds rouges) et \n publications des articles (croix bleues) en ", myYear))
ggsave(filename = stri_replace_all_fixed(paste("Events-Articles-",myYear,".jpeg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot.
#Affichage pour 2018
myYear = "2018"
ggplot() +
geom_line(data=daily_data[which(daily_data$year == myYear), ] , aes(dayOfYear, Pageviews), color='grey') +
geom_point(data=myAnoms[which(myAnoms$year == myYear), ] , aes(dayOfYear, anoms), color='red', shape=1, size=3 ) +
geom_point(data=myArticles[which(myArticles$year == myYear),] , aes(dayOfYear, Pageviews), color='blue',shape = 3, size=3) +
xlab("Numéro de Jour dans l'année") +
ylab("Nbre pages vues / jour") +
ggtitle(label = paste("Evénements significatifs (ronds rouges) et \n publications des articles (croix bleues) en ", myYear))
ggsave(filename = stri_replace_all_fixed(paste("Events-Articles-",myYear,".jpeg"), " ", ""), dpi="print") #sauvegarde du dernier ggplot.
##########################################################################
# MERCI pour votre attention !
##########################################################################
Pour 2011 (à partir de juillet)
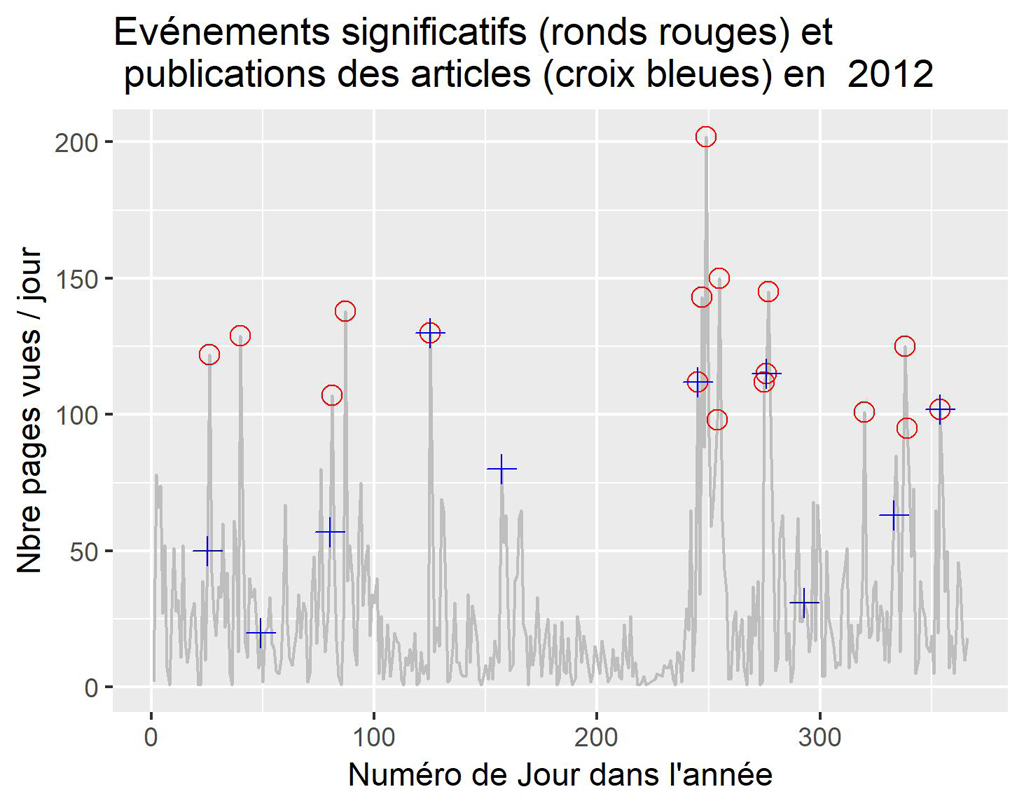
Pour 2012
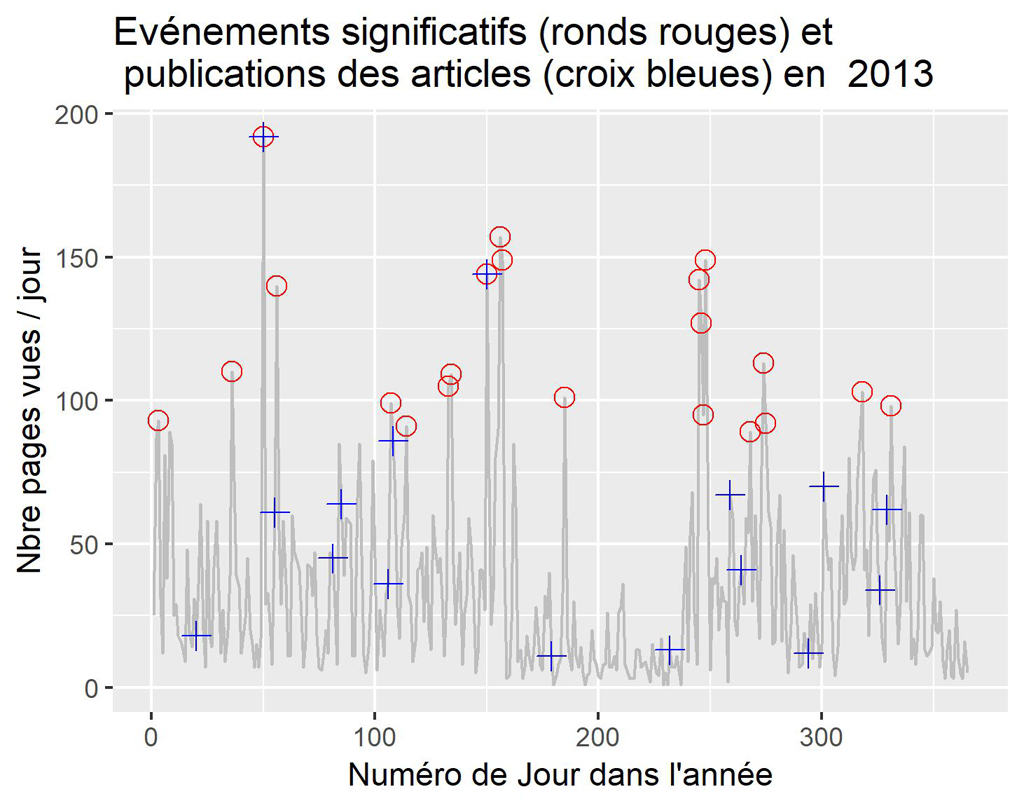
Pour 2013
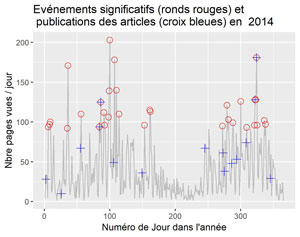
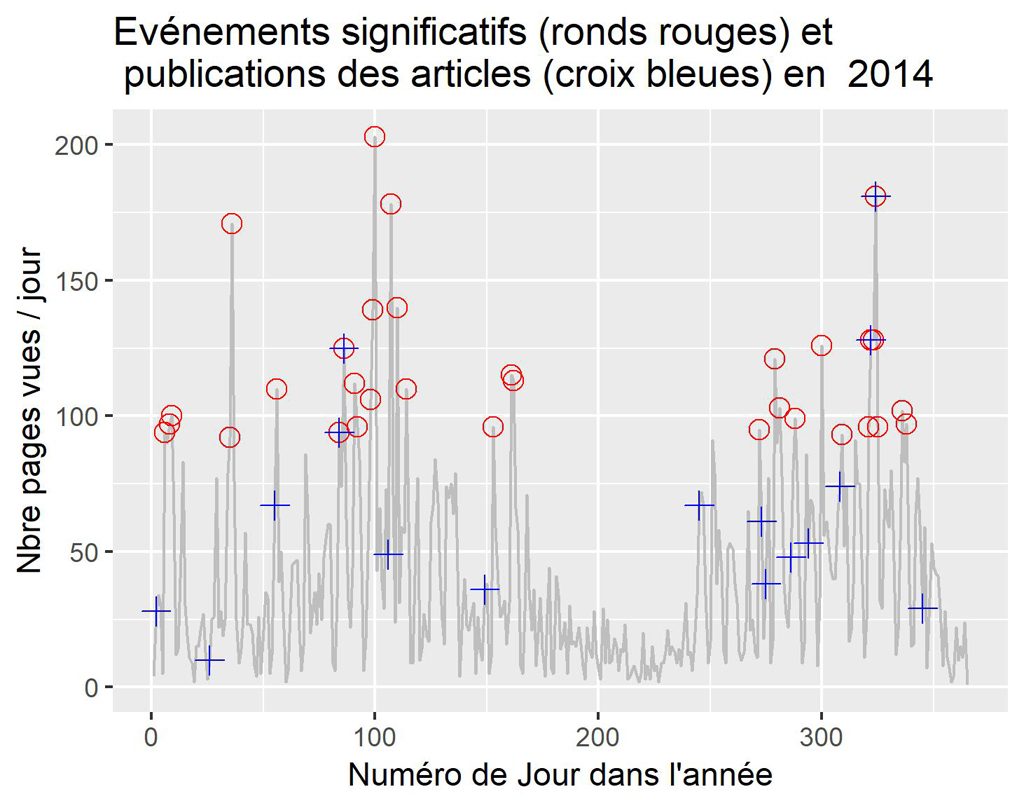
Pour 2014
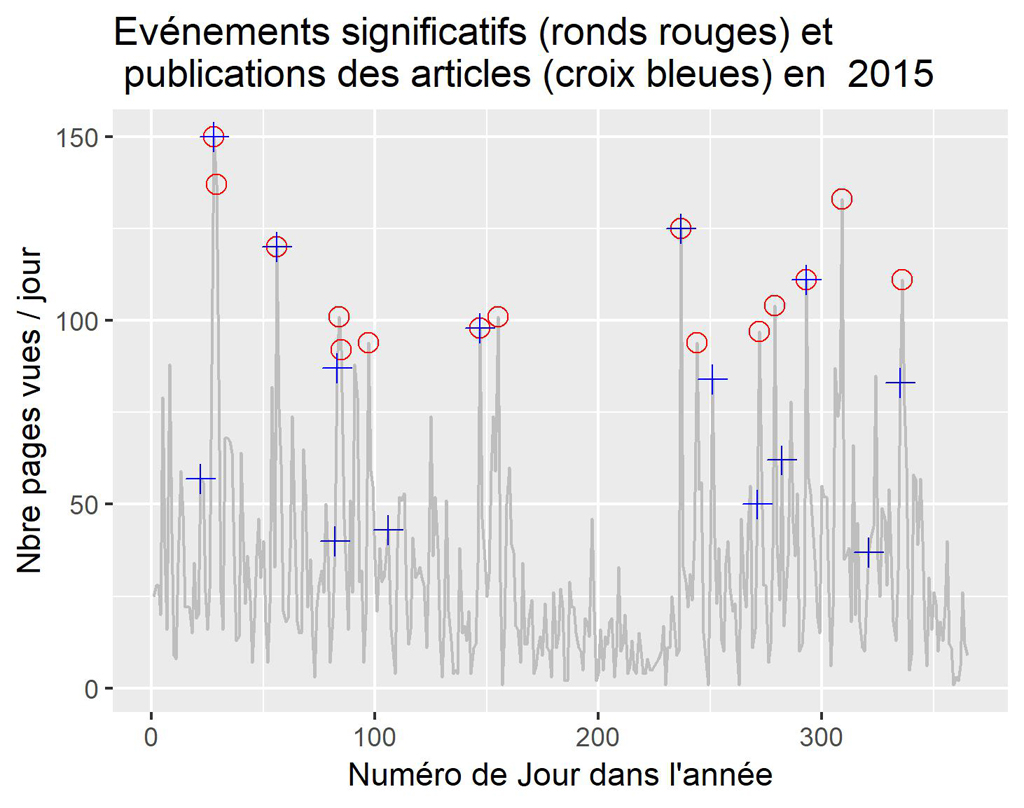
PoUR 2015
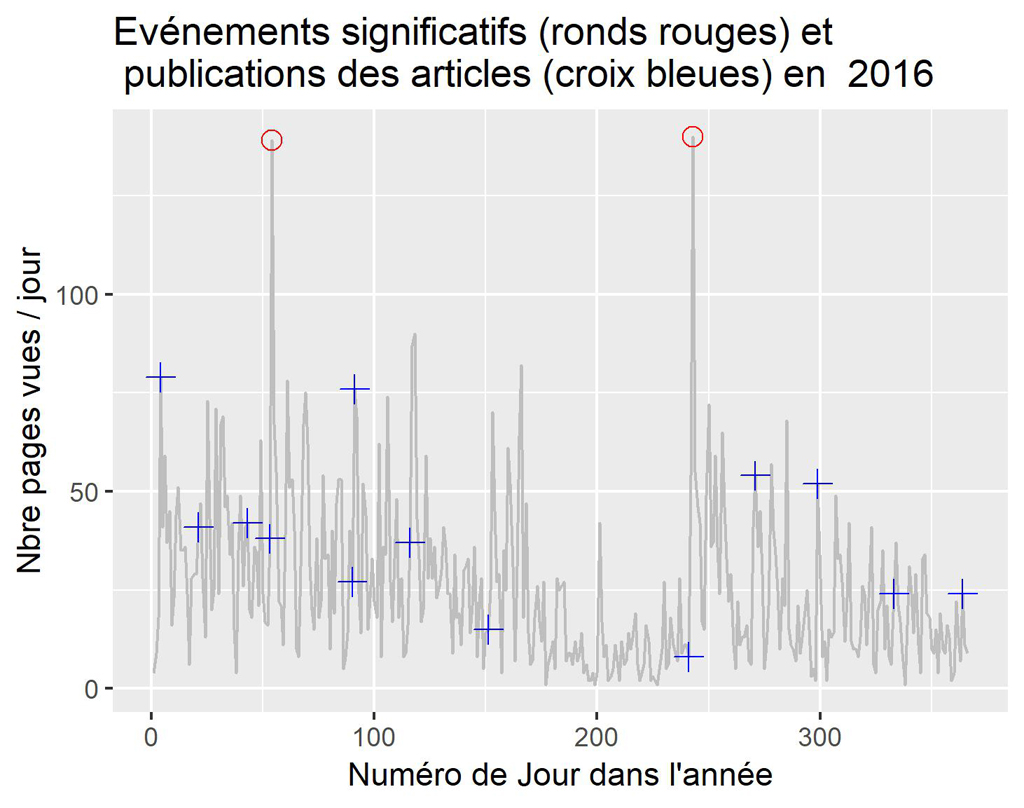
Pour 2016
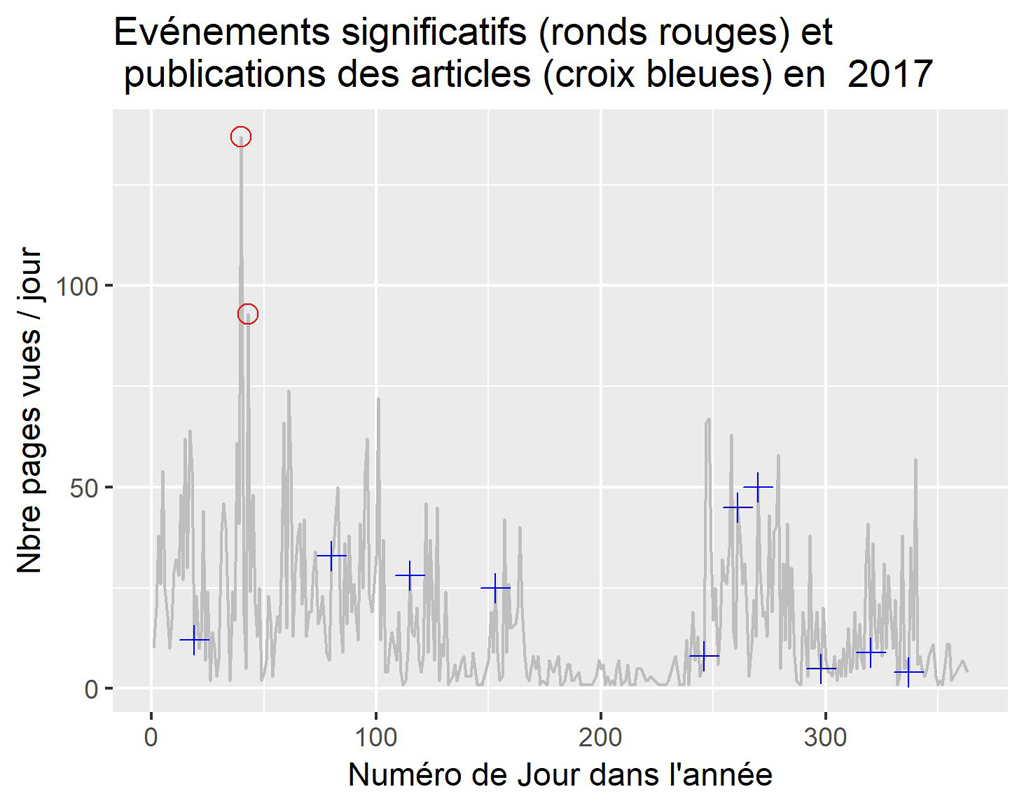
Pour 2017
Pour 2018
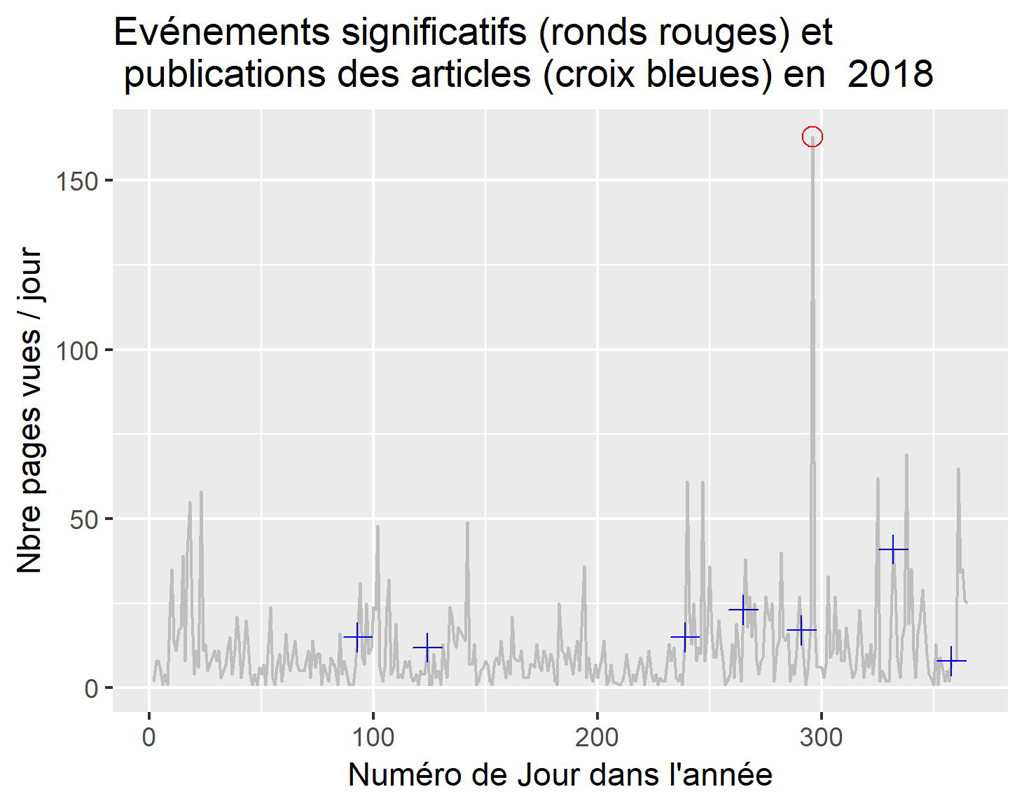
La visualisation par années confirme ce que l’on constatait sur le graphique global. Il semble que parfois la publication soit suivie d’effets, parfois non. Ceci nécessiterait une étude plus approfondie des différents cas.
Dans un prochain article nous nous intéresserons plutôt à la « durée de vie » des articles sur un site Web.
Merci pour vos témoignages et suggestions en commentaires
A bientôt,
Pierre