

Partager la publication "Nettoyage du Spam dans Google Analytics avec R – Partie II"
Cet article est la suite de l’article Nettoyage du Spam dans Google Analytics avec R – Partie I
Le nettoyage à proprement parlé commence ici !
Code Source R :
Vous pouvez copier/coller les codes sources suivants pour les tester dans votre propre fichier de script R.
Vous pouvez aussi télécharger gratuitement les sources et les fichiers nécessaires dans notre boutique : https://www.anakeyn.com/boutique/produit/script-r-nettoyage-spam-dans-google-analytics/
Nettoyage des langues suspectes.
Nous allons vérifier que les langues sont bien sous la forme « langue-pays » : xxx-xxx, par exemple : fr-FR, fr-BE, es … pour cela on utilise une expression régulière ici : « ^[a-zA-Z]{2,3}([-/][a-zA-Z]{2,3})?$ ».
Nous préparons aussi les données pour affichage.
##########################################################################
#Nettoyage des langues suspectes.
##########################################################################
indexGoodlang <- grep(pattern = "^[a-zA-Z]{2,3}([-/][a-zA-Z]{2,3})?$", gaPVAllYears$language)
gaPVAllYearsCleanLanguage <- gaPVAllYears[indexGoodlang,]
nrow(gaPVAllYearsCleanLanguage) #on supprime environ 6000 lignes
#nombre de ligne 76733
#verifs
head(gaPVAllYearsCleanLanguage, n=20) #verif
summary(gaPVAllYearsCleanLanguage)
dim(gaPVAllYearsCleanLanguage)
class(gaPVAllYearsCleanLanguage$date)
#creation de la dataframe daily_data par jour
dfDatePV <- as.data.frame(gaPVAllYearsCleanLanguage$date)
colnames(dfDatePV)[1] <- "date" #change le nom de la colonne.
daily_data <- dfDatePV %>% #daily_data à partir de dfDatePV
group_by(date) %>% #groupement par date
mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date
as.data.frame() %>% #sur d'avoir une data.frame
unique() %>% #ligne unique par jour.
mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours)
mutate(year = format(date,"%Y")) #creation de la variable year
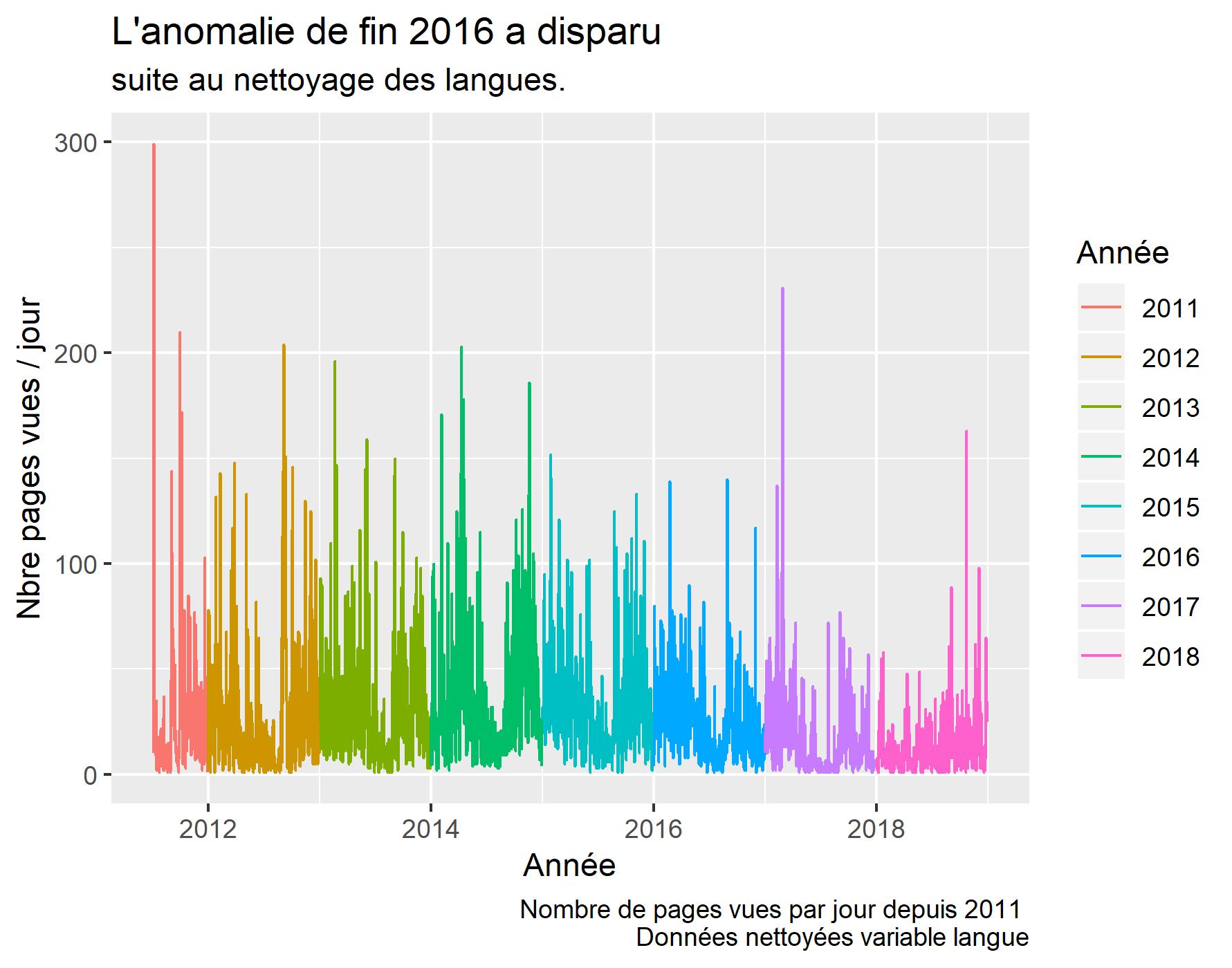
Il reste 76733 observations, on en a supprimées environ 6000 !
Visualisation après nettoyAGE des Langues Suspectes
#Graphique pages vues par jour
ggplot(daily_data , aes(x=date, y=Pageviews, color=year)) +
geom_line() +
xlab("Année") +
ylab("Nbre pages vues / jour") +
labs(title = "L'anomalie de fin 2016 a disparu ",
subtitle = "suite au nettoyage des langues.",
caption = "Nombre de pages vues par jour depuis 2011 \n Données nettoyées variable langue",
color = "Année")
#sauvegarde du dernier ggplot
ggsave(filename = "PV-s2011-Clean-Lang.jpeg", dpi="print") #sauvegarde du dernier ggplot.
Nettoyage des Ghostames
Il s’agit de sites qui ont placé notre code de suivi Google Analytics sur leur propres pages … On va faire en sorte de ne garder que les sites légitimes. Par ailleurs s’il existe des sous domaines que l’on ne souhaite pas garder il faudra aussi les traiter.
##########################################################################
#nettoyage des hostnames non légitimes (Ghostnames)
##########################################################################
#Pour faciliter la lecture on va créer un vecteur de pattern des sites
#légitimes : nos sites et les sites de cache comme par exemple webcache.googleusercontent.com
#ou web.archive.org
#on garde ceux qui nous intéressent.
# remarque adpatez le nom de votre site en remplacment de networking-morbihan.
patternGoodHostname <- c("networking-morbihan\\.com", "translate\\.googleusercontent\\.com",
"webcache\\.googleusercontent\\.com",
"networking-morbihan\\.com\\.googleweblight\\.com",
"web\\.archive\\.org")
indexGoodHostname <- grep(pattern = paste(patternGoodHostname, collapse="|"), gaPVAllYearsCleanLanguage$hostname)
gaPVAllYearsCleanHost <- gaPVAllYearsCleanLanguage[indexGoodHostname,]
#Verifs.
nrow(gaPVAllYearsCleanHost) #76170 #~560 lignes supprimmées
summary(gaPVAllYearsCleanHost$hostname) #verif
#on vire un mauvais sous domaine qui restait
patternBadHostname = "loc\\.networking-morbihan\\.com"
indexBadHostname <- -grep(pattern = patternBadHostname, gaPVAllYearsCleanHost$hostname)
gaPVAllYearsCleanHost <- gaPVAllYearsCleanHost[indexBadHostname,]
nrow(gaPVAllYearsCleanHost) #76159 #nombre de lignes nettoyées 11
#creation de la dataframe daily_data par jour
dfDatePV <- as.data.frame(gaPVAllYearsCleanHost$date)
colnames(dfDatePV)[1] <- "date" #change le nom de la colonne.
daily_data <- dfDatePV %>% #daily_data à partir de dfDatePV
group_by(date) %>% #groupement par date
mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date
as.data.frame() %>% #sur d'avoir une data.frame
unique() %>% #ligne unique par jour.
mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours)
mutate(year = format(date,"%Y")) #creation de la variable year
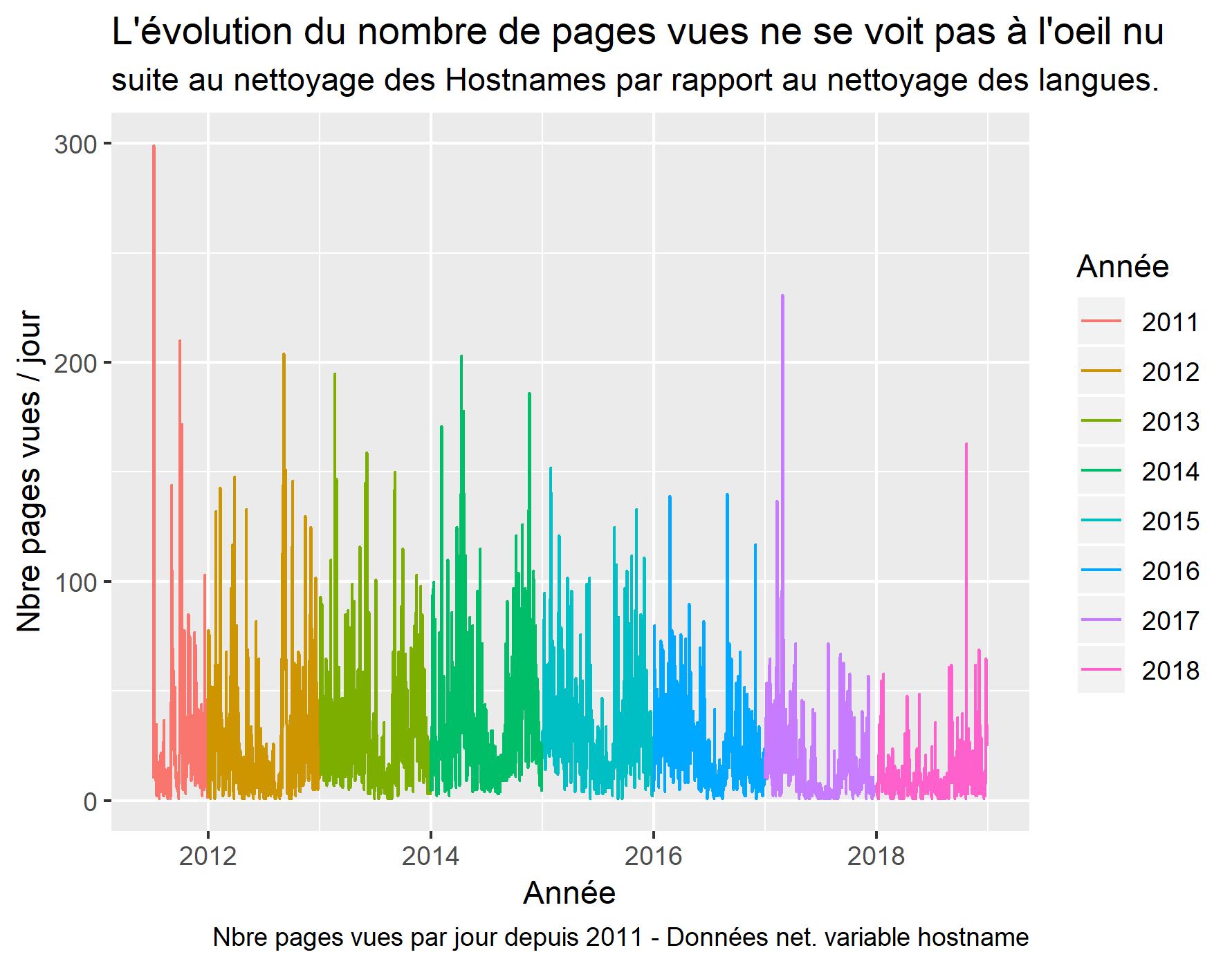
Il reste maintenant 76159 observations après cette action. Environ 570 suppressions.
Visualisation après nettoyage des GHOSTNAMES
#Graphique pages vues par jour
ggplot(daily_data , aes(x=date, y=Pageviews, color=year)) +
geom_line() +
xlab("Année") +
ylab("Nbre pages vues / jour") +
labs(title = "L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ",
subtitle = "suite au nettoyage des Hostnames par rapport au nettoyage des langues.",
caption = "Nbre pages vues par jour depuis 2011 - Données net. variable hostname",
color = "Année")
ggsave(filename = "PV-s2011-Clean-Host.jpeg", dpi="print") #sauvegarde du dernier ggplot.
Nettoyage des browsers suspects
Avant de créer et de personnaliser la pattern de nettoyage des browsers, il est nécessaire de vérifier le contenu de la variable « browser ».
##########################################################################
#nettoyage des browsers suspects - peut contenir des robots crawlers
##########################################################################
#voyons ce qu'il y a dedans
unique(gaPVAllYearsCleanHost$browser)
plyr::count(as.factor(gaPVAllYearsCleanHost$browser))
#on vire les "curiosités et les bots (cela peut varier selon vos le contenu que vous trouver dans browser)
patternBadBrowser <- c("not set","Google\\.com", "en-us",
"GOOG", "PagePeeker\\.com",
"bot")
indexBadBrowser <- -grep(pattern = paste(patternBadBrowser, collapse="|"), gaPVAllYearsCleanHost$browser)
gaPVAllYearsCleanBrowser <- gaPVAllYearsCleanHost[indexBadBrowser,]
#Verifs
head(gaPVAllYearsCleanBrowser, n=20) #verif
nrow(gaPVAllYearsCleanBrowser) #76126 lignes nettoyées environ 30
unique(gaPVAllYearsCleanBrowser$browser)
plyr::count(as.factor(gaPVAllYearsCleanBrowser$browser))
#creation de la dataframe daily_data par jour
dfDatePV <- as.data.frame(gaPVAllYearsCleanBrowser$date)
colnames(dfDatePV)[1] <- "date" #change le nom de la colonne.
daily_data <- dfDatePV %>% #daily_data à partir de dfDatePV
group_by(date) %>% #groupement par date
mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date
as.data.frame() %>% #sur d'avoir une data.frame
unique() %>% #ligne unique par jour.
mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours)
mutate(year = format(date,"%Y")) #creation de la variable year
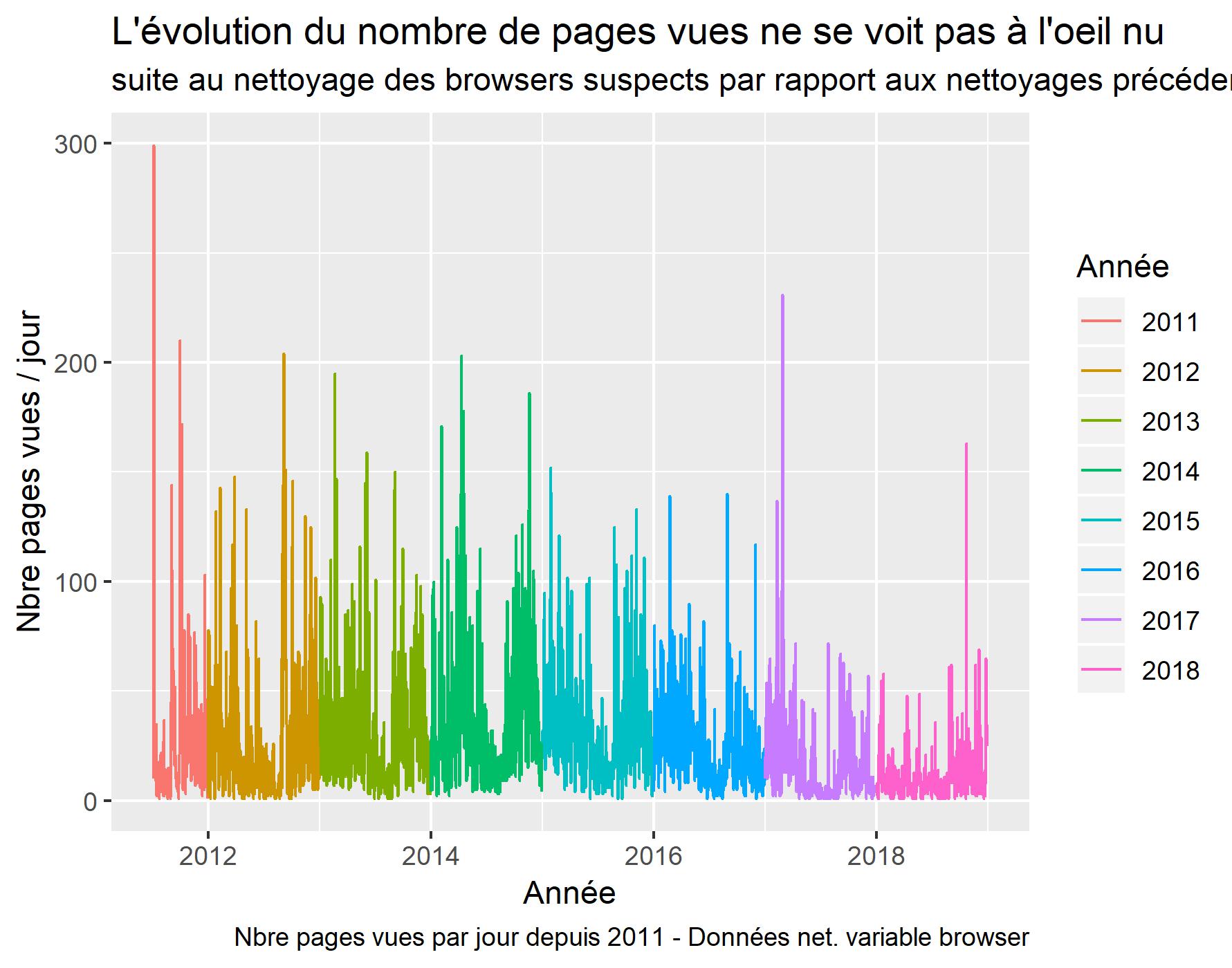
il reste 76126 observations. Ici uniquement une trentaine de repérés.
Visualisation dES pages vues suite au nettoyage des browsers suspects
#Graphique pages vues par jour
ggplot(daily_data , aes(x=date, y=Pageviews, color=year)) +
geom_line() +
xlab("Année") +
ylab("Nbre pages vues / jour") +
labs(title = "L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ",
subtitle = "suite au nettoyage des browsers suspects par rapport aux nettoyages précédents.",
caption = "Nbre pages vues par jour depuis 2011 - Données net. variable browser",
color = "Année")
#sauvegarde du dernier ggplot.
ggsave(filename = "PV-s2011-Clean-Browser.jpeg", dpi="print") #sauvegarde du dernier ggplot.
Nettoyage des Crawlers Spammers et autres sources de trafic non désirées dans source.
Pour effectuer cette opération vous aurez besoin du fichier « blacklist-source-sites.csv » qui regroupe de nombreux spammeurs. vous pouvez le récupérer sur notre Github à l’adresse
https://github.com/Anakeyn/blacksites/archive/master.zip
Le fichier zip comprend aussi un fichier en.xlsx mais celui-ci sert pour le nettoyage « à la main » via les segments. Dézipper et recopier le fichier « blacklist-source-sites.csv » dans le répertoire courant de votre fichier R
Pour des raisons de mémoire on ne peut pas construire une pattern qui comprend tous les sites à exclure. C’est pourquoi on fait une boucle pour faire une recherche par paquets de 500. Ajustez le paramètre « step » selon vos besoins.
##########################################################################
#nettoyage des Crawlers Spammers et autres sources de trafic non désirées
#dans source
##########################################################################
gaPVAllYearsCleanSource <- gaPVAllYearsCleanBrowser
#la liste des sites et mots clés non désirés est dans un fichier que
#nous avons créé.
patternsBadSource <- read.csv("blacklist-source-sites.csv", header=TRUE)
head(patternsBadSource)
#pour des raisons de mémoire on est obligé de faire une boucle avec des paquets de pattern.
blacklistSourceSitesPacks <- vector()
step <- 500
steps <- seq(1, length(patternsBadSource$blacksites) , by=step)
#steps <- 1 #pour faire des tests
j <- 1
for (i in steps) {
if ( i+step < length(patternsBadSource$blacksites)) {
iMax <-i+step
}
else {
iMax <- length(patternsBadSource$blacksites)
}
patternBadSourcePack <- paste(paste(patternsBadSource$blacksites[i:iMax], collapse="|"))
write.table(patternBadSourcePack, file = stri_replace_all_fixed(paste("blacklist-sites-",j,".txt"), " ", ""), row.names = FALSE, col.names=FALSE)
str(patternBadSourcePack)
cat("Pattern", patternBadSourcePack, "\n")
blacklistSourceSitesPacks[j] <- patternBadSourcePack #pour sauvegarde
cat("j:", j, "\n")
#grep ne déecte pas tout, notamment les nombres en notation scientifique planqués
#dans les chaines de caractères : préférer stri_detect_regex
#indexBadSource <- -grep(pattern = as.character(patternBadSourcePack), format(gaPVAllYearsCleanSource$source, scientific=FALSE))
#cat("trouvés:", indexBadSource, "\n")
indexBadSource <- -which(stri_detect_regex(format(gaPVAllYearsCleanSource$source, scientific=FALSE), as.character(patternBadSourcePack)))
cat("trouvés avec stri_detect :", indexBadSource, "\n")
if (length(indexBadSource) > 0) gaPVAllYearsCleanSource <- gaPVAllYearsCleanSource[indexBadSource,]
j <- j+1
}
#verif de ce que l'on a :
head(plyr::count(as.factor((gaPVAllYearsCleanSource$source))))
#Verifs
nrow(gaPVAllYearsCleanSource) #74275 lignes nettoyées environ 1850
#creation de la dataframe daily_data par jour
dfDatePV <- as.data.frame(gaPVAllYearsCleanSource$date)
colnames(dfDatePV)[1] <- "date" #change le nom de la colonne.
daily_data <- dfDatePV %>% #daily_data à partir de dfDatePV
group_by(date) %>% #groupement par date
mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date
as.data.frame() %>% #sur d'avoir une data.frame
unique() %>% #ligne unique par jour.
mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours)
mutate(year = format(date,"%Y")) #creation de la variable year
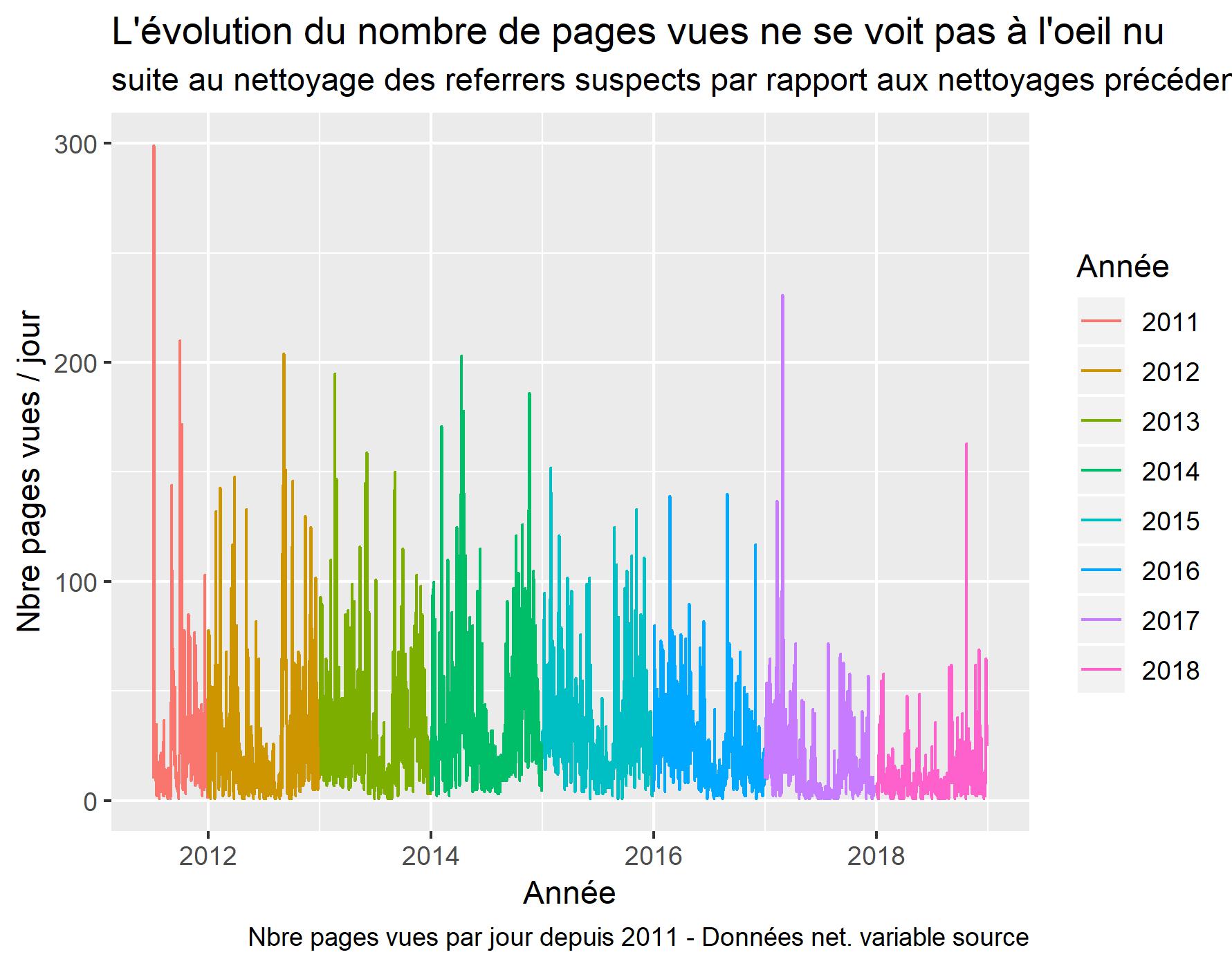
Nous avons maintenant 74275 observations. Environ 1850 ont été écartées.
ViSUALISATION SUITE au nettoyage des crawlers spammers
Nettoyage des fausses pages référentes dans fullReferrer
Il s’agit ici de fausses pages référentes mais sur des sites légitimes. Nous avons créé un liste dans un fichier « blacklist-fullRefferer-Page.csv » que vous pouvez aussi récupérer dans le fichier .zip précédent.
##########################################################################
#nettoyage des fausses pages référentes dans fullReferrer
##########################################################################
gaPVAllYearsCleanFullReferrer <- gaPVAllYearsCleanSource
patternsBadFullReferrer <- read.csv("blacklist-fullRefferer-Page.csv", header=TRUE)
indexBadFullReferrer <- -grep(pattern = paste(patternsBadFullReferrer$Blackpages, collapse="|"), gaPVAllYearsCleanFullReferrer$fullReferrer)
gaPVAllYearsCleanFullReferrer <- gaPVAllYearsCleanFullReferrer[indexBadFullReferrer,]
#Verifs
nrow(gaPVAllYearsCleanFullReferrer) #73829 lignes nettoyées environ 450
#creation de la dataframe daily_data par jour
dfDatePV <- as.data.frame(gaPVAllYearsCleanFullReferrer$date)
colnames(dfDatePV)[1] <- "date" #change le nom de la colonne.
daily_data <- dfDatePV %>% #daily_data à partir de dfDatePV
group_by(date) %>% #groupement par date
mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date
as.data.frame() %>% #sur d'avoir une data.frame
unique() %>% #ligne unique par jour.
mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours)
mutate(year = format(date,"%Y")) #creation de la variable year
Nous avons maintenant 73829 observations. Environ 450 ont été trouvées avec cette méthode.
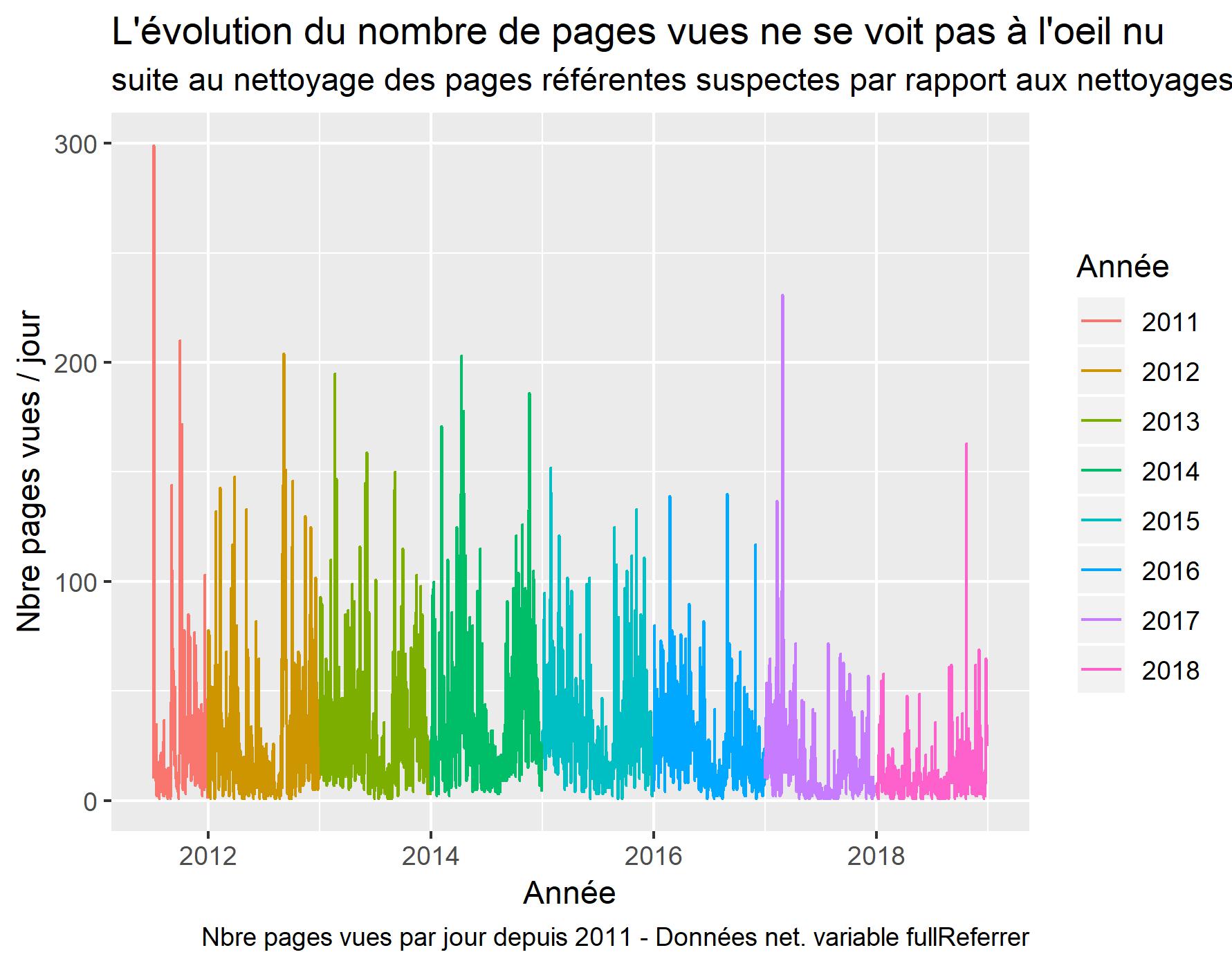
VisUAlisation DES PAGES VUES SUITE AU NETTOYAGE DES PAGES REFERENTES SUSPECTES
#Graphique pages vues par jour
ggplot(daily_data , aes(x=date, y=Pageviews, color=year)) +
geom_line() +
xlab("Année") +
ylab("Nbre pages vues / jour") +
labs(title = "L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ",
subtitle = "suite au nettoyage des pages référentes suspectes par rapport aux nettoyages précédents.",
caption = "Nbre pages vues par jour depuis 2011 - Données net. variable fullReferrer",
color = "Année")
#sauvegarde du dernier ggplot.
ggsave(filename = "PV-s2011-Clean-FullReferrer.jpeg", dpi="print")
Nettoyage des pages d’administration
Il s’agit ici des pages d’administration du site qui n’ont pas vocation à être comptés. Attention ces pages dépendent de votre CMS (Content Management System). Pour nous il s’agit de WordPress.
##########################################################################
#nettoyage des pages d'administration dans pagePath
##########################################################################
gaPVAllYearsCleanPagePath <- gaPVAllYearsCleanFullReferrer
patternBadPagePath <- c("/wp-login\\.php", "/wp-admin/", "/cron/", "/?p=\\d")
indexBadPagePath <- -grep(pattern = paste(patternBadPagePath, collapse="|"), gaPVAllYearsCleanPagePath$pagePath)
gaPVAllYearsCleanPagePath <- gaPVAllYearsCleanPagePath [indexBadPagePath,]
#verifs
nrow(gaPVAllYearsCleanPagePath) #73301 environ 530 lignes de nettoyées.
summary(gaPVAllYearsCleanPagePath$pagePath) #verif
#creation de la dataframe daily_data par jour
dfDatePV <- as.data.frame(gaPVAllYearsCleanPagePath$date)
colnames(dfDatePV)[1] <- "date" #change le nom de la colonne.
daily_data <- dfDatePV %>% #daily_data à partir de dfDatePV
group_by(date) %>% #groupement par date
mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date
as.data.frame() %>% #sur d'avoir une data.frame
unique() %>% #ligne unique par jour.
mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours)
mutate(year = format(date,"%Y")) #creation de la variable year
Il reste 73301 observations. Cette partie en a repéré environ 530 lignes.
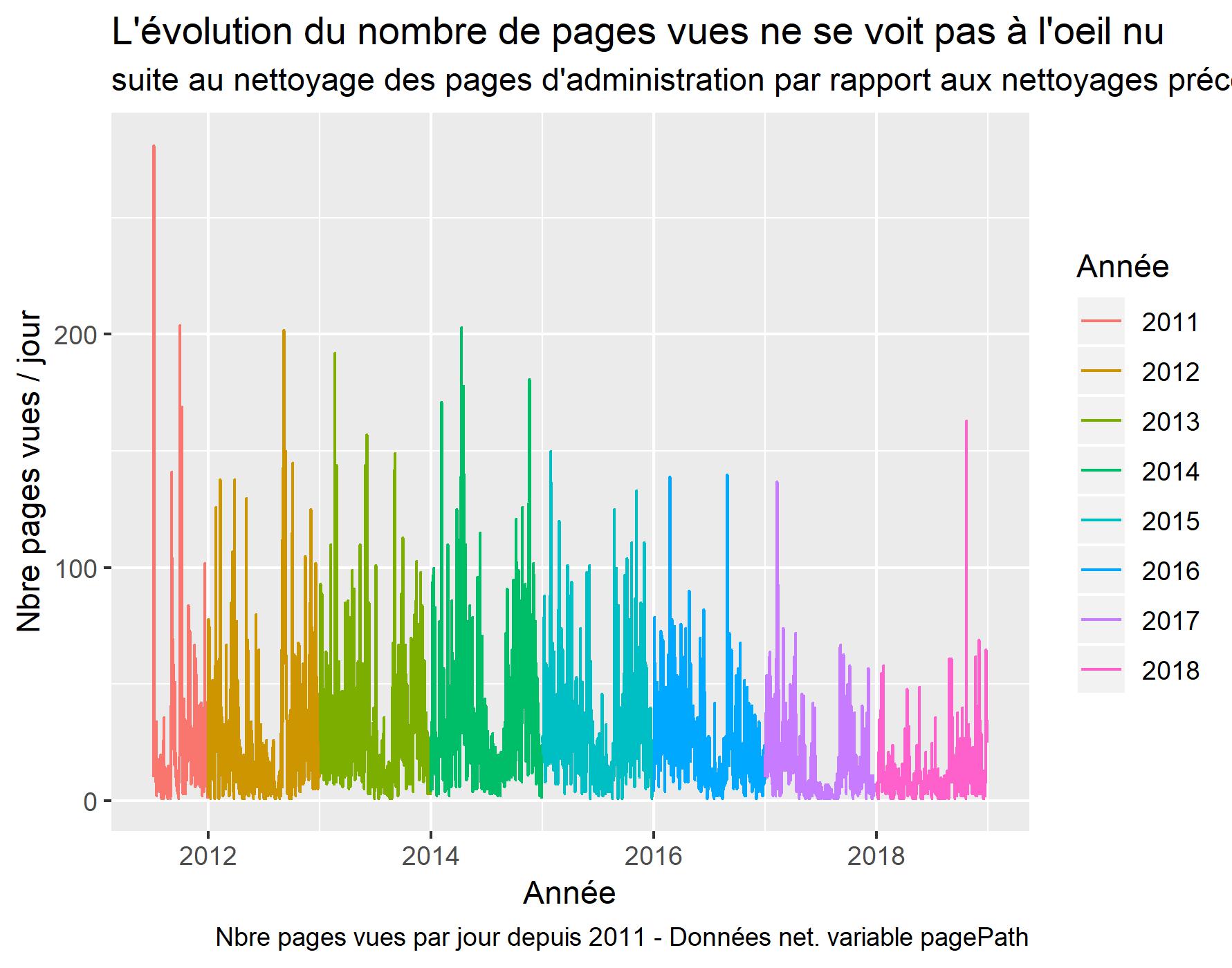
Visualisation suite à la suppression des pages d’administration.
#Graphique pages vues par jour
ggplot(daily_data , aes(x=date, y=Pageviews, color=year)) +
geom_line() +
xlab("Année") +
ylab("Nbre pages vues / jour") +
labs(title = "L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ",
subtitle = "suite au nettoyage des pages d'administration par rapport aux nettoyages précédents.",
caption = "Nbre pages vues par jour depuis 2011 - Données net. variable pagePath",
color = "Année")
ggsave(filename = "PV-s2011-Clean-PagePath.jpeg", dpi="print") #sauvegarde du dernier ggplot.
Nettoyage des pages dont l’entrée sur le site s’est faite via l’administration, variable landingPagePath
Comme précédemment, la liste des pages dépend de votre CMS. pour nous il s’agit de WordPress.
##########################################################################
#nettoyage des pages dont l'entrée sur le site s'est faite
#via l'administration, variable landingPagePath
##########################################################################
gaPVAllYearsCleanLandingPagePath <- gaPVAllYearsCleanPagePath
patternBadLandingPagePath <- c("/wp-login\\.php", "/wp-admin/", "/cron/", "/?p=\\d")
indexBadLandingPagePath <- -grep(pattern = paste(patternBadLandingPagePath, collapse="|"), gaPVAllYearsCleanLandingPagePath$landingPagePath)
gaPVAllYearsCleanLandingPagePath <- gaPVAllYearsCleanLandingPagePath [indexBadLandingPagePath,]
#verifs
nrow(gaPVAllYearsCleanLandingPagePath) #72822 environ 500 lignes de nettoyées.
summary(gaPVAllYearsCleanLandingPagePath$landingPagePath) #verif
#creation de la dataframe daily_data par jour
dfDatePV <- as.data.frame(gaPVAllYearsCleanLandingPagePath$date)
colnames(dfDatePV)[1] <- "date" #change le nom de la colonne.
daily_data <- dfDatePV %>% #daily_data à partir de dfDatePV
group_by(date) %>% #groupement par date
mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date
as.data.frame() %>% #sur d'avoir une data.frame
unique() %>% #ligne unique par jour.
mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours)
mutate(year = format(date,"%Y")) #creation de la variable year
Il reste 72822 observations. Environ 500 lignes ont été trouvées durant cette dernière étape.
Visualisation des pages vues nettoyées.
#Graphique pages vues par jour
ggplot(daily_data , aes(x=date, y=Pageviews, color=year)) +
geom_line() +
xlab("Année") +
ylab("Nbre pages vues / jour") +
labs(title = "Le maximum de pages vues par jour est maintenant autour de 200 (vs 300) ",
subtitle = "suite au nettoyage des pages d'administration référentes \n par rapport aux nettoyages précédents.",
caption = "Nbre pages vues par jour depuis 2011 - Données net. variable landingPagePath",
color = "Année")
ggsave(filename = "PV-s2011-Clean-LandingPagePath.jpeg", dpi="print") #sauvegarde du dernier ggplot.
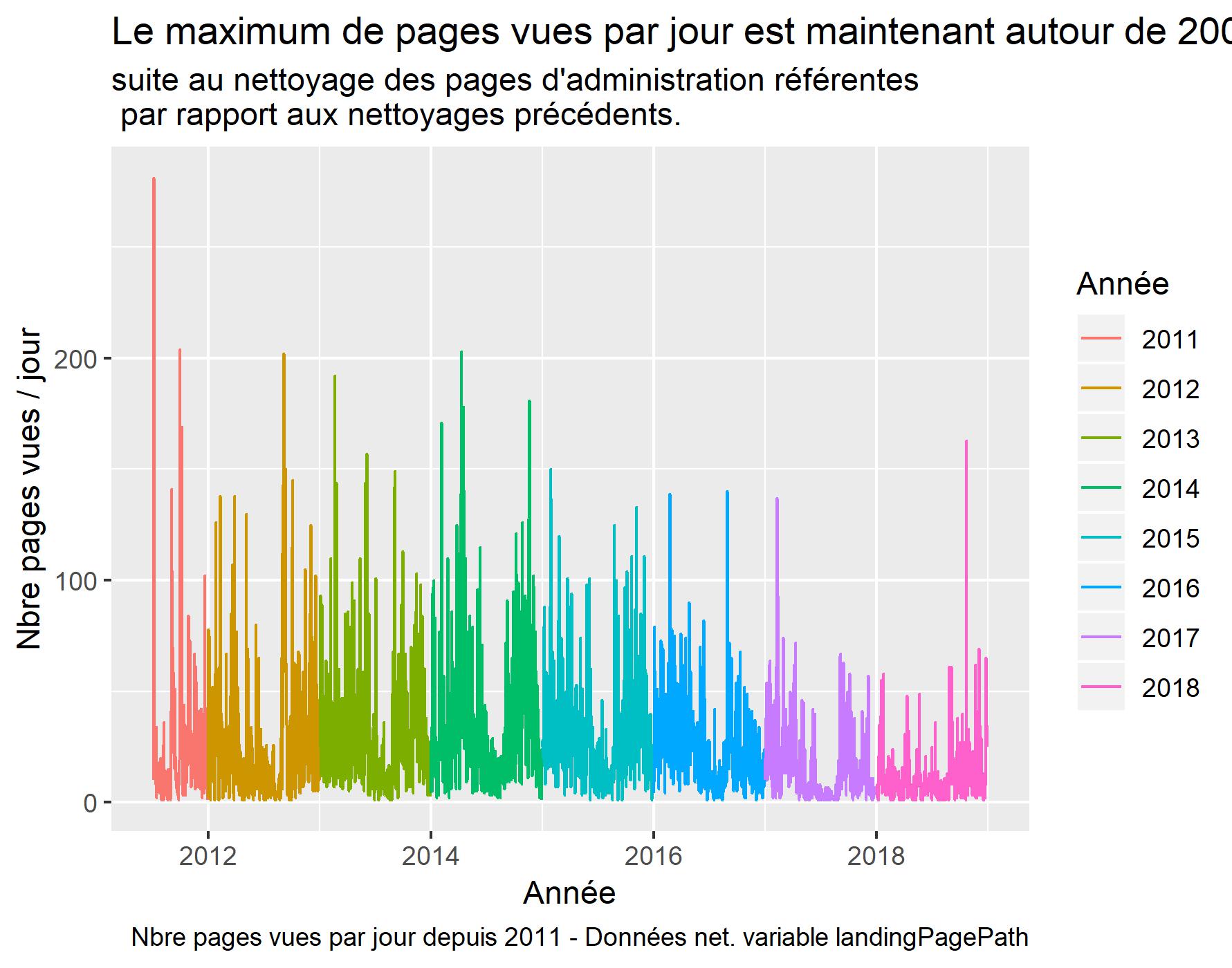
Au départ nous avions 82559 observation et après nettoyage 72821, ce qui fait près de 10000 et environ 15% du total ce qui n’est pas négligeable !!!
Comparatifs des années sur le jeu de données nettoyée
Pour finir nous allons comparer les différents trafics selon les années sur le même graphique. Nous en profiterons aussi pour sauvegarder nos données dans un fichier dfPageViews.csv que nous pourrons réutiliser par la suite pour d’autres investigations.
##########################################################################
# Jeu de données nettoyé
##########################################################################
#install.packages("lubridate") #si vous ne l'avez pas
library (lubridate) #pour yday
#nom de sauvegarde plus facile à retenir :
dfPageViews <- gaPVAllYearsCleanLandingPagePath
#Sauvegarde pour SAS si besoin. Bon c'est le même que le précédent ...
#sauvegarde en csv avec ;
write.csv2(dfPageViews, file = "dfPageViews.csv", row.names=FALSE)
#visualisation comparatif des années
dfDatePV <- as.data.frame(dfPageViews$date)
colnames(dfDatePV)[1] <- "date"
daily_data <- dfDatePV %>% #daily_data à partir de dfDatePV
group_by(date) %>% #groupement par date
mutate(Pageviews = n()) %>% #total des pageviews = nombre d'observations / date
as.data.frame() %>% #sur d'avoir une data.frame
unique() %>% #ligne unique par jour.
mutate(cnt_ma30 = ma(Pageviews, order=30)) %>% #variable moyenne mobile (moving average 30 jours)
mutate(year = format(date,"%Y")) %>% #creation de la variable year
mutate(dayOfYear = yday(date)) #creation de la variable dayOfYear
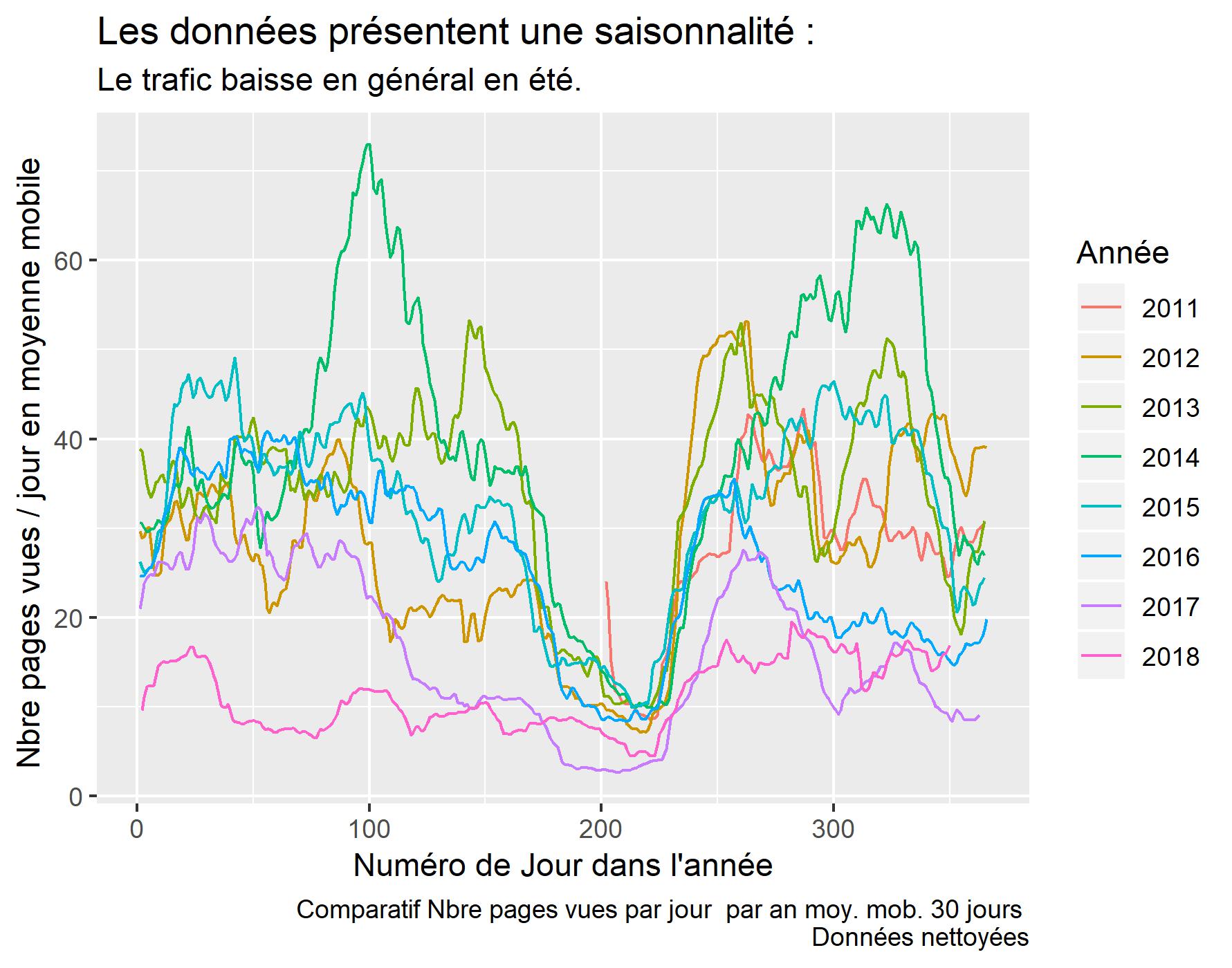
#comparatifs 2011 - 2018
ggplot() +
geom_line(data = daily_data, aes(x = dayOfYear, y = cnt_ma30, col=year)) +
xlab("Numéro de Jour dans l'année") +
ylab("Nbre pages vues / jour en moyenne mobile ") +
labs(title = "Les données présentent une saisonnalité : ",
subtitle = "Le trafic baisse en général en été.",
caption = "Comparatif Nbre pages vues par jour par an moy. mob. 30 jours \n Données nettoyées",
color = "Année")
#sauvegarde du dernier ggplot.
ggsave(filename = "PV-Comparatif-mm30.jpeg", dpi="print")
Merci pour votre attention. Nous prévoyons de reprendre cet article en Python. Par ailleurs les données nettoyées du site serons utilisées dans des articles futurs pour quelques exemples d’investigations.
Vous pouvez retrouver le code source en entier ainsi que les fichiers nécessaires sur notre Github à l’adresse https://github.com/Anakeyn/CleanSpamGAwR
N’hésitez pas à laisser vos avis, conseils etc en commentaires,
A Bientôt,
Pierre